Efficient Online RL Fine Tuning with Offline Pre-trained Policy Only
作者: Wei Xiao, Jiacheng Liu, Zifeng Zhuang, Runze Suo, Shangke Lyu, Donglin Wang
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-05-22
💡 一句话要点
提出PORL,仅用离线预训练策略高效微调在线强化学习,无需Q函数。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 在线强化学习 离线预训练策略 策略微调 Q函数初始化 行为克隆
📋 核心要点
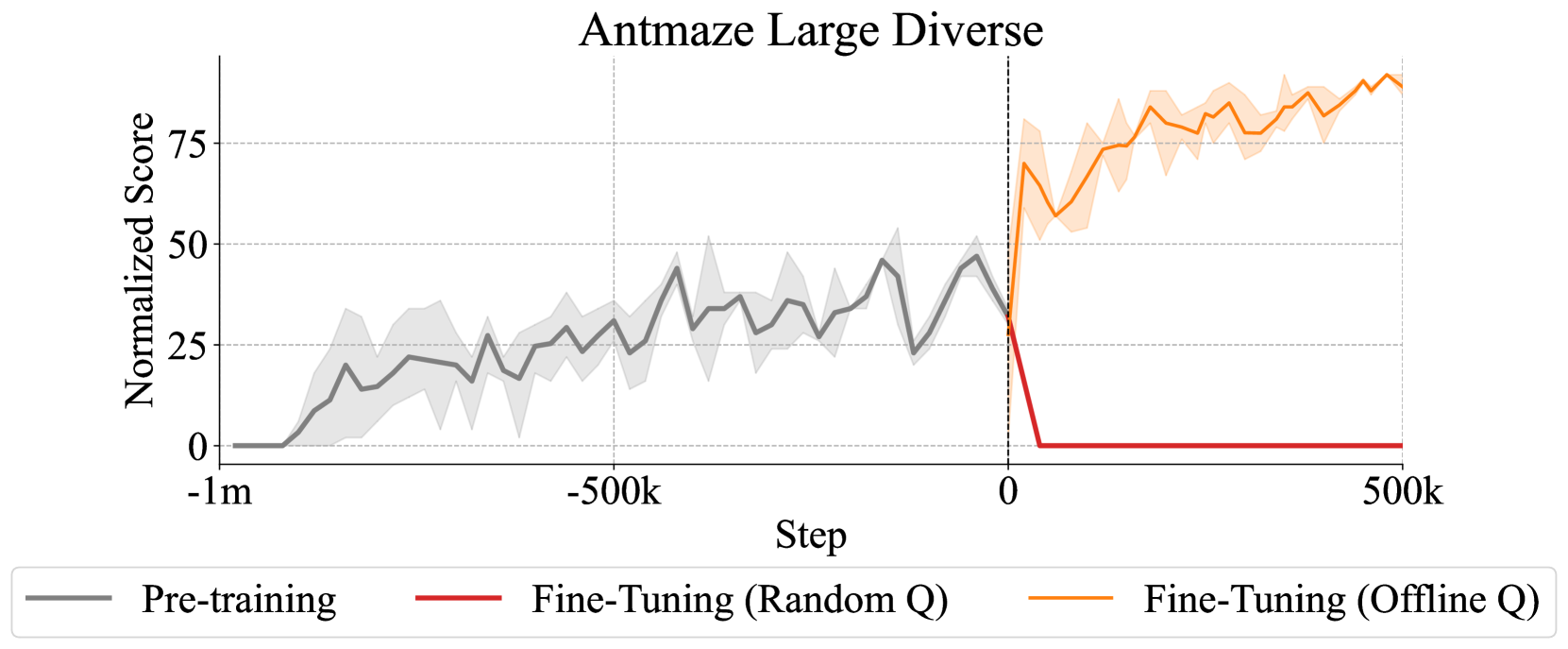
- 现有在线RL微调依赖离线预训练Q函数,但其保守性阻碍了在线探索,且限制了在仅有预训练策略场景下的应用。
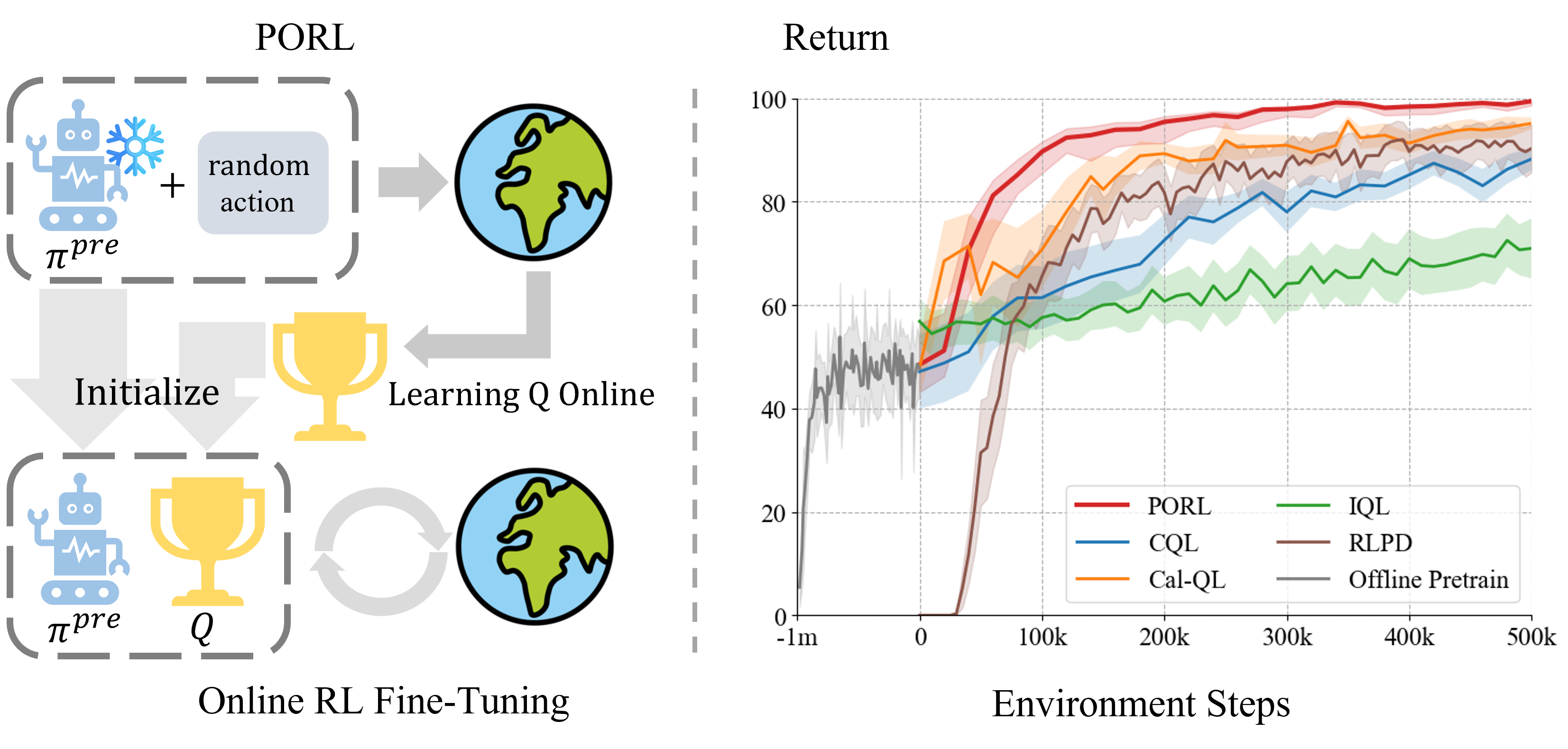
- PORL方法仅使用离线预训练策略,在线阶段从头初始化Q函数,避免悲观估计,实现高效微调。
- 实验表明,PORL性能与现有算法相当,并首次实现了直接微调行为克隆策略,开辟了新路径。
📝 摘要(中文)
通过在线强化学习(RL)提升预训练策略的性能至关重要但充满挑战。现有的在线RL微调方法需要持续使用离线预训练的Q函数以保证稳定性和性能。然而,由于大多数离线RL方法的保守性,这些离线预训练的Q函数通常低估了离线数据集之外的状态-动作对,这阻碍了从离线到在线环境的探索。此外,这种需求限制了它们在只有预训练策略而没有预训练Q函数的情况下的适用性,例如在模仿学习(IL)预训练中。为了解决这些挑战,我们提出了一种仅使用离线预训练策略进行高效在线RL微调的方法,消除了对预训练Q函数的依赖。