Understanding the Performance Gap in Preference Learning: A Dichotomy of RLHF and DPO
作者: Ruizhe Shi, Minhak Song, Runlong Zhou, Zihan Zhang, Maryam Fazel, Simon S. Du
分类: cs.LG, cs.CL
发布日期: 2025-05-26 (更新: 2025-10-03)
备注: 30 pages, 5 figures. Improved proofs, and typo fixes
💡 一句话要点
理论分析RLHF与DPO在偏好学习中的性能差距,揭示模型偏差影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 偏好学习 强化学习 人类反馈 模型偏差 理论分析
📋 核心要点
- 现有偏好学习方法RLHF和DPO在不同场景下性能差异显著,缺乏对其根本原因的深入理解。
- 论文通过理论分析,将性能差距分解为显式和隐式表示差距,并研究模型偏差对最终策略质量的影响。
- 研究表明,在线DPO在特定模型错误指定情况下优于RLHF和DPO,并揭示了RLHF在样本效率方面的统计优势。
📝 摘要(中文)
本文针对存在表示差距的情况下,对基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)之间的性能差距进行了细致的理论分析。研究将此差距分解为两个来源:精确优化下的显式表示差距和有限样本下的隐式表示差距。在精确优化设置中,本文描述了奖励模型和策略模型类别的相对容量如何影响最终策略的质量。研究表明,RLHF、DPO或在线DPO可能彼此优于对方,具体取决于模型错误指定的类型。值得注意的是,当奖励和策略模型类别同构且都存在错误指定时,在线DPO可以优于RLHF和标准DPO。在近似优化设置中,本文提供了一个具体构造,其中真实奖励是隐式稀疏的,并表明RLHF需要比DPO少得多的样本来恢复有效的奖励模型——突出了两阶段学习的统计优势。总之,这些结果提供了对各种设置下RLHF和DPO之间性能差距的全面理解,并为何时首选每种方法提供了实践见解。
🔬 方法详解
问题定义:论文旨在解决RLHF(Reinforcement Learning from Human Feedback)和DPO(Direct Preference Optimization)在偏好学习中性能差距的问题。现有方法缺乏对这种差距的细粒度理解,尤其是在模型存在偏差(representation gap)的情况下,无法解释为何在某些场景下RLHF更好,而在另一些场景下DPO更优。
核心思路:论文的核心思路是将RLHF和DPO的性能差距分解为两个部分:一是精确优化下的显式表示差距,这与模型类别的容量有关;二是有限样本下的隐式表示差距,这与样本效率有关。通过分析这两个差距,可以更好地理解不同方法在不同模型假设下的表现。
技术框架:论文的整体框架是理论分析。首先,在精确优化的假设下,研究不同模型类别(奖励模型和策略模型)的容量如何影响最终策略的质量,并比较RLHF、DPO和在线DPO的性能。然后,在近似优化的假设下,研究样本数量对模型学习的影响,并比较RLHF和DPO的样本效率。
关键创新:论文的关键创新在于对RLHF和DPO性能差距的细粒度分解,并揭示了模型偏差对性能的影响。特别地,论文证明了在线DPO在特定模型错误指定情况下可以优于RLHF和DPO,并指出了RLHF在样本效率方面的优势。
关键设计:论文采用了理论分析的方法,没有涉及具体的参数设置或网络结构。关键在于对模型类别容量的定义和对样本复杂度的分析。论文通过数学推导和证明,给出了不同方法在不同假设下的性能界限。
🖼️ 关键图片
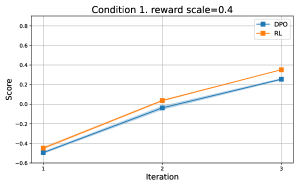
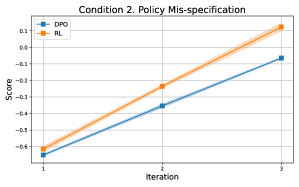
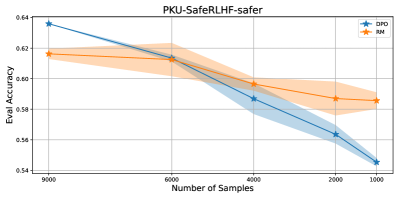
📊 实验亮点
研究表明,当奖励和策略模型类别同构且都存在错误指定时,在线DPO可以优于RLHF和标准DPO。此外,论文还证明了在隐式稀疏奖励的情况下,RLHF比DPO需要更少的样本来恢复有效的奖励模型,突出了RLHF在样本效率方面的优势。
🎯 应用场景
该研究成果可应用于大型语言模型的对齐和优化,帮助研究人员和工程师选择合适的偏好学习方法,并针对特定任务和模型特点进行调整。通过理解不同方法的优缺点,可以更有效地利用人类反馈来提升模型的性能和安全性,从而推动人工智能技术的发展。
📄 摘要(原文)
We present a fine-grained theoretical analysis of the performance gap between reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) under a representation gap. Our study decomposes this gap into two sources: an explicit representation gap under exact optimization and an implicit representation gap under finite samples. In the exact optimization setting, we characterize how the relative capacities of the reward and policy model classes influence the final policy qualities. We show that RLHF, DPO, or online DPO can outperform one another depending on type of model mis-specifications. Notably, online DPO can outperform both RLHF and standard DPO when the reward and policy model classes are isomorphic and both mis-specified. In the approximate optimization setting, we provide a concrete construction where the ground-truth reward is implicitly sparse and show that RLHF requires significantly fewer samples than DPO to recover an effective reward model -- highlighting a statistical advantage of two-stage learning. Together, these results provide a comprehensive understanding of the performance gap between RLHF and DPO under various settings, and offer practical insights into when each method is preferred.