The Shape of Adversarial Influence: Characterizing LLM Latent Spaces with Persistent Homology
作者: Aideen Fay, Inés García-Redondo, Qiquan Wang, Haim Dubossarsky, Anthea Monod
分类: cs.LG, cs.AI, cs.CG, math.AT
发布日期: 2025-05-26 (更新: 2025-10-09)
💡 一句话要点
利用持续同调分析LLM隐空间,揭示对抗攻击的影响模式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对抗攻击 持续同调 拓扑数据分析 模型可解释性
📋 核心要点
- 现有LLM可解释性方法难以捕捉高维、非线性的模型内部表征。
- 利用拓扑数据分析中的持续同调,分析对抗攻击对LLM隐空间的影响。
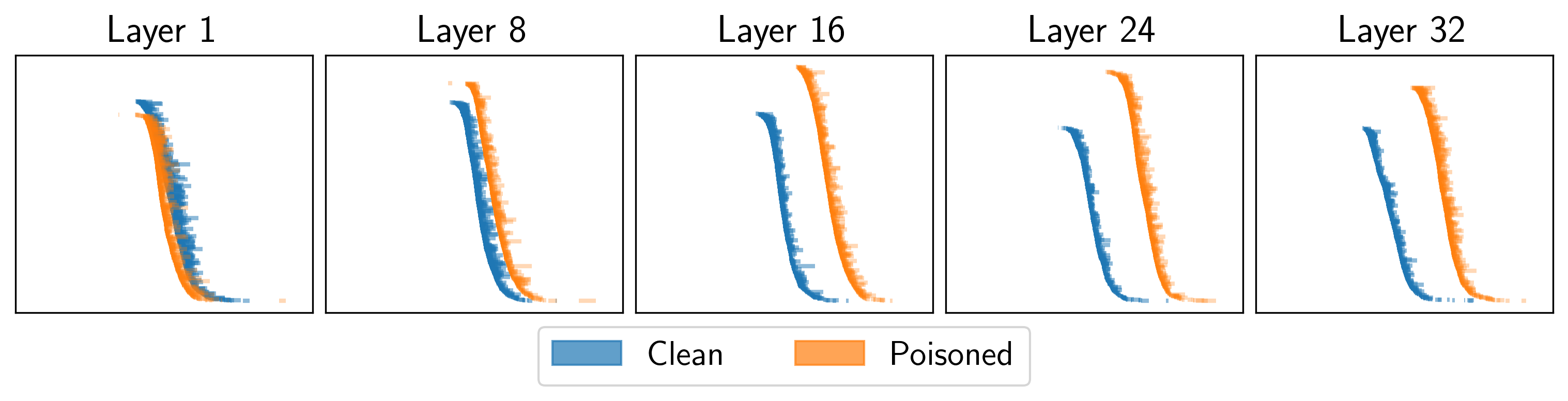
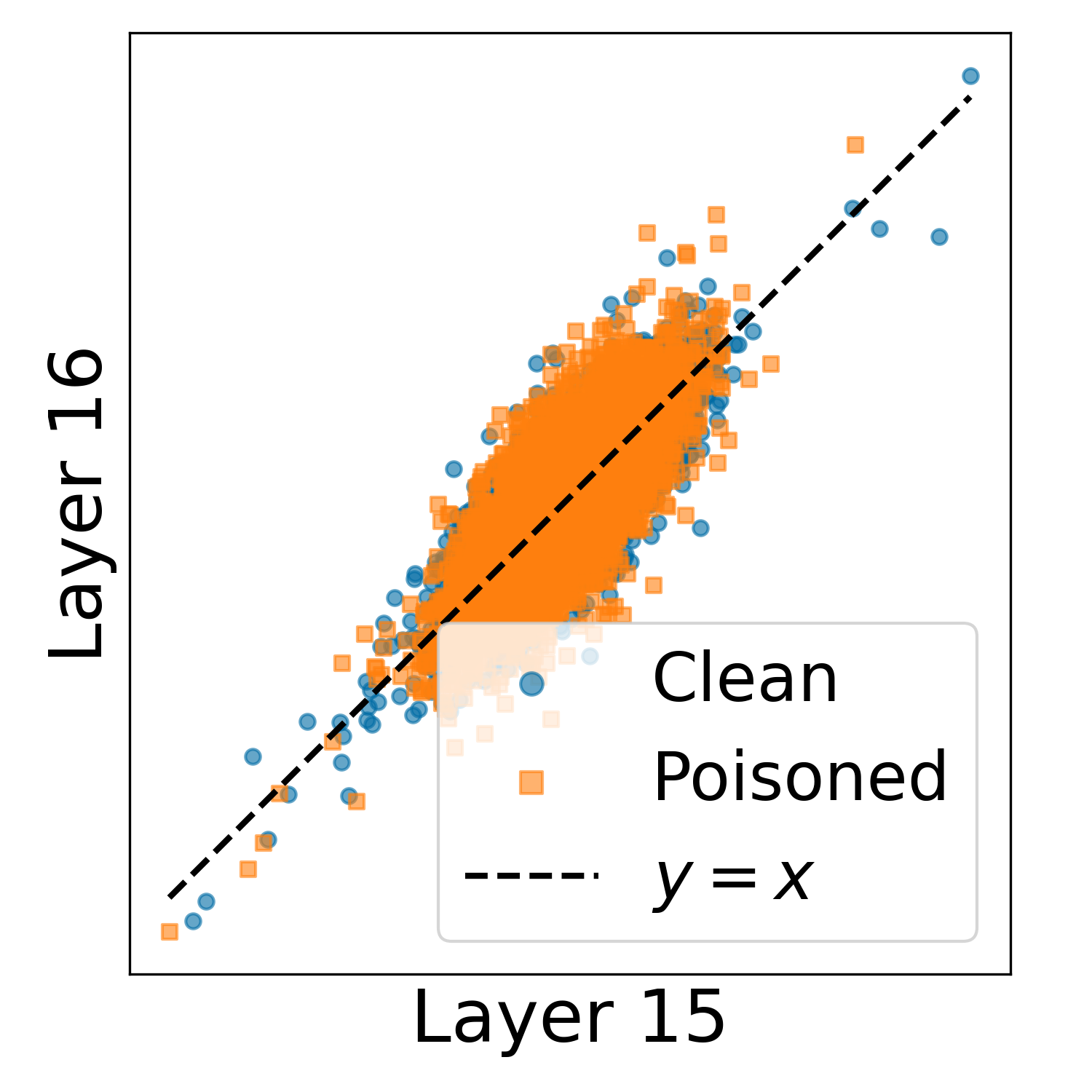
- 发现对抗攻击导致“拓扑压缩”,隐空间结构简化,特征由小变大。
📝 摘要(中文)
现有的大语言模型(LLM)可解释性方法通常侧重于线性方向或孤立特征,忽略了模型表征中高维、非线性和关系几何。本研究关注对抗性输入如何系统地影响LLM的内部表征空间,这是一个尚未被充分理解的领域。我们提出使用持续同调(PH),一种来自拓扑数据分析的工具,作为一个原则性框架来描述LLM激活中的多尺度动态。通过PH,我们系统地分析了六个最先进的模型在两种不同的对抗条件下(间接提示注入和后门微调),并识别出对抗性影响的一致拓扑特征。在不同的架构和模型尺寸中,对抗性输入会引起“拓扑压缩”,其中潜在空间在结构上变得更简单,从各种紧凑的小规模特征坍缩为更少、更占主导地位和更分散的大规模特征。这种拓扑特征在各层之间具有统计鲁棒性、高度区分性,并为对抗性效应如何出现和传播提供了可解释的见解。通过量化激活的形状和神经元信息流,我们这种与架构无关的框架揭示了表征变化的基本不变性,为现有的可解释性方法提供了一个补充视角。
🔬 方法详解
问题定义:论文旨在解决现有LLM可解释性方法无法有效理解对抗攻击如何影响模型内部表征空间的问题。现有方法通常侧重于线性关系或孤立的神经元,忽略了模型表征的高维、非线性和关系几何特性,因此难以捕捉对抗攻击的复杂影响。
核心思路:论文的核心思路是利用持续同调(Persistent Homology, PH)来分析LLM在受到对抗攻击时的激活模式。PH是一种拓扑数据分析工具,可以捕捉数据在不同尺度下的拓扑特征,从而揭示数据潜在的结构信息。通过分析LLM激活的拓扑结构,可以更好地理解对抗攻击如何改变模型的内部表征。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择LLM模型和对抗攻击方法(间接提示注入和后门微调);2) 使用对抗攻击生成对抗样本;3) 将原始样本和对抗样本输入LLM,提取各层的激活值;4) 使用持续同调分析激活值的拓扑结构,计算不同尺度下的同调群;5) 分析同调群的变化,识别对抗攻击引起的拓扑特征变化。
关键创新:论文的关键创新在于将持续同调应用于分析LLM的内部表征空间,并揭示了对抗攻击引起的“拓扑压缩”现象。这种方法提供了一种新的视角来理解对抗攻击对LLM的影响,并为开发更鲁棒的LLM提供了新的思路。与现有方法相比,该方法能够捕捉高维、非线性的关系,从而更全面地理解模型内部的复杂动态。
关键设计:论文的关键设计包括:1) 选择合适的LLM模型和对抗攻击方法,以保证实验的有效性;2) 使用合适的参数设置进行持续同调分析,例如选择合适的距离度量和尺度范围;3) 设计合理的指标来量化拓扑压缩的程度,例如计算不同尺度下的同调群的维数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,对抗性输入在不同的LLM架构和模型尺寸中都会引起一致的“拓扑压缩”现象。这种拓扑特征在各层之间具有统计鲁棒性,并且能够有效区分对抗样本和原始样本。例如,通过分析同调群的维数,可以准确地识别出受到对抗攻击的样本,从而实现对抗攻击检测。
