BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
作者: Yunlong Hou, Fengzhuo Zhang, Cunxiao Du, Xuan Zhang, Jiachun Pan, Tianyu Pang, Chao Du, Vincent Y. F. Tan, Zhuoran Yang
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-05-21 (更新: 2025-11-20)
备注: 35 pages, 4 figures, accepted to ICML, typos and affiliations are corrected
💡 一句话要点
提出BanditSpec以解决大语言模型推理加速问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 投机解码 多臂赌博机 超参数选择 大语言模型 在线学习 推理加速 算法优化
📋 核心要点
- 现有的投机解码方法通常采用固定配置,缺乏灵活性,无法根据输入上下文自适应调整超参数。
- 本文提出了一种基于多臂赌博机的框架BanditSpec,能够在线自适应选择投机解码的超参数,避免了训练过程的复杂性。
- 实验结果表明,BanditSpec在LLaMA3和Qwen2模型上表现优异,吞吐量接近于最佳超参数,显著提升了推理效率。
📝 摘要(中文)
投机解码已成为加速大语言模型推理的热门方法,同时保持其优越的文本生成性能。以往方法通常采用固定的投机解码配置,或以离线或在线方式训练草稿模型以与上下文对齐。本文提出了一种无训练的在线学习框架,能够在文本生成过程中自适应选择投机解码的超参数配置。我们将这一超参数选择问题形式化为多臂赌博机问题,并提供了通用的投机解码框架BanditSpec。此外,设计并分析了两种基于赌博机的超参数选择算法UCBSpec和EXP3Spec,并在随机和对抗奖励设置下对停止时间遗憾进行了上界分析。通过推导信息论的不可能性结果,证明了UCBSpec的遗憾性能在普遍常数下是最优的。最后,针对LLaMA3和Qwen2的广泛实证实验表明,我们的算法在现有方法中表现出色,吞吐量接近于模拟真实场景下的最佳超参数。
🔬 方法详解
问题定义:本文解决的是投机解码过程中超参数选择的灵活性问题。现有方法往往采用固定的超参数配置,无法根据生成的文本动态调整,导致性能不佳。
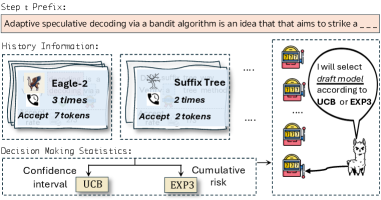
核心思路:论文提出将超参数选择问题形式化为多臂赌博机问题,通过在线学习的方式自适应选择最佳超参数配置,以提高推理效率和生成质量。
技术框架:整体框架包括两个主要模块:超参数选择模块和投机解码模块。超参数选择模块负责实时评估和选择最佳配置,而投机解码模块则执行文本生成任务。
关键创新:最重要的创新在于将超参数选择与多臂赌博机理论结合,提出了UCBSpec和EXP3Spec两种算法,能够在不同奖励设置下优化选择过程,且UCBSpec的遗憾性能达到了最优。
关键设计:在算法设计中,采用了停止时间遗憾作为性能评估指标,并在随机和对抗环境下进行了理论分析,确保算法在多种场景下的有效性和鲁棒性。实验中使用了LLaMA3和Qwen2模型进行验证。
🖼️ 关键图片


📊 实验亮点
实验结果显示,BanditSpec在LLaMA3和Qwen2模型上的吞吐量接近于最佳超参数,且在多种输入提示下表现优异,相较于现有方法提升了推理效率,验证了算法的有效性和实用性。
🎯 应用场景
该研究的潜在应用场景包括大语言模型的实时推理系统,如聊天机器人、智能助手和内容生成工具。通过自适应的超参数选择,能够显著提升这些系统的响应速度和生成质量,具有广泛的实际价值和未来影响。
📄 摘要(原文)
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.