LLM-Explorer: A Plug-in Reinforcement Learning Policy Exploration Enhancement Driven by Large Language Models
作者: Qianyue Hao, Yiwen Song, Qingmin Liao, Jian Yuan, Yong Li
分类: cs.LG, cs.AI
发布日期: 2025-05-21 (更新: 2025-10-23)
🔗 代码/项目: GITHUB
💡 一句话要点
LLM-Explorer:利用大语言模型增强强化学习策略探索的插件式方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 策略探索 大语言模型 自适应策略 插件式设计
📋 核心要点
- 现有强化学习策略探索方法缺乏对任务特定特征的考虑,且探索过程僵化,难以根据agent学习状态动态调整。
- LLM-Explorer利用大语言模型分析agent学习轨迹,自适应生成任务特定的探索策略,动态调整探索过程。
- 实验表明,LLM-Explorer作为插件可显著提升多种RL算法在Atari和MuJoCo环境中的性能,平均提升高达37.27%。
📝 摘要(中文)
策略探索是强化学习(RL)中的关键环节,现有方法包括贪婪算法、高斯过程等。然而,这些方法使用预设的随机过程,并且不加区分地应用于各种RL任务,而没有考虑影响策略探索的任务特定特征。此外,在RL训练期间,这些随机过程的演变是僵化的,通常只包含方差的衰减,无法根据agent的实时学习状态灵活调整。受大型语言模型(LLM)的分析和推理能力的启发,我们设计了LLM-Explorer,利用LLM自适应地生成特定于任务的探索策略,从而增强RL中的策略探索。在我们的设计中,我们对给定任务中RL训练期间的agent学习轨迹进行采样,并提示LLM分析agent当前的策略学习状态,然后生成未来策略探索的概率分布。通过定期更新概率分布,我们推导出一个专门针对特定任务并动态调整以适应学习过程的随机过程。我们的设计是一个插件模块,与各种广泛应用的RL算法兼容,包括DQN系列、DDPG、TD3以及基于它们开发的任何可能的变体。通过在Atari和MuJoCo基准上的大量实验,我们证明了LLM-Explorer增强RL策略探索的能力,平均性能提升高达37.27%。我们的代码已在https://github.com/tsinghua-fib-lab/LLM-Explorer开源,以实现可重复性。
🔬 方法详解
问题定义:现有强化学习算法在策略探索阶段,通常采用预设的随机过程,如高斯噪声等。这些方法忽略了不同任务的特性,无法针对性地进行探索。此外,探索过程中的随机性调整通常是固定的,例如方差衰减,无法根据agent的实际学习情况进行动态调整。这导致探索效率低下,影响最终性能。
核心思路:论文的核心思路是利用大型语言模型(LLM)的分析和推理能力,根据agent在特定任务中的学习轨迹,动态生成任务相关的探索策略。LLM能够理解agent的学习状态,并据此生成更有效的探索概率分布,从而指导agent进行更有针对性的探索。
技术框架:LLM-Explorer作为一个插件模块,可以嵌入到现有的强化学习算法中。其主要流程包括:1) 采样agent在训练过程中的学习轨迹;2) 将采样轨迹作为prompt输入到LLM中;3) LLM分析agent的学习状态,并生成一个用于策略探索的概率分布;4) 根据该概率分布进行策略探索;5) 定期更新概率分布,以适应agent的学习过程。
关键创新:该方法最重要的创新点在于利用LLM来动态生成和调整探索策略。与传统的基于预设随机过程的探索方法不同,LLM-Explorer能够根据agent的学习状态和任务特性,自适应地生成探索策略,从而实现更高效的探索。这种基于LLM的动态探索策略是与现有方法的本质区别。
关键设计:关键设计包括:1) 如何有效地将agent的学习轨迹转化为LLM可以理解的prompt;2) 如何设计LLM的prompt,使其能够准确分析agent的学习状态并生成合适的探索概率分布;3) 如何定期更新概率分布,以保证探索策略能够适应agent的学习过程。具体参数设置和网络结构取决于所使用的LLM和强化学习算法。
🖼️ 关键图片


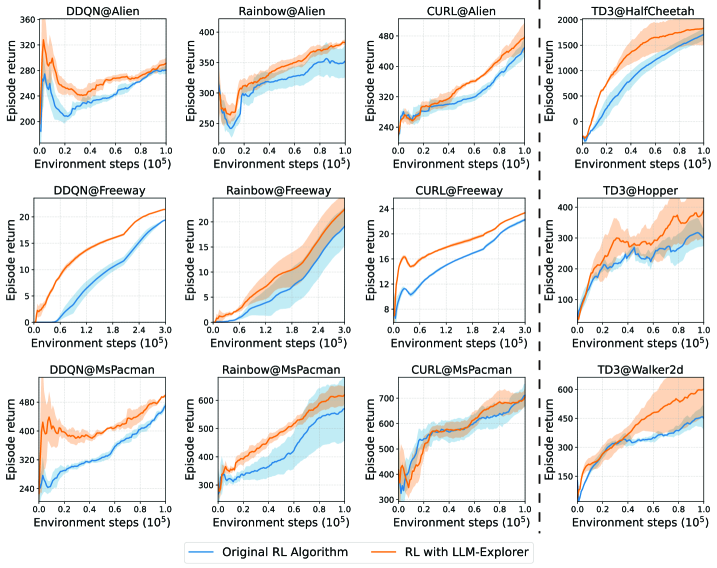
📊 实验亮点
实验结果表明,LLM-Explorer能够显著提升多种强化学习算法在Atari和MuJoCo基准测试中的性能。例如,在Atari游戏中,LLM-Explorer平均提升了37.27%的性能。与传统的探索方法相比,LLM-Explorer能够更快地找到更优的策略,并且具有更好的鲁棒性。这些结果充分证明了LLM-Explorer在强化学习策略探索方面的有效性。
🎯 应用场景
LLM-Explorer具有广泛的应用前景,可以应用于各种需要强化学习的领域,例如机器人控制、游戏AI、自动驾驶、推荐系统等。通过利用LLM的强大分析能力,可以显著提升强化学习算法的探索效率和最终性能,加速相关领域的智能化进程。未来,可以将LLM-Explorer与其他先进的强化学习技术相结合,进一步提升其性能和适用性。
📄 摘要(原文)
Policy exploration is critical in reinforcement learning (RL), where existing approaches include greedy, Gaussian process, etc. However, these approaches utilize preset stochastic processes and are indiscriminately applied in all kinds of RL tasks without considering task-specific features that influence policy exploration. Moreover, during RL training, the evolution of such stochastic processes is rigid, which typically only incorporates a decay in the variance, failing to adjust flexibly according to the agent's real-time learning status. Inspired by the analyzing and reasoning capability of large language models (LLMs), we design LLM-Explorer to adaptively generate task-specific exploration strategies with LLMs, enhancing the policy exploration in RL. In our design, we sample the learning trajectory of the agent during the RL training in a given task and prompt the LLM to analyze the agent's current policy learning status and then generate a probability distribution for future policy exploration. Updating the probability distribution periodically, we derive a stochastic process specialized for the particular task and dynamically adjusted to adapt to the learning process. Our design is a plug-in module compatible with various widely applied RL algorithms, including the DQN series, DDPG, TD3, and any possible variants developed based on them. Through extensive experiments on the Atari and MuJoCo benchmarks, we demonstrate LLM-Explorer's capability to enhance RL policy exploration, achieving an average performance improvement up to 37.27%. Our code is open-source at https://github.com/tsinghua-fib-lab/LLM-Explorer for reproducibility.