DISCOVER: Automated Curricula for Sparse-Reward Reinforcement Learning
作者: Leander Diaz-Bone, Marco Bagatella, Jonas Hübotter, Andreas Krause
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-05-26 (更新: 2025-10-20)
备注: NeurIPS 2025
💡 一句话要点
DISCOVER:面向稀疏奖励强化学习的自动化课程学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 稀疏奖励强化学习 课程学习 目标条件强化学习 探索策略 长时程任务
📋 核心要点
- 现有稀疏奖励强化学习方法难以有效探索高维、长时程任务,因为它们通常以解决多个任务为目标,缺乏针对单个任务的有效探索策略。
- DISCOVER通过选择与目标任务相关的更简单任务作为探索目标,引导智能体学习解决目标任务所需的技能,从而实现有方向的探索。
- 实验结果表明,DISCOVER在解决复杂探索问题方面优于现有方法,能够解决传统RL方法难以处理的稀疏奖励任务。
📝 摘要(中文)
稀疏奖励强化学习(RL)能够建模各种高度复杂的任务。解决稀疏奖励任务是RL的核心前提,需要有效的探索以及长期的信用分配,克服这些挑战是构建具有超人能力的自我改进型智能体的关键。先前的工作通常以解决许多稀疏奖励任务为目标进行探索,使得对单个高维、长时程任务的探索变得难以处理。我们认为,解决这些具有挑战性的任务需要解决与目标任务相关的更简单的任务,即,其实现将教会智能体解决目标任务所需的技能。我们证明,这种方向感,对于有效的探索是必要的,可以从现有的RL算法中提取出来,而无需利用任何先验信息。为此,我们提出了一种有向稀疏奖励目标条件超长时程RL方法(DISCOVER),该方法选择朝向目标任务方向的探索性目标。我们将DISCOVER与bandit中的原则性探索联系起来,在形式上将目标任务变得可实现的时间限制在智能体到目标的初始距离方面,但独立于所有任务空间的体积。然后,我们在高维环境中进行了彻底的评估。我们发现,DISCOVER的有向目标选择解决了RL中先前最先进的探索方法无法解决的探索问题。
🔬 方法详解
问题定义:论文旨在解决稀疏奖励强化学习中,智能体在高维、长时程任务中难以有效探索的问题。现有方法通常缺乏针对特定任务的有效探索策略,导致学习效率低下,难以找到最优策略。尤其是在奖励信号稀疏的情况下,智能体很难发现有价值的经验,从而难以学习。
核心思路:DISCOVER的核心思路是利用课程学习的思想,引导智能体逐步学习解决目标任务。它不是直接探索整个状态空间,而是选择与目标任务相关的更简单的子任务作为探索目标。通过解决这些子任务,智能体可以逐步掌握解决目标任务所需的技能,从而提高探索效率。
技术框架:DISCOVER的整体框架包含以下几个主要模块:1) 目标选择模块:负责选择下一个要探索的目标。该模块会根据当前智能体的状态和目标任务,选择一个与目标任务相关的、难度适中的子任务作为探索目标。2) 策略学习模块:负责学习如何达到选定的目标。该模块可以使用任何现有的强化学习算法,例如SAC、TD3等。3) 奖励函数设计:针对选定的目标,设计相应的奖励函数,引导智能体学习如何达到该目标。
关键创新:DISCOVER的关键创新在于其有方向的目标选择策略。与传统的随机探索或基于好奇心的探索方法不同,DISCOVER会根据目标任务的信息,选择与目标任务相关的子任务作为探索目标。这种有方向的探索策略可以显著提高探索效率,使智能体更快地发现有价值的经验。
关键设计:DISCOVER的关键设计包括:1) 目标选择策略:论文提出了一种基于距离的目标选择策略,该策略会选择与当前状态距离较近、但与目标任务距离较远的状态作为探索目标。2) 奖励函数设计:论文针对不同的子任务,设计了不同的奖励函数,以引导智能体学习如何达到这些子任务。3) 探索策略:论文采用了一种基于高斯噪声的探索策略,以增加探索的多样性。
🖼️ 关键图片
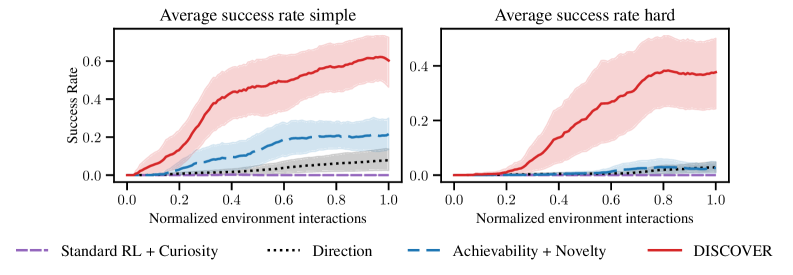

