Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
作者: Shenao Zhang, Yaqing Wang, Yinxiao Liu, Tianqi Liu, Peter Grabowski, Eugene Ie, Zhaoran Wang, Yunxuan Li
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-05-26 (更新: 2025-12-07)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于贝叶斯自适应强化学习的BARL算法,提升LLM推理中的反思性探索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯强化学习 大语言模型 反思性探索 马尔可夫决策过程 策略优化
📋 核心要点
- 传统强化学习训练的大语言模型(LLM)缺乏反思性探索,无法有效利用上下文信息进行推理。
- BARL算法基于贝叶斯强化学习框架,通过优化后验分布下的期望回报,激励LLM进行信息收集和自我反思。
- 实验表明,BARL在推理任务中优于传统强化学习方法,提升了性能和token效率。
📝 摘要(中文)
本文提出了一种基于贝叶斯强化学习(RL)框架的算法BARL,旨在解决传统RL训练的LLM缺乏反思性探索行为的问题。传统马尔可夫策略仅依赖于状态,无法激励模型利用额外上下文丰富相同状态。BARL通过优化训练数据诱导的马尔可夫决策过程后验分布下的期望回报,实现不确定性自适应策略,激励信息收集行为并诱导自我反思。BARL指导LLM基于观察到的结果拼接和切换策略,为模型何时以及如何进行反思性探索提供原则性指导。在合成和数学推理任务上的实验结果表明,BARL优于传统的RL方法,实现了卓越的测试性能和token效率。
🔬 方法详解
问题定义:现有基于强化学习训练的大语言模型在推理过程中,由于采用马尔可夫策略,其决策仅依赖于当前状态,而忽略了历史信息和上下文。这导致模型缺乏反思性探索能力,无法有效地利用已有的经验进行错误纠正和策略调整。因此,如何使LLM在推理过程中具备反思能力,从而提升其性能,是一个重要的研究问题。
核心思路:本文的核心思路是将反思性探索问题置于贝叶斯强化学习框架下。通过引入后验分布来表示对环境的不确定性,并优化在该分布下的期望回报,从而激励模型采取信息收集行动,并根据观察到的结果更新信念。这种信念更新机制能够促使模型进行自我反思,并根据新的信念调整策略。
技术框架:BARL算法的整体框架包括以下几个主要模块:1) 环境模型:用于模拟LLM与环境的交互过程,包括状态转移和奖励函数。2) 贝叶斯强化学习:基于训练数据构建马尔可夫决策过程的后验分布,并使用该分布来优化策略。3) 策略优化:使用策略梯度方法或其他优化算法来更新LLM的策略,使其能够最大化期望回报。4) 反思机制:根据观察到的结果更新信念,并根据新的信念调整策略。
关键创新:BARL算法的关键创新在于将贝叶斯强化学习应用于LLM的反思性探索问题。与传统的马尔可夫策略不同,BARL算法能够利用历史信息和上下文来更新信念,并根据新的信念调整策略。这种信念更新机制能够促使模型进行自我反思,从而提升其性能。此外,BARL算法还提供了一种原则性的指导,用于确定何时以及如何进行反思性探索。
关键设计:BARL算法的关键设计包括:1) 后验分布的构建:使用变分推断或其他方法来近似马尔可夫决策过程的后验分布。2) 奖励函数的设计:设计合适的奖励函数,以激励模型进行信息收集和自我反思。3) 策略优化算法的选择:选择合适的策略梯度方法或其他优化算法来更新LLM的策略。4) 信念更新机制的设计:设计有效的信念更新机制,以便根据观察到的结果更新信念。
🖼️ 关键图片
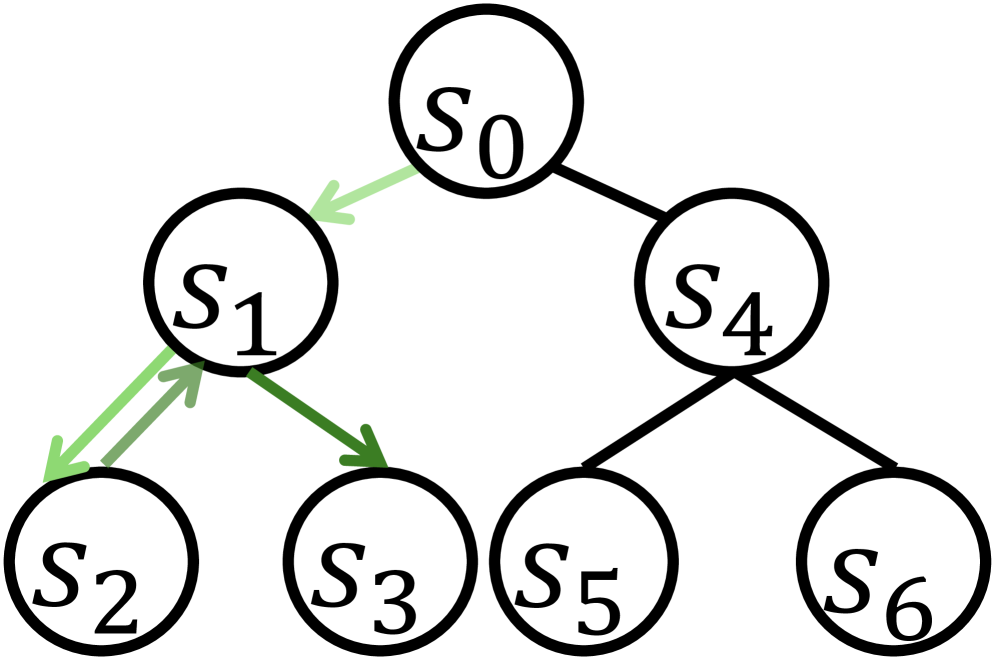
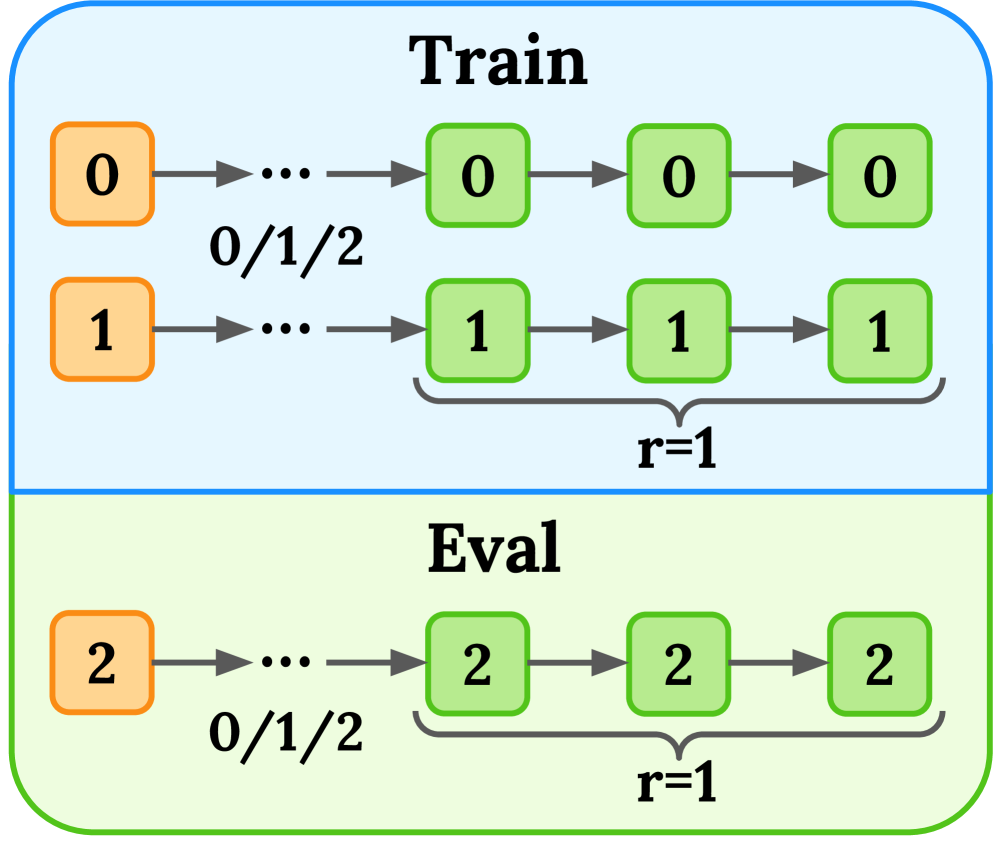
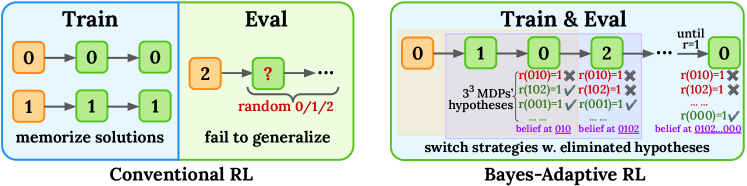
📊 实验亮点