🎯 应用场景
该研究成果可应用于提升LLM的鲁棒性和安全性,例如开发对抗攻击检测方法、设计更鲁棒的模型架构、以及改进模型的训练策略。此外,该方法还可以用于分析其他类型的模型和数据,例如图像分类模型和时间序列数据,从而更全面地理解模型的内部工作机制。
📄 摘要(原文)
Existing interpretability methods for Large Language Models (LLMs) often fall short by focusing on linear directions or isolated features, overlooking the high-dimensional, nonlinear, and relational geometry within model representations. This study focuses on how adversarial inputs systematically affect the internal representation spaces of LLMs, a topic which remains poorly understood. We propose persistent homology (PH), a tool from topological data analysis, as a principled framework to characterize the multi-scale dynamics within LLM activations. Using PH, we systematically analyze six state-of-the-art models under two distinct adversarial conditions, indirect prompt injection and backdoor fine-tuning, and identify a consistent topological signature of adversarial influence. Across architectures and model sizes, adversarial inputs induce ``topological compression'', where the latent space becomes structurally simpler, collapsing from varied, compact, small-scale features into fewer, dominant, and more dispersed large-scale ones. This topological signature is statistically robust across layers, highly discriminative, and provides interpretable insights into how adversarial effects emerge and propagate. By quantifying the shape of activations and neuronal information flow, our architecture-agnostic framework reveals fundamental invariants of representational change, offering a complementary perspective to existing interpretability methods.