Large Language models for Time Series Analysis: Techniques, Applications, and Challenges
作者: Feifei Shi, Xueyan Yin, Kang Wang, Wanyu Tu, Qifu Sun, Huansheng Ning
分类: cs.LG, cs.CL, cs.ET
发布日期: 2025-05-21
💡 一句话要点
综述性论文:探索大型语言模型在时间序列分析中的技术、应用与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分析 大型语言模型 预训练模型 跨模态学习 注意力机制
📋 核心要点
- 传统时间序列分析方法在处理复杂的非线性关系和长期依赖方面存在局限性,难以满足日益增长的应用需求。
- 利用预训练大型语言模型(LLM)的强大能力,结合其跨模态知识和注意力机制,为时间序列分析提供了一种新的解决思路。
- 本文系统性地回顾了LLM驱动的时间序列分析技术,并探讨了其在实际应用中的潜力与面临的挑战,为未来研究指明方向。
📝 摘要(中文)
时间序列分析在金融预测和生物医学监测等领域至关重要,但传统方法受限于非线性特征表示和长期依赖关系捕获。大型语言模型(LLM)的出现,通过利用其跨模态知识整合和内在的注意力机制,为时间序列分析提供了变革性的潜力。然而,从零开始开发用于时间序列的通用LLM仍然受到数据多样性、标注稀缺性和计算需求的阻碍。本文对预训练的LLM驱动的时间序列分析进行了系统综述,重点关注使能技术、潜在应用和开放挑战。首先,它建立了AI驱动的时间序列分析的演进路线图,从早期的机器学习时代,到新兴的LLM驱动范式,再到原生时间序列基础模型的发展。其次,它从工作流的角度组织和系统化了LLM驱动的时间序列分析的技术格局,涵盖了LLM的输入、优化和轻量化阶段。最后,它批判性地考察了新的实际应用,并强调了可以指导未来研究和创新的关键开放挑战。这项工作不仅提供了对当前进展的宝贵见解,而且概述了未来发展的有希望的方向。它为学术界和工业界的研究人员提供了一个基础参考,为开发更高效、通用和可解释的LLM驱动的时间序列分析系统铺平了道路。
🔬 方法详解
问题定义:传统时间序列分析方法难以有效捕捉数据中的非线性特征和长期依赖关系,导致预测精度和泛化能力受限。此外,针对特定领域的时间序列分析模型往往缺乏通用性,难以迁移到其他领域。
核心思路:利用预训练大型语言模型(LLM)强大的特征提取和知识迁移能力,将时间序列数据转换为LLM能够理解的格式,并利用LLM的注意力机制来捕捉时间序列中的长期依赖关系。通过这种方式,可以提高时间序列分析的精度和泛化能力。
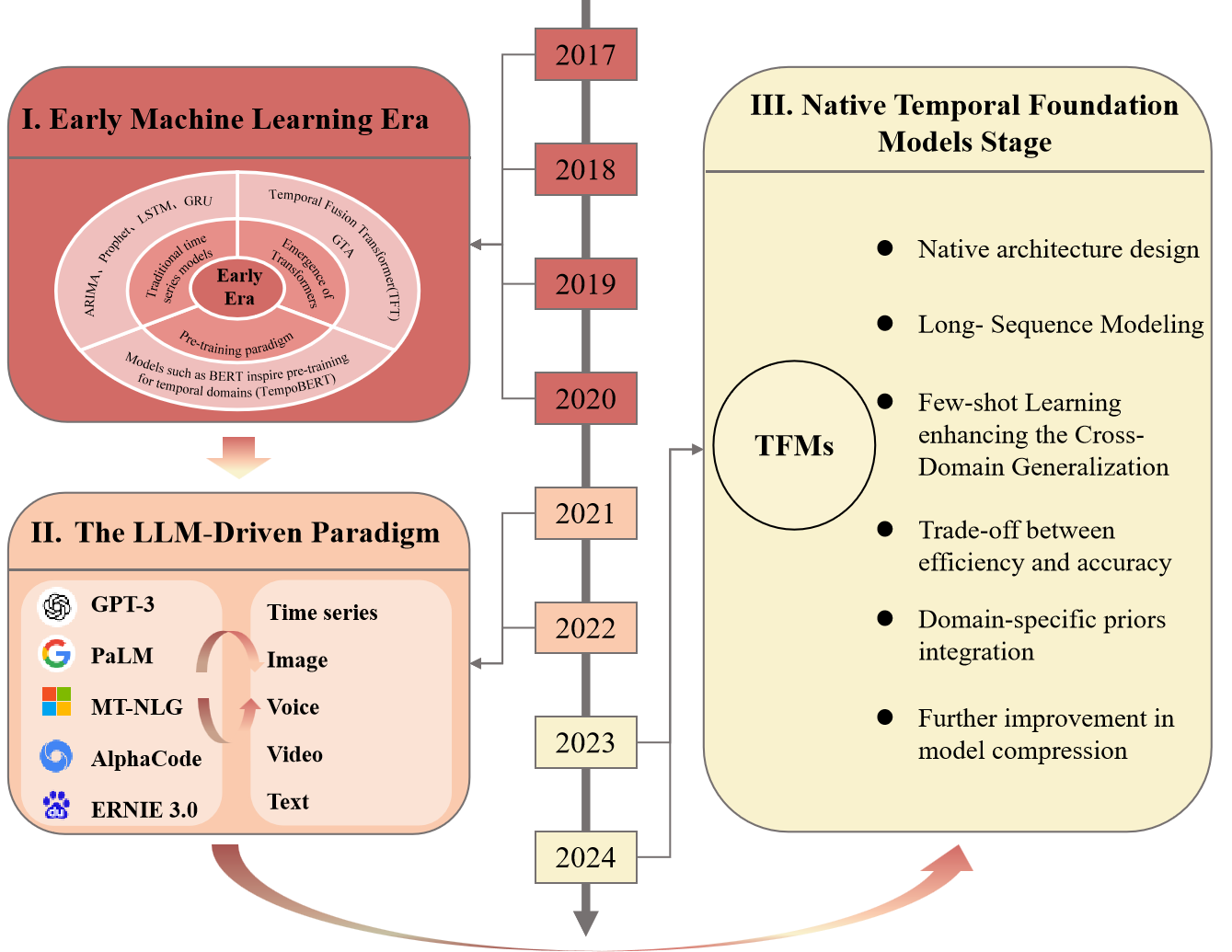