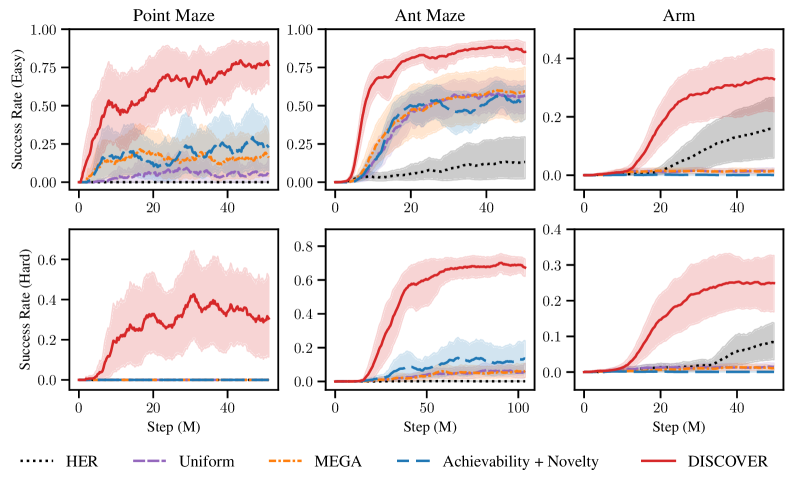
📊 实验亮点
实验结果表明,DISCOVER在多个高维环境中优于现有的探索方法。例如,在某个机器人操作任务中,DISCOVER能够成功解决该任务,而现有的最先进的探索方法则无法解决。此外,DISCOVER还能够显著提高智能体的学习效率,使其更快地达到目标。
🎯 应用场景
DISCOVER方法可以应用于各种需要长期规划和稀疏奖励的复杂任务,例如机器人操作、游戏AI、自动驾驶等。通过引导智能体逐步学习解决目标任务所需的技能,DISCOVER可以显著提高智能体的学习效率和性能,使其能够更好地适应复杂环境。
📄 摘要(原文)
Sparse-reward reinforcement learning (RL) can model a wide range of highly complex tasks. Solving sparse-reward tasks is RL's core premise, requiring efficient exploration coupled with long-horizon credit assignment, and overcoming these challenges is key for building self-improving agents with superhuman ability. Prior work commonly explores with the objective of solving many sparse-reward tasks, making exploration of individual high-dimensional, long-horizon tasks intractable. We argue that solving such challenging tasks requires solving simpler tasks that are relevant to the target task, i.e., whose achieval will teach the agent skills required for solving the target task. We demonstrate that this sense of direction, necessary for effective exploration, can be extracted from existing RL algorithms, without leveraging any prior information. To this end, we propose a method for directed sparse-reward goal-conditioned very long-horizon RL (DISCOVER), which selects exploratory goals in the direction of the target task. We connect DISCOVER to principled exploration in bandits, formally bounding the time until the target task becomes achievable in terms of the agent's initial distance to the target, but independent of the volume of the space of all tasks. We then perform a thorough evaluation in high-dimensional environments. We find that the directed goal selection of DISCOVER solves exploration problems that are beyond the reach of prior state-of-the-art exploration methods in RL.