GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning
作者: Shutong Ding, Ke Hu, Shan Zhong, Haoyang Luo, Weinan Zhang, Jingya Wang, Jun Wang, Ye Shi
分类: cs.LG
发布日期: 2025-05-24 (更新: 2026-01-22)
备注: Accepted by NeurIPS2025
💡 一句话要点
GenPO:首个将生成扩散模型成功集成到On-Policy强化学习的框架,提升机器人任务性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成扩散模型 On-Policy强化学习 策略优化 机器人控制 可逆动作映射
📋 核心要点
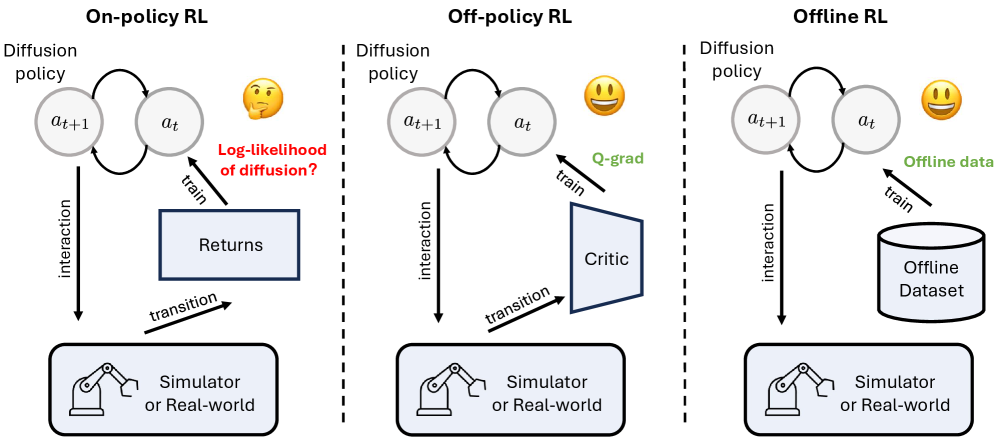
- 现有方法难以将生成扩散模型策略集成到on-policy强化学习框架中,尤其是在大规模并行GPU加速模拟器上。
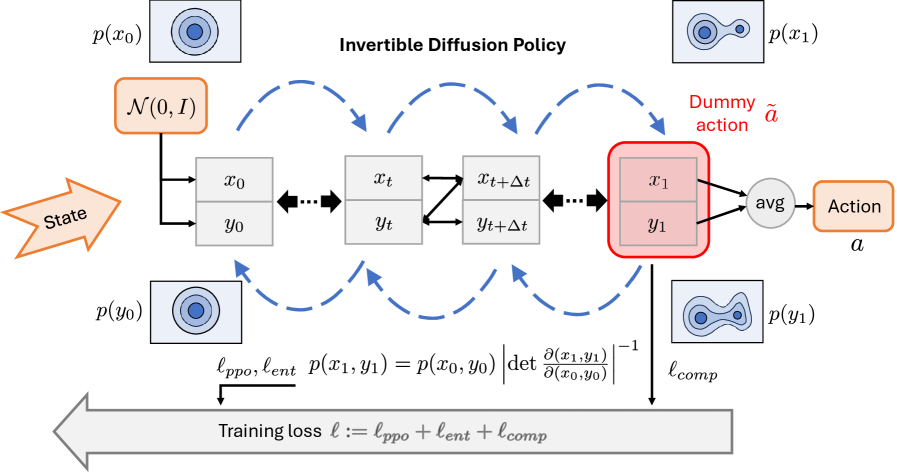
- GenPO通过精确扩散反演构建可逆动作映射,并引入双重虚拟动作机制,解决了对数似然计算难题。
- 在IsaacLab的多个机器人任务基准测试中,GenPO显著优于现有强化学习方法,验证了其有效性。
📝 摘要(中文)
本文提出GenPO,一个生成策略优化框架,旨在将生成扩散模型集成到on-policy强化学习中。现有方法在离线和off-policy强化学习中取得了显著进展,但将扩散策略应用于像PPO这样的on-policy框架仍未被充分探索。主要挑战在于计算扩散策略下的状态-动作对数似然,这对于高斯策略是直接的,但对于基于流的模型来说是难以处理的,因为其存在不可逆的前向-反向过程和离散化误差。GenPO利用精确的扩散反演来构建可逆的动作映射,并通过一种新颖的双重虚拟动作机制实现可逆性,从而解决了对数似然计算的障碍。此外,GenPO还使用动作对数似然进行无偏的熵和KL散度估计,从而在on-policy更新中实现KL自适应学习率和熵正则化。在IsaacLab的八个基准测试中,GenPO优于现有的强化学习基线。GenPO是第一个成功将扩散策略集成到on-policy强化学习中的方法。
🔬 方法详解
问题定义:论文旨在解决将生成扩散模型集成到on-policy强化学习框架中的难题。现有方法在离线和off-policy强化学习中已经取得了进展,但是由于扩散模型的不可逆性和离散化误差,直接计算状态-动作对数似然变得非常困难,这阻碍了其在on-policy算法(如PPO)中的应用。
核心思路:GenPO的核心思路是利用精确的扩散反演来构建可逆的动作映射。通过将动作空间扩展为包含原始动作和虚拟动作,并设计一种交替更新机制,使得整个动作映射变得可逆,从而可以精确计算状态-动作对数似然。
技术框架:GenPO框架主要包含以下几个模块:1) 扩散策略网络,用于生成动作;2) 扩散反演模块,用于计算逆过程;3) 双重虚拟动作机制,用于保证动作映射的可逆性;4) PPO更新模块,利用计算得到的对数似然进行策略优化。整个流程是:首先,扩散策略网络根据当前状态生成动作和虚拟动作;然后,利用扩散反演模块计算逆过程,得到可逆的动作映射;最后,利用PPO算法更新策略网络。
关键创新:GenPO的关键创新在于双重虚拟动作机制和精确扩散反演的应用。双重虚拟动作机制通过交替更新保证了动作映射的可逆性,从而可以精确计算状态-动作对数似然。精确扩散反演避免了离散化误差,提高了计算精度。
关键设计:GenPO的关键设计包括:1) 扩散模型的选择,可以使用不同的扩散模型架构,如DDPM、DDIM等;2) 虚拟动作的维度和更新方式,需要根据具体任务进行调整;3) PPO算法的参数设置,如学习率、裁剪系数等;4) 损失函数的设计,包括策略损失、价值损失和熵正则化项。
🖼️ 关键图片
📊 实验亮点
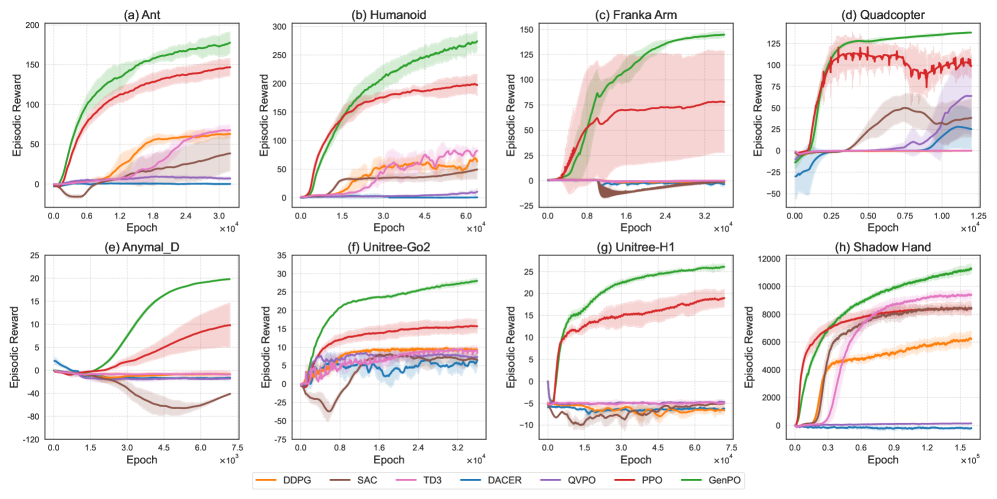
GenPO在IsaacLab的八个基准测试中均取得了显著的性能提升,包括legged locomotion (Ant, Humanoid, Anymal-D, Unitree H1, Go2), dexterous manipulation (Shadow Hand), aerial control (Quadcopter), 和 robotic arm tasks (Franka)。实验结果表明,GenPO优于现有的强化学习基线,证明了其在复杂机器人控制任务中的有效性。
🎯 应用场景