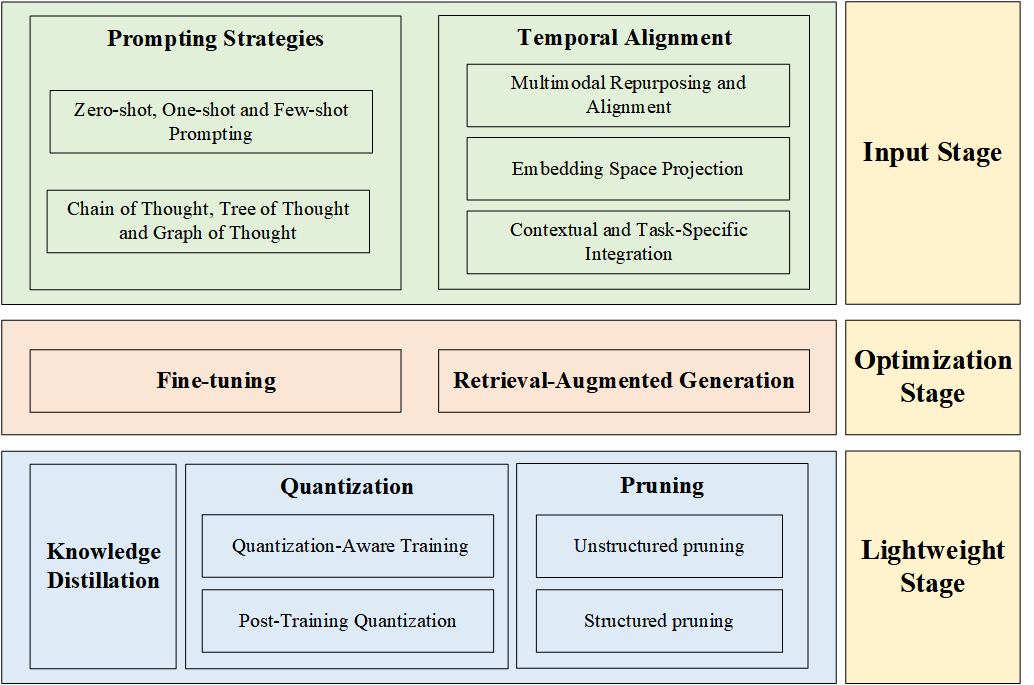
技术框架:该综述从LLM驱动的时间序列分析的工作流程角度进行组织,主要包括三个阶段:输入阶段(如何将时间序列数据输入LLM)、优化阶段(如何针对时间序列分析任务优化LLM)和轻量化阶段(如何降低LLM的计算成本)。每个阶段都涉及多种技术方法,例如时间序列数据的token化、prompt工程、微调策略和模型压缩等。
关键创新:该综述的关键创新在于系统性地总结了LLM在时间序列分析中的应用,并提出了一个AI驱动的时间序列分析的演进路线图,从早期的机器学习时代,到新兴的LLM驱动范式,再到原生时间序列基础模型的发展。此外,该综述还指出了LLM驱动的时间序列分析面临的挑战和未来的研究方向。
关键设计:该综述详细讨论了时间序列数据token化的方法,例如将时间序列数据转换为文本描述或图像表示。此外,该综述还讨论了prompt工程在时间序列分析中的应用,例如设计合适的prompt来引导LLM进行预测或分类。最后,该综述还讨论了模型压缩技术,例如知识蒸馏和量化,以降低LLM的计算成本。
🖼️ 关键图片

📊 实验亮点
该论文是一篇综述性文章,没有具体的实验结果。但它总结了当前LLM在时间序列分析中的应用,并指出了未来的研究方向。通过对现有研究的分析,可以发现LLM在时间序列分析中具有巨大的潜力,例如在金融预测和生物医学监测等领域,LLM可以显著提高预测精度和泛化能力。
🎯 应用场景
该研究成果可应用于金融预测、生物医学监测、工业生产优化、交通流量预测等多个领域。通过利用LLM强大的分析能力,可以提高预测精度、降低运营成本,并为决策提供更可靠的依据。未来,LLM驱动的时间序列分析有望成为各行业智能化升级的重要推动力。
📄 摘要(原文)
Time series analysis is pivotal in domains like financial forecasting and biomedical monitoring, yet traditional methods are constrained by limited nonlinear feature representation and long-term dependency capture. The emergence of Large Language Models (LLMs) offers transformative potential by leveraging their cross-modal knowledge integration and inherent attention mechanisms for time series analysis. However, the development of general-purpose LLMs for time series from scratch is still hindered by data diversity, annotation scarcity, and computational requirements. This paper presents a systematic review of pre-trained LLM-driven time series analysis, focusing on enabling techniques, potential applications, and open challenges. First, it establishes an evolutionary roadmap of AI-driven time series analysis, from the early machine learning era, through the emerging LLM-driven paradigm, to the development of native temporal foundation models. Second, it organizes and systematizes the technical landscape of LLM-driven time series analysis from a workflow perspective, covering LLMs' input, optimization, and lightweight stages. Finally, it critically examines novel real-world applications and highlights key open challenges that can guide future research and innovation. The work not only provides valuable insights into current advances but also outlines promising directions for future development. It serves as a foundational reference for both academic and industrial researchers, paving the way for the development of more efficient, generalizable, and interpretable systems of LLM-driven time series analysis.