Evaluating Adversarial Robustness of Concept Representations in Sparse Autoencoders
作者: Aaron J. Li, Suraj Srinivas, Usha Bhalla, Himabindu Lakkaraju
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-21 (更新: 2026-01-22)
💡 一句话要点
评估稀疏自编码器中概念表示的对抗鲁棒性,揭示其脆弱性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 对抗鲁棒性 概念表示 大型语言模型 对抗攻击 可解释性 模型安全
📋 核心要点
- 现有稀疏自编码器(SAEs)的评估忽略了概念表示对输入扰动的鲁棒性,这直接影响了概念标记的可靠性。
- 论文将鲁棒性量化定义为输入空间优化问题,通过构造对抗性扰动来评估SAE表示的脆弱性。
- 实验表明,微小的对抗性扰动就能显著影响SAE的概念解释,而对底层LLM影响甚微,揭示了SAE概念表示的脆弱性。
📝 摘要(中文)
稀疏自编码器(SAEs)通常用于解释大型语言模型(LLMs)的内部激活,将其映射到人类可解释的概念表示。现有的SAEs评估主要集中在重建-稀疏性权衡、人类(自动)可解释性和特征解耦等指标上,但忽略了一个关键方面:概念表示对输入扰动的鲁棒性。我们认为鲁棒性必须是概念表示的一个基本考虑因素,反映概念标记的保真度。为此,我们将鲁棒性量化定义为输入空间优化问题,并开发了一个全面的评估框架,其中包含用于操纵SAE表示的对抗性扰动。实验结果表明,微小的对抗性输入扰动可以有效地操纵基于概念的解释,而不会显著影响基础LLM的激活。总的来说,我们的结果表明SAE概念表示是脆弱的,如果没有进一步的去噪或后处理,它们可能不适合用于模型监控和监督应用。
🔬 方法详解
问题定义:论文旨在解决稀疏自编码器(SAEs)提取的概念表示缺乏对抗鲁棒性的问题。现有方法主要关注SAEs的重建性能、稀疏性和可解释性,忽略了其对输入扰动的敏感性。这种敏感性使得SAEs容易受到对抗攻击,导致对LLM内部机制的错误理解。
核心思路:论文的核心思路是将鲁棒性评估转化为一个输入空间优化问题,通过寻找能够显著改变SAE激活的最小输入扰动来量化SAE的脆弱性。这种方法模拟了现实场景中可能出现的恶意输入,从而更全面地评估SAE的可靠性。
技术框架:论文构建了一个评估框架,主要包含以下步骤:1) 选择一个预训练的LLM和对应的SAE;2) 定义一组目标概念,这些概念对应于SAE中的特定神经元;3) 通过优化输入空间,生成能够最大程度激活或抑制目标概念的对抗性输入;4) 分析对抗性输入对SAE激活和LLM输出的影响,从而评估SAE的鲁棒性。
关键创新:论文的关键创新在于将对抗攻击的思想引入到SAE的鲁棒性评估中。与传统的鲁棒性评估方法不同,该方法不是简单地测量SAE在噪声输入下的性能下降,而是主动寻找能够欺骗SAE的对抗性样本。这种方法能够更有效地揭示SAE的脆弱性,并为后续的鲁棒性提升提供指导。
关键设计:论文使用梯度下降法在输入空间中搜索对抗性样本。目标函数通常包括两部分:一部分是衡量目标概念激活程度的项,另一部分是衡量输入扰动大小的正则化项。通过调整正则化系数,可以控制对抗性扰动的大小。此外,论文还考虑了不同的对抗攻击策略,例如targeted attack和untargeted attack,以更全面地评估SAE的鲁棒性。
🖼️ 关键图片

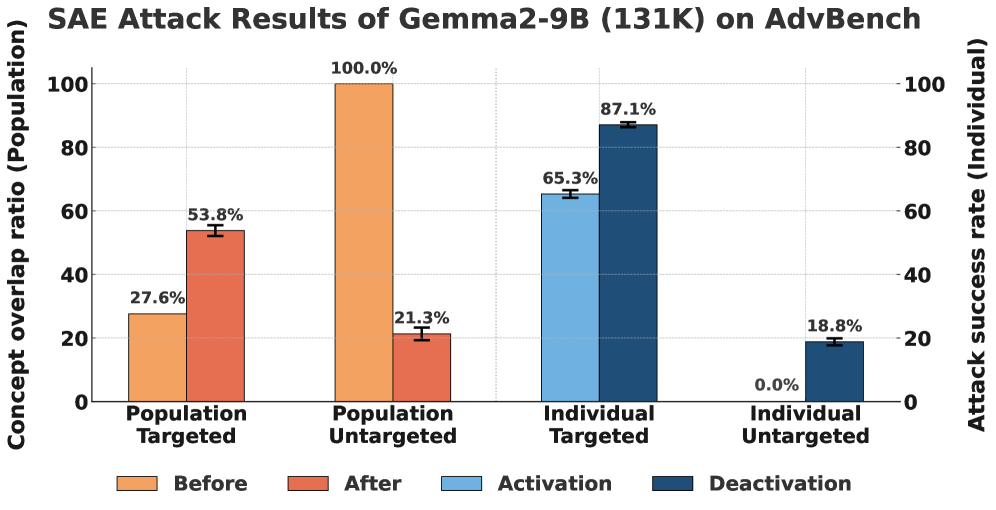

📊 实验亮点
实验结果表明,即使是微小的对抗性扰动也能显著改变SAE的概念激活,而对底层LLM的输出影响甚微。这表明SAE提取的概念表示是脆弱的,容易受到对抗攻击。例如,通过精心设计的对抗性输入,可以使SAE错误地将某个输入识别为包含特定概念,从而误导用户或系统。
🎯 应用场景
该研究成果可应用于大型语言模型的安全监控和可信赖AI系统的构建。通过提高概念表示的鲁棒性,可以减少模型被恶意利用的风险,并增强模型的可解释性和可靠性。此外,该研究还可以促进对LLM内部机制的更深入理解,为开发更安全、更可靠的AI系统奠定基础。
📄 摘要(原文)
Sparse autoencoders (SAEs) are commonly used to interpret the internal activations of large language models (LLMs) by mapping them to human-interpretable concept representations. While existing evaluations of SAEs focus on metrics such as the reconstruction-sparsity tradeoff, human (auto-)interpretability, and feature disentanglement, they overlook a critical aspect: the robustness of concept representations to input perturbations. We argue that robustness must be a fundamental consideration for concept representations, reflecting the fidelity of concept labeling. To this end, we formulate robustness quantification as input-space optimization problems and develop a comprehensive evaluation framework featuring realistic scenarios in which adversarial perturbations are crafted to manipulate SAE representations. Empirically, we find that tiny adversarial input perturbations can effectively manipulate concept-based interpretations in most scenarios without notably affecting the base LLM's activations. Overall, our results suggest that SAE concept representations are fragile and without further denoising or postprocessing they might be ill-suited for applications in model monitoring and oversight.