The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
作者: Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, Hao Peng
分类: cs.LG, cs.AI
发布日期: 2025-05-21
💡 一句话要点
熵最小化显著提升LLM推理能力,无需标注数据
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 熵最小化 大型语言模型 推理能力 无监督学习 强化学习
📋 核心要点
- 现有方法在提升LLM推理能力时依赖大量标注数据,成本高昂且泛化性受限。
- 论文提出熵最小化方法,通过引导模型输出更自信的结果来提升推理能力,无需标注数据。
- 实验表明,该方法在数学、物理和编码任务上显著提升了LLM的性能,甚至超越了部分商业模型。
📝 摘要(中文)
本文提出熵最小化(EM)方法,旨在训练模型更加集中地将概率质量分配给其最自信的输出。研究表明,仅使用这一简单目标,无需任何标注数据,就能显著提高大型语言模型(LLM)在具有挑战性的数学、物理和编码任务上的性能。文章探索了三种方法:(1)EM-FT,类似于指令微调,但在从模型中抽取的未标注输出上最小化token级别的熵;(2)EM-RL,使用负熵作为唯一的奖励来最大化进行强化学习;(3)EM-INF,推理时调整logits以减少熵,无需任何训练数据或参数更新。在Qwen-7B上,EM-RL在没有任何标注数据的情况下,实现了与在60K标注样本上训练的GRPO和RLOO等强强化学习基线相当甚至更好的性能。此外,EM-INF使Qwen-32B在具有挑战性的SciCode基准测试中,达到或超过了GPT-4o、Claude 3 Opus和Gemini 1.5 Pro等专有模型的性能,同时比自洽性和顺序细化方法效率高3倍。研究结果表明,许多预训练的LLM具有先前未被充分认识的推理能力,仅通过熵最小化就能有效地激发这些能力,而无需任何标注数据甚至任何参数更新。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂推理任务中表现不佳的问题。现有方法通常依赖于大量的标注数据进行微调或强化学习,这不仅成本高昂,而且可能限制模型的泛化能力。因此,如何在不依赖标注数据的情况下,有效提升LLM的推理能力是一个重要的挑战。
核心思路:论文的核心思路是利用熵最小化(Entropy Minimization, EM)原则。EM鼓励模型生成更加自信的输出,即模型倾向于将更高的概率分配给它认为最正确的答案。通过减少输出概率分布的熵,可以促使模型更加明确地表达其推理结果,从而提高推理的准确性。