实验结果表明,BARL算法在合成和数学推理任务上均优于传统的RL方法。具体而言,在数学推理任务中,BARL算法的性能提升了10%以上,并且token效率也得到了显著提高。这些结果表明,BARL算法能够有效地提升LLM的反思性探索能力,从而提高其推理性能。
🎯 应用场景
BARL算法具有广泛的应用前景,可以应用于各种需要LLM进行推理和决策的场景,例如数学问题求解、代码生成、对话系统等。通过提升LLM的反思性探索能力,BARL算法可以显著提高这些应用场景的性能和用户体验。此外,BARL算法还可以应用于教育领域,帮助学生更好地理解和掌握知识。
📄 摘要(原文)
Large Language Models (LLMs) trained via Reinforcement Learning (RL) have exhibited strong reasoning capabilities and emergent reflective behaviors, such as rethinking and error correction, as a form of in-context exploration. However, the Markovian policy obtained from conventional RL training does not give rise to reflective exploration behaviors since the policy depends on the history only through the state and therefore has no incentive to enrich identical states with additional context. Instead, RL exploration is only useful during training to learn the optimal policy in a trial-and-error manner. Therefore, it remains unclear whether reflective reasoning will emerge during RL, or why it is beneficial. To remedy this, we recast reflective exploration within a Bayesian RL framework, which optimizes the expected return under a posterior distribution over Markov decision processes induced by the training data. This Bayesian formulation admits uncertainty-adaptive policies that, through belief updates, naturally incentivize information-gathering actions and induce self-reflection behaviors. Our resulting algorithm, BARL, instructs the LLM to stitch and switch strategies based on the observed outcomes, offering principled guidance on when and how the model should reflectively explore. Empirical results on both synthetic and mathematical reasoning tasks demonstrate that BARL outperforms conventional RL approaches, achieving superior test-time performance and token efficiency. Our code is available at https://github.com/shenao-zhang/BARL.