SIMCOPILOT: Evaluating Large Language Models for Copilot-Style Code Generation
作者: Mingchao Jiang, Abhinav Jain, Sophia Zorek, Chris Jermaine
分类: cs.LG, cs.PL, cs.SE
发布日期: 2025-05-21
备注: Keywords: Benchmark Dataset, LLM Evaluation, Gen-AI, Program Synthesis; TLDR: SimCoPilot is a benchmark for evaluating LLMs as "copilot"-style interactive coding assistants, testing their ability to integrate and complete code within complex real-world software environments
💡 一句话要点
SIMCOPILOT:提出用于评估大语言模型在协同编程中代码生成能力的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大语言模型 协同编程 基准测试 代码补全
📋 核心要点
- 现有代码生成基准测试缺乏对LLM在实际协同编程场景中表现的细致评估,忽略了上下文理解和变量作用域等关键因素。
- SIMCOPILOT通过模拟真实的协同编程环境,提供代码补全和填充任务,全面评估LLM的代码生成能力。
- 实验结果揭示了LLM在复杂依赖结构中保持逻辑一致性的挑战,并指出了LLM在成为可靠软件开发伙伴方面的局限性。
📝 摘要(中文)
本文提出了SIMCOPILOT,一个模拟大语言模型(LLM)作为交互式、协同编程助手的基准测试。SIMCOPILOT针对代码补全(完成不完整的方法或代码块)和代码填充(填充现有代码中的缺失部分)任务,为评估LLM的代码生成能力提供了一个全面的框架。该基准测试包含Java(SIMCOPILOTJ)和Python(SIMCOPILOTP)的专用子基准,涵盖了大小和复杂性各异的多种代码库。主要贡献包括:(a)建立了一个现实、详细的评估环境,以评估LLM在实际编码场景中的效用;(b)提供细粒度的分析,解决现有基准测试经常忽略的关键因素,例如特定任务的性能细微差别、跨代码段的上下文理解以及对变量作用域的敏感性。在算法、数据库、计算机视觉和神经网络等领域进行的评估,深入了解了模型的优势,并突出了在复杂依赖结构中保持逻辑一致性的持续挑战。除了基准测试之外,该研究还揭示了LLM驱动的代码生成的当前局限性,并强调了LLM从仅仅是语法感知生成器向可靠、智能的软件开发伙伴的持续转变。
🔬 方法详解
问题定义:论文旨在解决现有代码生成基准测试无法真实反映LLM在协同编程场景下性能的问题。现有基准测试往往忽略了代码上下文、变量作用域等重要因素,导致评估结果与实际应用存在偏差。此外,缺乏针对不同编程语言和应用领域的细粒度评估。
核心思路:论文的核心思路是构建一个模拟真实协同编程环境的基准测试,即SIMCOPILOT。该基准测试包含代码补全和代码填充两种任务,并针对Java和Python两种编程语言分别设计了子基准。通过在不同领域和复杂度的代码库上进行评估,可以更全面地了解LLM的代码生成能力。
技术框架:SIMCOPILOT框架包含以下主要组成部分:1) 代码库:包含来自不同领域(如算法、数据库、计算机视觉、神经网络)的Java和Python代码库,代码库的大小和复杂度各异。2) 任务生成器:根据代码库生成代码补全和代码填充任务。代码补全任务要求LLM完成不完整的方法或代码块,代码填充任务要求LLM填充现有代码中的缺失部分。3) 评估指标:使用多种评估指标来衡量LLM生成的代码的正确性、效率和可读性。4) 评估流程:将生成的任务输入到LLM中,然后使用评估指标对LLM的输出进行评估。
关键创新:SIMCOPILOT的关键创新在于其真实性和细粒度。它模拟了真实的协同编程环境,并考虑了代码上下文、变量作用域等重要因素。此外,SIMCOPILOT提供了针对不同编程语言和应用领域的细粒度评估,可以更全面地了解LLM的代码生成能力。与现有方法相比,SIMCOPILOT更能够反映LLM在实际应用中的性能。