技术框架:论文提出了三种基于熵最小化的方法:EM-FT(Entropy Minimization Fine-Tuning)、EM-RL(Entropy Minimization Reinforcement Learning)和EM-INF(Entropy Minimization Inference)。EM-FT类似于指令微调,但在未标注数据上进行;EM-RL使用负熵作为强化学习的奖励信号;EM-INF则是在推理阶段调整logits以降低熵,无需训练。
关键创新:该论文的关键创新在于证明了熵最小化本身可以作为一种有效的训练或推理目标,无需任何标注数据即可显著提升LLM的推理能力。与传统的监督学习或强化学习方法相比,该方法更加高效且具有更强的泛化潜力。EM-INF方法尤其具有吸引力,因为它可以在不更新模型参数的情况下,直接提升模型的推理性能。
关键设计:EM-FT的关键在于如何生成高质量的未标注数据,以及如何有效地最小化token级别的熵。EM-RL的关键在于如何设计合适的奖励函数,以平衡探索和利用。EM-INF的关键在于如何选择合适的logit调整策略,以在降低熵的同时,避免过度自信导致错误。
🖼️ 关键图片
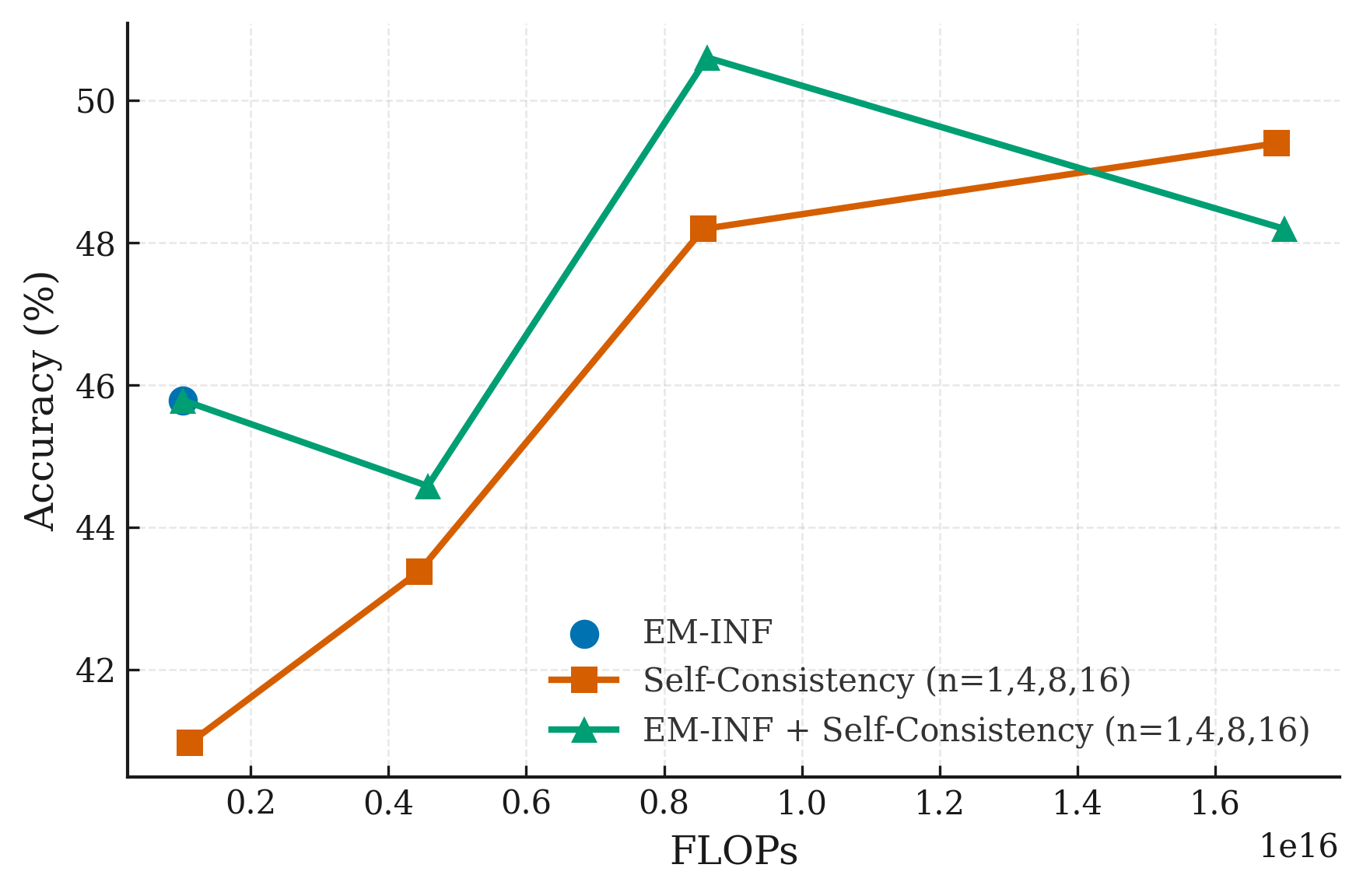
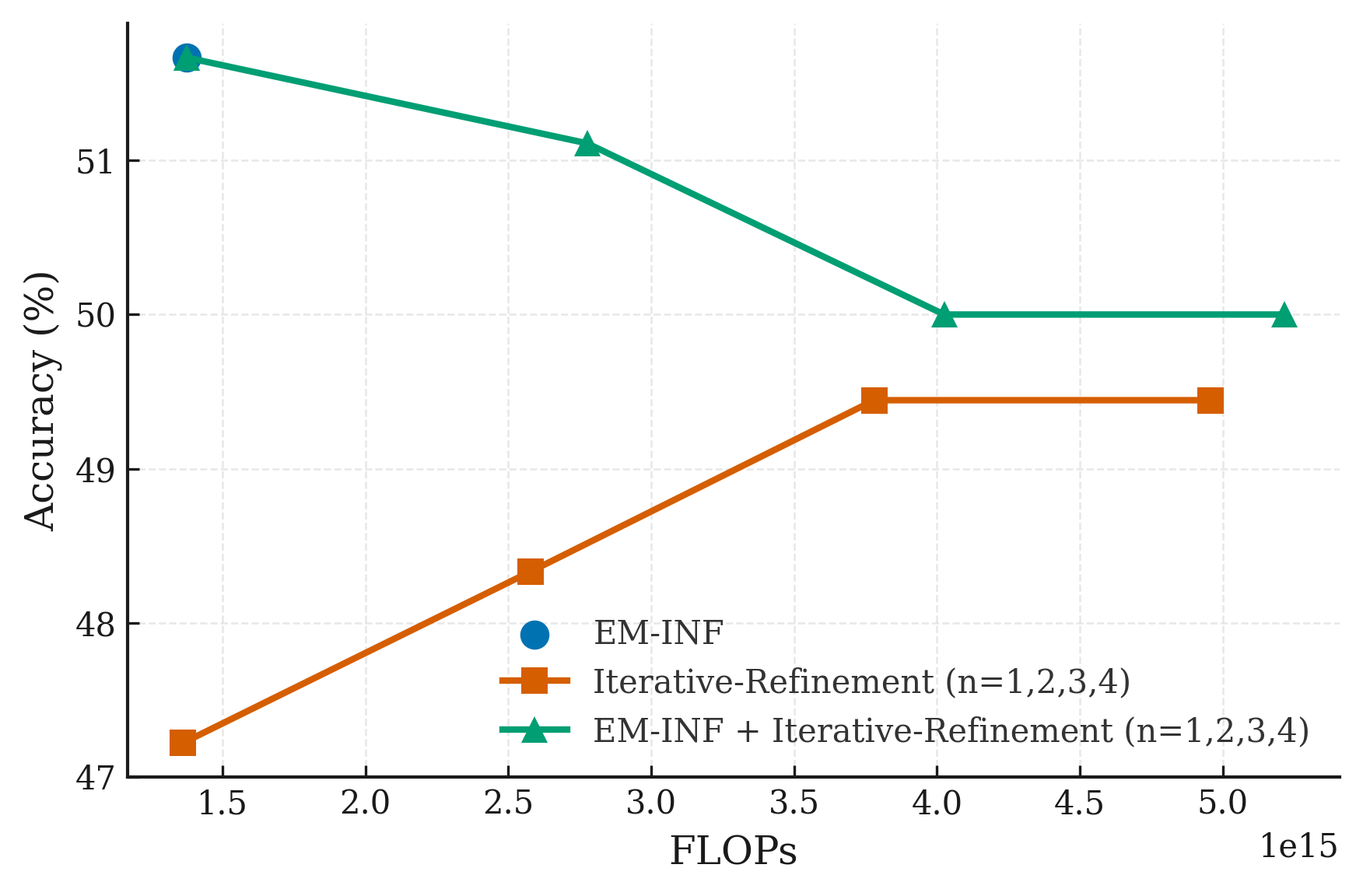

📊 实验亮点
EM-RL在Qwen-7B上,无需任何标注数据,性能可与使用60K标注样本训练的GRPO和RLOO等强化学习基线媲美甚至超越。EM-INF使Qwen-32B在SciCode基准测试中,达到或超过了GPT-4o、Claude 3 Opus和Gemini 1.5 Pro等专有模型的性能,同时比自洽性和顺序细化方法效率高3倍。这些结果表明,熵最小化是一种非常有效的LLM推理能力提升方法。
🎯 应用场景
该研究成果可广泛应用于各种需要复杂推理能力的场景,例如科学计算、代码生成、数学问题求解等。通过熵最小化,可以提升LLM在这些领域的应用效果,降低对标注数据的依赖,并加速LLM在实际问题中的部署。此外,该方法还可以作为一种通用的模型优化策略,与其他技术相结合,进一步提升LLM的性能。
📄 摘要(原文)
Entropy minimization (EM) trains the model to concentrate even more probability mass on its most confident outputs. We show that this simple objective alone, without any labeled data, can substantially improve large language models' (LLMs) performance on challenging math, physics, and coding tasks. We explore three approaches: (1) EM-FT minimizes token-level entropy similarly to instruction finetuning, but on unlabeled outputs drawn from the model; (2) EM-RL: reinforcement learning with negative entropy as the only reward to maximize; (3) EM-INF: inference-time logit adjustment to reduce entropy without any training data or parameter updates. On Qwen-7B, EM-RL, without any labeled data, achieves comparable or better performance than strong RL baselines such as GRPO and RLOO that are trained on 60K labeled examples. Furthermore, EM-INF enables Qwen-32B to match or exceed the performance of proprietary models like GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro on the challenging SciCode benchmark, while being 3x more efficient than self-consistency and sequential refinement. Our findings reveal that many pretrained LLMs possess previously underappreciated reasoning capabilities that can be effectively elicited through entropy minimization alone, without any labeled data or even any parameter updates.