我们引入了PORL(Policy-Only Reinforcement Learning Fine-Tuning),它在在线阶段从头开始快速初始化Q函数,以避免有害的悲观估计。我们的方法不仅实现了与先进的离线到在线RL算法以及利用先前数据或策略的在线RL方法相媲美的性能,而且还为直接微调行为克隆(BC)策略开辟了一条新道路。
🔬 方法详解
问题定义:论文旨在解决现有在线强化学习微调方法对离线预训练Q函数的依赖问题。现有方法的痛点在于,离线Q函数通常过于保守,低估了未在离线数据集中出现的状态-动作对,从而限制了在线探索。此外,当只有预训练策略(例如,通过模仿学习得到的策略)而没有相应的Q函数时,现有方法无法应用。
核心思路:论文的核心思路是消除对离线预训练Q函数的依赖,仅使用离线预训练的策略进行在线微调。通过在在线阶段从头开始快速初始化Q函数,避免了离线Q函数的保守性带来的负面影响,从而鼓励更有效的探索。
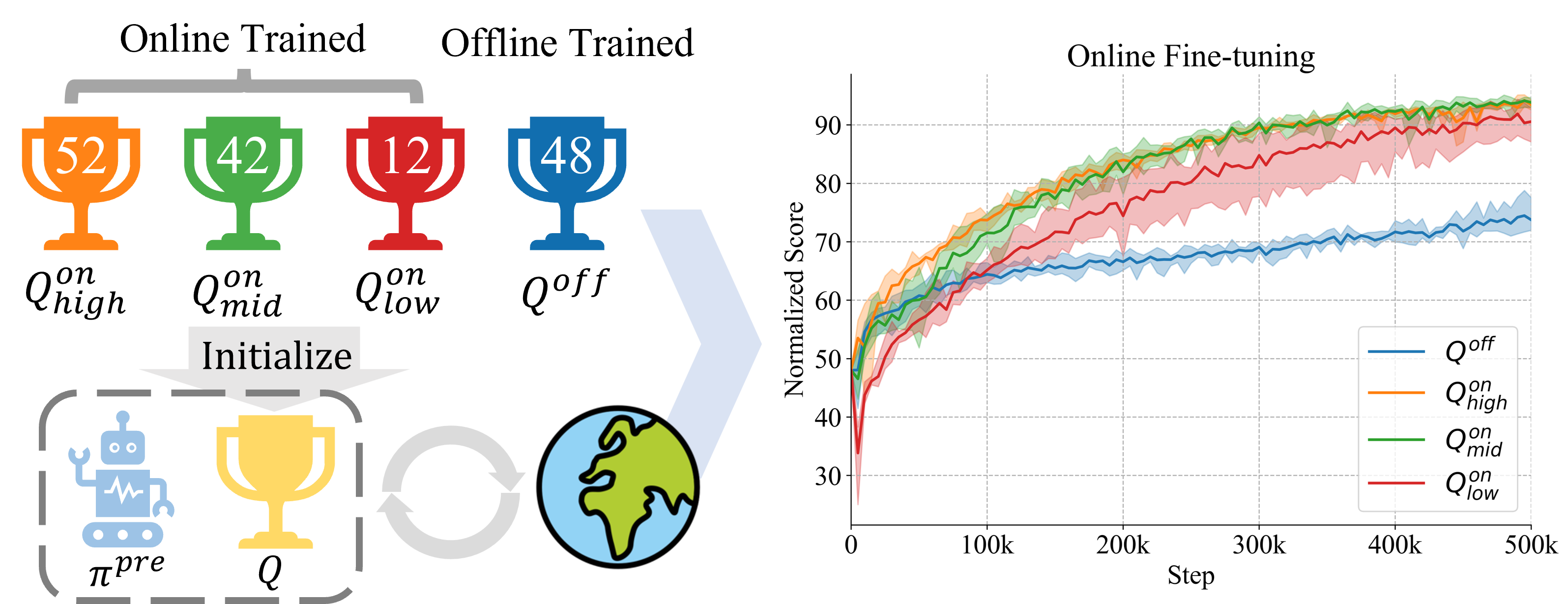
技术框架:PORL方法包含两个主要阶段:离线预训练阶段和在线微调阶段。在离线阶段,使用任意方法(例如,行为克隆)训练一个策略。在在线阶段,PORL从头开始初始化Q函数,并使用在线RL算法(例如,SAC、TD3)同时更新策略和Q函数。关键在于,Q函数的初始化不依赖于任何离线信息,而是通过与环境交互获得的经验进行学习。
关键创新:PORL最重要的创新点在于其“策略优先”的微调方式,即仅依赖预训练策略,而无需预训练Q函数。这与现有方法形成鲜明对比,现有方法通常需要同时使用预训练策略和Q函数。这种设计使得PORL能够应用于更广泛的场景,包括那些只有通过模仿学习获得的策略的情况。