关键设计:SIMCOPILOT的关键设计包括:1) 代码库的选择:选择具有代表性的代码库,涵盖不同的编程语言和应用领域。2) 任务生成策略:设计合理的任务生成策略,确保生成的任务具有挑战性和多样性。3) 评估指标的选择:选择合适的评估指标,能够准确衡量LLM生成的代码的质量。4) 评估流程的设计:设计高效的评估流程,能够快速评估LLM的性能。
🖼️ 关键图片


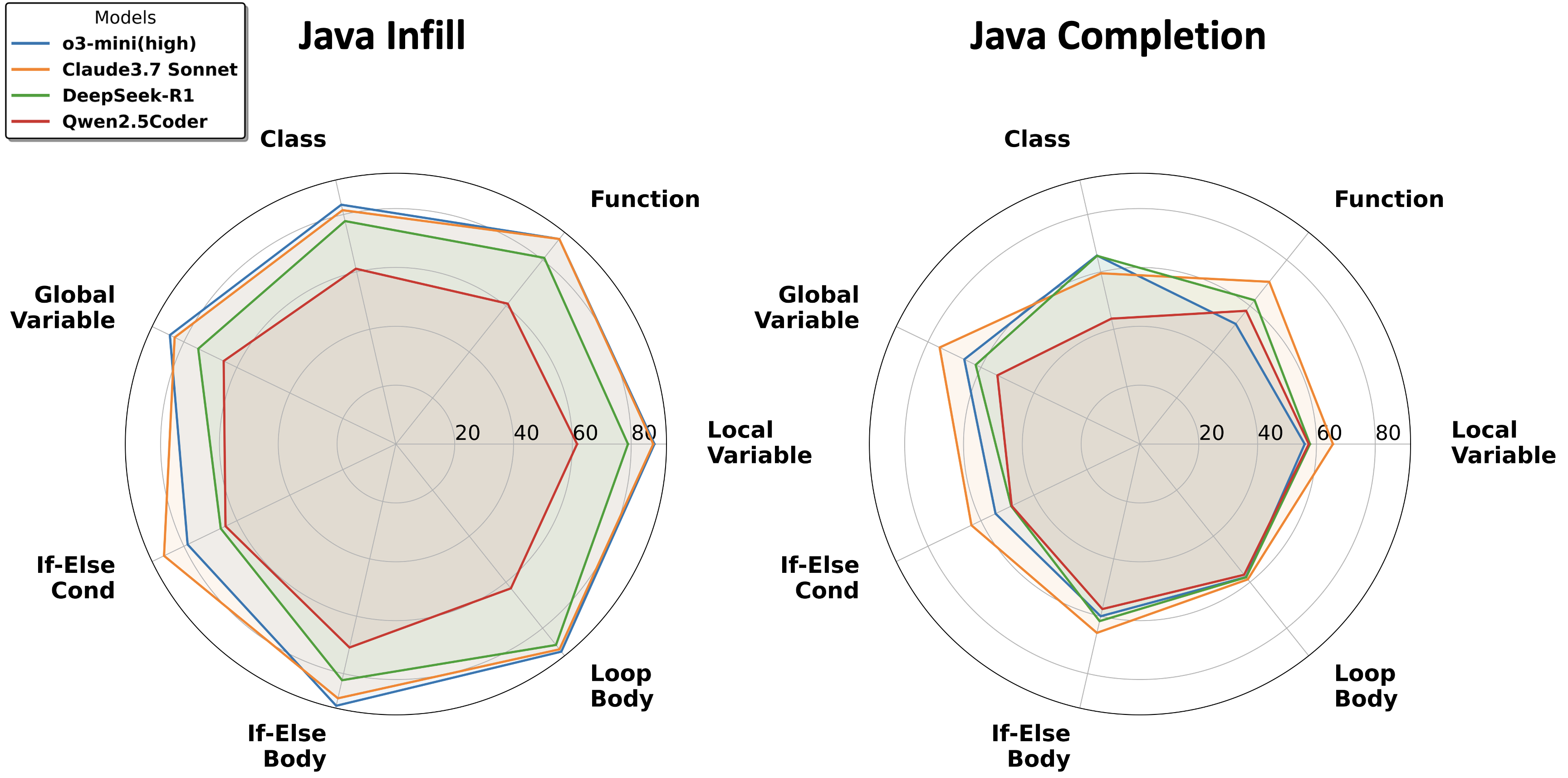
📊 实验亮点
SIMCOPILOT在算法、数据库、计算机视觉和神经网络等多个领域对LLM进行了评估,揭示了LLM在不同任务上的性能差异。实验结果表明,LLM在简单任务上表现良好,但在复杂依赖结构中保持逻辑一致性方面仍面临挑战。例如,在处理涉及复杂变量作用域的代码时,LLM的性能显著下降。这些结果为LLM的改进提供了有价值的指导。
🎯 应用场景
SIMCOPILOT可用于评估和比较不同LLM的代码生成能力,帮助研究人员和开发人员选择合适的LLM用于协同编程。此外,该基准测试还可以用于指导LLM的训练和优化,提高其在实际应用中的性能。未来,SIMCOPILOT可以扩展到支持更多的编程语言和应用领域,并集成更多的评估指标。
📄 摘要(原文)
We introduce SIMCOPILOT, a benchmark that simulates the role of large language models (LLMs) as interactive, "copilot"-style coding assistants. Targeting both completion (finishing incomplete methods or code blocks) and infill tasks (filling missing segments within existing code), SIMCOPILOT provides a comprehensive framework for evaluating LLM coding capabilities. The benchmark comprises dedicated sub-benchmarks for Java (SIMCOPILOTJ) and Python (SIMCOPILOTP), covering diverse codebases varying in size and complexity. Our key contributions include: (a) establishing a realistic, detailed evaluation environment to assess LLM utility in practical coding scenarios, and (b) providing fine-grained analyses that address critical factors frequently overlooked by existing benchmarks, such as task-specific performance nuances, contextual understanding across code segments, and sensitivity to variable scope. Evaluations conducted across domains-including algorithms, databases, computer vision, and neural networks-offer insights into model strengths and highlight persistent challenges in maintaining logical consistency within complex dependency structures. Beyond benchmarking, our study sheds light on the current limitations of LLM-driven code generation and underscores the ongoing transition of LLMs from merely syntax-aware generators toward reliable, intelligent software development partners.