GenPO具有广泛的应用前景,可应用于各种机器人控制任务,如 legged locomotion、dexterous manipulation、aerial control 和 robotic arm tasks。该方法能够利用大规模并行模拟器进行快速训练,并有望部署到真实机器人系统中,解决复杂环境下的机器人控制问题。
📄 摘要(原文)
Recent advances in reinforcement learning (RL) have demonstrated the powerful exploration capabilities and multimodality of generative diffusion-based policies. While substantial progress has been made in offline RL and off-policy RL settings, integrating diffusion policies into on-policy frameworks like PPO remains underexplored. This gap is particularly significant given the widespread use of large-scale parallel GPU-accelerated simulators, such as IsaacLab, which are optimized for on-policy RL algorithms and enable rapid training of complex robotic tasks. A key challenge lies in computing state-action log-likelihoods under diffusion policies, which is straightforward for Gaussian policies but intractable for flow-based models due to irreversible forward-reverse processes and discretization errors (e.g., Euler-Maruyama approximations). To bridge this gap, we propose GenPO, a generative policy optimization framework that leverages exact diffusion inversion to construct invertible action mappings. GenPO introduces a novel doubled dummy action mechanism that enables invertibility via alternating updates, resolving log-likelihood computation barriers. Furthermore, we also use the action log-likelihood for unbiased entropy and KL divergence estimation, enabling KL-adaptive learning rates and entropy regularization in on-policy updates. Extensive experiments on eight IsaacLab benchmarks, including legged locomotion (Ant, Humanoid, Anymal-D, Unitree H1, Go2), dexterous manipulation (Shadow Hand), aerial control (Quadcopter), and robotic arm tasks (Franka), demonstrate GenPO's superiority over existing RL baselines. Notably, GenPO is the first method to successfully integrate diffusion policies into on-policy RL, unlocking their potential for large-scale parallelized training and real-world robotic deployment.