关键设计:PORL的关键设计在于Q函数的初始化策略。论文中并没有明确指定具体的初始化方法,而是强调从头开始初始化,避免受到离线数据的偏差影响。在线更新策略和Q函数可以使用任何现有的在线RL算法。损失函数和网络结构的选择取决于所使用的具体在线RL算法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PORL在多个基准测试中取得了与先进的离线到在线RL算法以及利用先前数据或策略的在线RL方法相媲美的性能。更重要的是,PORL首次成功地直接微调了行为克隆(BC)策略,为在线强化学习开辟了一条新的道路。具体性能数据未知。
🎯 应用场景
PORL方法具有广泛的应用前景,尤其适用于那些难以获取高质量离线Q函数的场景,例如机器人控制、自动驾驶和游戏AI。它可以直接微调通过模仿学习获得的策略,降低了对专家数据的依赖。该研究有助于推动强化学习在实际场景中的应用,并为开发更高效、更灵活的在线学习算法提供了新的思路。
📄 摘要(原文)
Improving the performance of pre-trained policies through online reinforcement learning (RL) is a critical yet challenging topic. Existing online RL fine-tuning methods require continued training with offline pretrained Q-functions for stability and performance. However, these offline pretrained Q-functions commonly underestimate state-action pairs beyond the offline dataset due to the conservatism in most offline RL methods, which hinders further exploration when transitioning from the offline to the online setting. Additionally, this requirement limits their applicability in scenarios where only pre-trained policies are available but pre-trained Q-functions are absent, such as in imitation learning (IL) pre-training. To address these challenges, we propose a method for efficient online RL fine-tuning using solely the offline pre-trained policy, eliminating reliance on pre-trained Q-functions. We introduce PORL (Policy-Only Reinforcement Learning Fine-Tuning), which rapidly initializes the Q-function from scratch during the online phase to avoid detrimental pessimism. Our method not only achieves competitive performance with advanced offline-to-online RL algorithms and online RL approaches that leverage data or policies prior, but also pioneers a new path for directly fine-tuning behavior cloning (BC) policies.