RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning
作者: Kaiwen Zha, Zhengqi Gao, Maohao Shen, Zhang-Wei Hong, Duane S. Boning, Dina Katabi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-21 (更新: 2025-10-23)
备注: NeurIPS 2025. The first two authors contributed equally
🔗 代码/项目: GITHUB
💡 一句话要点
提出RL Tango,通过强化学习协同训练生成器和验证器,提升LLM的语言推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 语言推理 大型语言模型 生成式验证器 协同训练 奖励模型 领域外泛化
📋 核心要点
- 现有LLM推理的强化学习方法依赖固定或监督微调的验证器,易受奖励操纵且泛化性差。
- Tango框架通过强化学习交错训练LLM生成器和验证器,验证器以生成方式评估过程,无需显式标注。
- 实验表明,Tango在数学推理和领域外推理任务上均取得SOTA结果,尤其在难题上提升显著。
📝 摘要(中文)
强化学习(RL)最近成为增强大型语言模型(LLM)推理能力的有效方法,其中LLM生成器作为策略,由验证器(奖励模型)引导。然而,目前LLM的RL后训练方法通常使用固定的(基于规则或冻结的预训练)或通过监督微调(SFT)判别式训练的验证器。这种设计容易受到奖励黑客的影响,并且在训练分布之外泛化能力较差。为了克服这些限制,我们提出了Tango,这是一个新颖的框架,它使用RL以交错的方式同时训练LLM生成器和验证器。Tango的核心创新是其生成式的、过程级别的LLM验证器,该验证器通过RL训练并与生成器共同进化。重要的是,验证器仅基于结果级别的验证正确性奖励进行训练,而不需要显式的过程级别注释。与确定性或SFT训练的验证器相比,这种生成式RL训练的验证器表现出更好的鲁棒性和更强的泛化能力,从而促进了与生成器的有效相互强化。大量的实验表明,Tango的两个组件都在7B/8B规模的模型中取得了最先进的结果:生成器在五个竞赛级别的数学基准测试和四个具有挑战性的领域外推理任务中获得了同类最佳的性能,而验证器在ProcessBench数据集上处于领先地位。值得注意的是,这两个组件在最困难的数学推理问题上都表现出特别显著的改进。代码位于:https://github.com/kaiwenzha/rl-tango。
🔬 方法详解
问题定义:现有基于强化学习的LLM推理方法,其验证器通常是固定的(如规则或预训练模型)或通过监督微调得到。这些验证器容易被生成器利用,导致奖励欺骗(reward hacking),并且在训练数据之外的泛化能力较差。因此,如何训练一个更鲁棒、泛化能力更强的验证器,是本文要解决的核心问题。
核心思路:Tango的核心思路是同时训练生成器和验证器,让它们在强化学习过程中相互促进、共同进化。验证器不再是固定的或通过监督学习训练的,而是通过强化学习进行训练,并且以生成的方式评估推理过程,从而避免了对过程标注的依赖,提高了鲁棒性和泛化能力。
技术框架:Tango框架包含一个LLM生成器和一个LLM验证器。生成器负责生成推理过程,验证器负责评估生成过程的正确性并给出奖励信号。生成器和验证器都通过强化学习进行训练,并且训练过程是交错进行的:首先,固定验证器,训练生成器;然后,固定生成器,训练验证器。这个过程不断迭代,直到生成器和验证器都达到较好的性能。
关键创新:Tango最重要的创新点在于其生成式的、过程级别的LLM验证器。传统的验证器通常是判别式的,只能判断最终结果是否正确,而Tango的验证器可以生成对推理过程的评估,从而提供更细粒度的反馈信号。此外,Tango的验证器是通过强化学习训练的,不需要显式的过程标注,从而降低了训练成本,提高了泛化能力。
关键设计:Tango使用PPO(Proximal Policy Optimization)算法来训练生成器和验证器。验证器的奖励函数基于验证正确性,即验证器生成的评估与真实评估一致时,给予奖励。为了鼓励验证器探索不同的评估方式,Tango还引入了一个熵正则化项。生成器的奖励函数基于验证器的评估结果,即验证器认为生成器生成的推理过程是正确的,给予奖励。此外,Tango还使用了一种课程学习策略,即先训练生成器解决简单的推理问题,然后再训练生成器解决复杂的推理问题。
🖼️ 关键图片
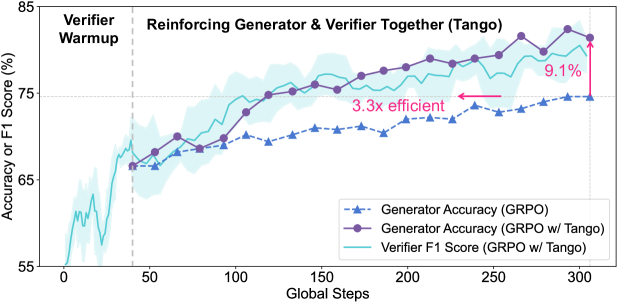
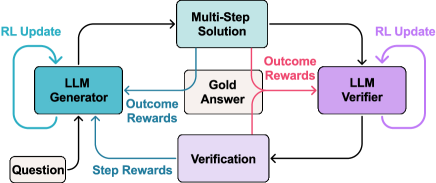

📊 实验亮点
实验结果表明,Tango在五个竞赛级别的数学基准测试和四个具有挑战性的领域外推理任务中取得了SOTA结果。例如,在MATH数据集上,Tango的生成器取得了显著的性能提升。此外,Tango的验证器在ProcessBench数据集上也取得了领先地位,证明了其在过程评估方面的优势。值得注意的是,Tango在最困难的数学推理问题上表现出特别显著的改进。
🎯 应用场景
RL Tango框架可应用于各种需要语言推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。通过协同训练生成器和验证器,可以提高LLM的推理准确性和鲁棒性,从而在教育、科研、金融等领域发挥重要作用。未来,该框架还可以扩展到其他模态,例如视觉推理和多模态推理。
📄 摘要(原文)
Reinforcement learning (RL) has recently emerged as a compelling approach for enhancing the reasoning capabilities of large language models (LLMs), where an LLM generator serves as a policy guided by a verifier (reward model). However, current RL post-training methods for LLMs typically use verifiers that are fixed (rule-based or frozen pretrained) or trained discriminatively via supervised fine-tuning (SFT). Such designs are susceptible to reward hacking and generalize poorly beyond their training distributions. To overcome these limitations, we propose Tango, a novel framework that uses RL to concurrently train both an LLM generator and a verifier in an interleaved manner. A central innovation of Tango is its generative, process-level LLM verifier, which is trained via RL and co-evolves with the generator. Importantly, the verifier is trained solely based on outcome-level verification correctness rewards without requiring explicit process-level annotations. This generative RL-trained verifier exhibits improved robustness and superior generalization compared to deterministic or SFT-trained verifiers, fostering effective mutual reinforcement with the generator. Extensive experiments demonstrate that both components of Tango achieve state-of-the-art results among 7B/8B-scale models: the generator attains best-in-class performance across five competition-level math benchmarks and four challenging out-of-domain reasoning tasks, while the verifier leads on the ProcessBench dataset. Remarkably, both components exhibit particularly substantial improvements on the most difficult mathematical reasoning problems. Code is at: https://github.com/kaiwenzha/rl-tango.