Characterizing Pattern Matching and Its Limits on Compositional Task Structures
作者: Hoyeon Chang, Jinho Park, Hanseul Cho, Sohee Yang, Miyoung Ko, Hyeonbin Hwang, Seungpil Won, Dohaeng Lee, Youbin Ahn, Minjoon Seo
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-26 (更新: 2025-11-26)
💡 一句话要点
提出模式匹配的形式化框架以解决组合任务中的泛化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模式匹配 组合任务 大型语言模型 功能等价性 路径模糊性 样本复杂度 自然语言处理 模型泛化
📋 核心要点
- 现有研究未能清晰界定LLMs在组合任务中的模式匹配能力及其局限性,导致泛化性能的理解模糊。
- 本文通过将模式匹配形式化为功能等价性,系统研究了LLMs在控制任务中的表现,揭示其泛化机制。
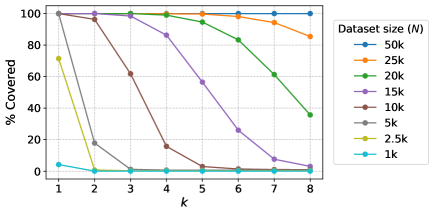
- 实验结果表明,模式匹配的实例成功率与见证功能等价性的上下文数量密切相关,并提供了样本复杂度的理论界限。
📝 摘要(中文)
尽管大型语言模型(LLMs)展现出令人印象深刻的能力,但其成功往往依赖于模式匹配行为,这与组合任务中的超出分布(OOD)泛化失败相关。现有的行为研究通常采用允许多种泛化来源的任务设置,模糊了LLMs通过模式匹配进行泛化的精确表现和局限性。为了解决这一模糊性,本文首先将模式匹配形式化为功能等价性,即识别输入的子序列对,在其余输入保持不变时,始终导致相同结果。然后,我们系统研究了仅解码器的Transformer和Mamba在控制任务中的表现,这些任务具有隔离该机制的组合结构。我们的形式化方法提供了预测性和定量的见解。
🔬 方法详解
问题定义:本文旨在解决LLMs在组合任务中模式匹配的表现及其局限性,现有方法未能明确区分不同泛化来源对模型性能的影响。
核心思路:通过将模式匹配形式化为功能等价性,本文提供了一种系统化的方法来评估LLMs在组合任务中的表现,强调了上下文对模式匹配成功的影响。
技术框架:研究采用控制任务设计,使用仅解码器的Transformer和Mamba模型,重点分析模型在不同组合结构下的表现,分离出模式匹配机制。
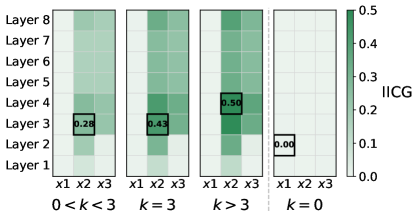
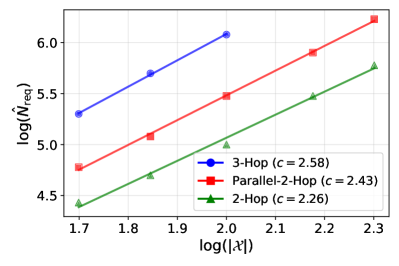
关键创新:本文首次将模式匹配形式化为功能等价性,并提供了关于样本复杂度的理论界限,揭示了路径模糊性对模型性能的影响。
关键设计:研究中采用了20倍参数扩展的实验设置,分析了不同架构下的模型表现,并探讨了链式思维对数据需求的影响。
🖼️ 关键图片
📊 实验亮点
实验结果显示,模式匹配的实例成功率与功能等价性上下文数量呈正相关,且在20倍参数扩展下,模型的表现与理论预测一致。此外,研究揭示了路径模糊性作为结构性障碍,影响了模型的准确性和可解释性。
🎯 应用场景
该研究为理解和改进大型语言模型在组合任务中的泛化能力提供了理论基础,潜在应用包括自然语言处理、机器人控制和复杂决策系统等领域。通过明确模式匹配的局限性,研究可指导未来模型设计和训练策略的优化。
📄 摘要(原文)
Despite impressive capabilities, LLMs' successes often rely on pattern-matching behaviors, yet these are also linked to OOD generalization failures in compositional tasks. However, behavioral studies commonly employ task setups that allow multiple generalization sources (e.g., algebraic invariances, structural repetition), obscuring a precise and testable account of how well LLMs perform generalization through pattern matching and their limitations. To address this ambiguity, we first formalize pattern matching as functional equivalence, i.e., identifying pairs of subsequences of inputs that consistently lead to identical results when the rest of the input is held constant. Then, we systematically study how decoder-only Transformer and Mamba behave in controlled tasks with compositional structures that isolate this mechanism. Our formalism yields predictive and quantitative insights: (1) Instance-wise success of pattern matching is well predicted by the number of contexts witnessing the relevant functional equivalence. (2) We prove a tight sample complexity bound of learning a two-hop structure by identifying the exponent of the data scaling law for perfect in-domain generalization. Our empirical results align with the theoretical prediction, under 20x parameter scaling and across architectures. (3) Path ambiguity is a structural barrier: when a variable influences the output via multiple paths, models fail to form unified intermediate state representations, impairing accuracy and interpretability. (4) Chain-of-Thought reduces data requirements yet does not resolve path ambiguity. Hence, we provide a predictive, falsifiable boundary for pattern matching and a foundational diagnostic for disentangling mixed generalization mechanisms.