Output Scaling: YingLong-Delayed Chain of Thought in a Large Pretrained Time Series Forecasting Model
作者: Xue Wang, Tian Zhou, Jinyang Gao, Bolin Ding, Jingren Zhou
分类: cs.LG, cs.AI
发布日期: 2025-05-20
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出YingLong,通过非因果CoT在时间序列预测中实现显著的输出尺度效应。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 Transformer 非因果模型 思维链 预训练模型 零样本学习 输出尺度效应
📋 核心要点
- 传统时间序列预测方法(直接或递归)在长序列预测中存在误差累积和泛化性不足的问题。
- YingLong采用非因果双向Transformer架构,通过掩码token恢复进行预训练,并利用延迟CoT推理提升长序列预测精度。
- 实验表明,YingLong在ETT、Weather和GIFT-Eval等数据集上取得了显著的性能提升,尤其在零样本学习方面。
📝 摘要(中文)
本文提出了一种用于时间序列预测的联合预测框架,该框架与传统的直接或递归方法形成对比。该框架为我们设计的基座模型YingLong实现了最先进的性能,并揭示了一种新的尺度效应:由于非因果方法中延迟的思维链(Chain-of-Thought)推理,更长的输出显著提高了模型精度。YingLong是一个非因果的、双向注意力编码器Transformer,通过掩码token恢复进行训练,与语言理解任务的对齐效果优于生成任务。此外,我们通过使用多输入集成来解决输出方差问题,从而提高了性能。我们发布了四个参数量从6M到300M的基座模型,在ETT和Weather数据集上的零样本任务中表现出卓越的结果。YingLong实现了超过60%的最佳性能。为了确保泛化性,我们使用GIFT-Eval基准评估了这些模型,该基准包含来自7个领域的23个时间序列数据集。Yinglong在排名方面显著优于最佳时间序列基座模型和端到端训练模型,分别提升了14%和44%。预训练的300M模型可在https://huggingface.co/qcw1314/YingLong_300m 获取。
🔬 方法详解
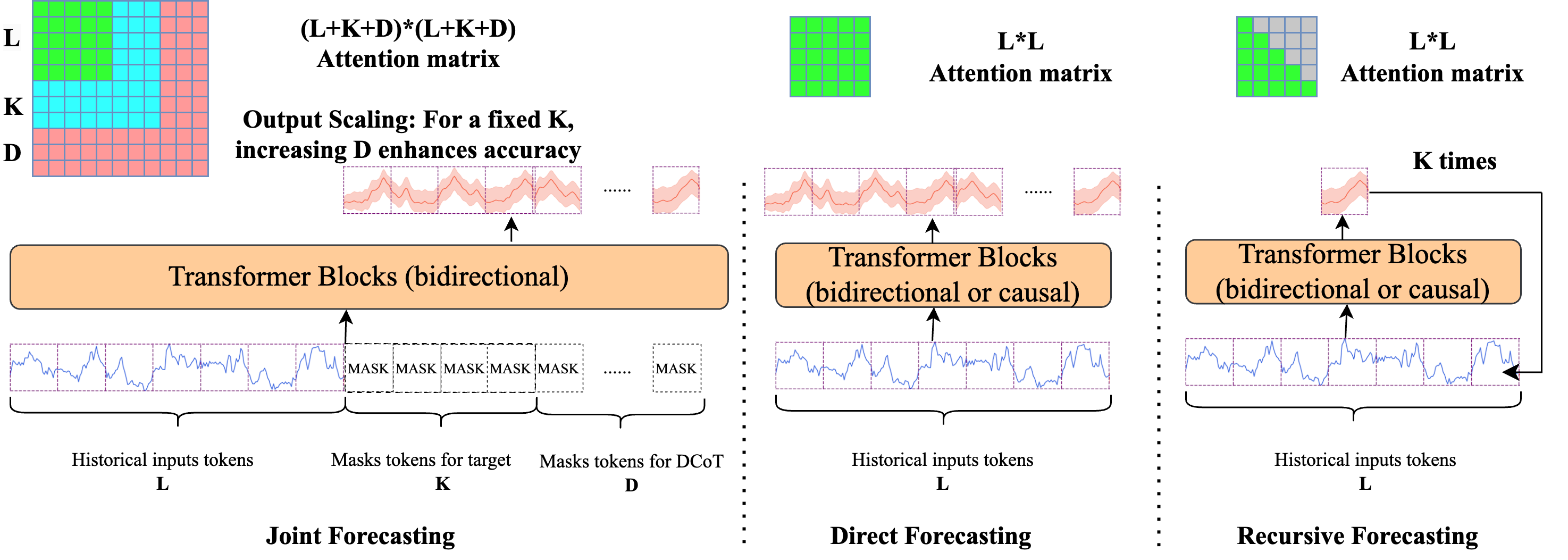
问题定义:论文旨在解决时间序列预测问题,特别是长序列预测的精度问题。现有方法,如直接预测和递归预测,在长序列预测中容易出现误差累积,并且泛化能力有限。此外,现有方法通常是因果的,无法利用未来信息进行预测。
核心思路:论文的核心思路是利用非因果的双向Transformer架构,通过掩码token恢复进行预训练,从而学习时间序列的上下文信息。此外,论文发现,更长的输出可以显著提高模型精度,这是由于模型在预测过程中进行了延迟的思维链(Chain-of-Thought)推理。
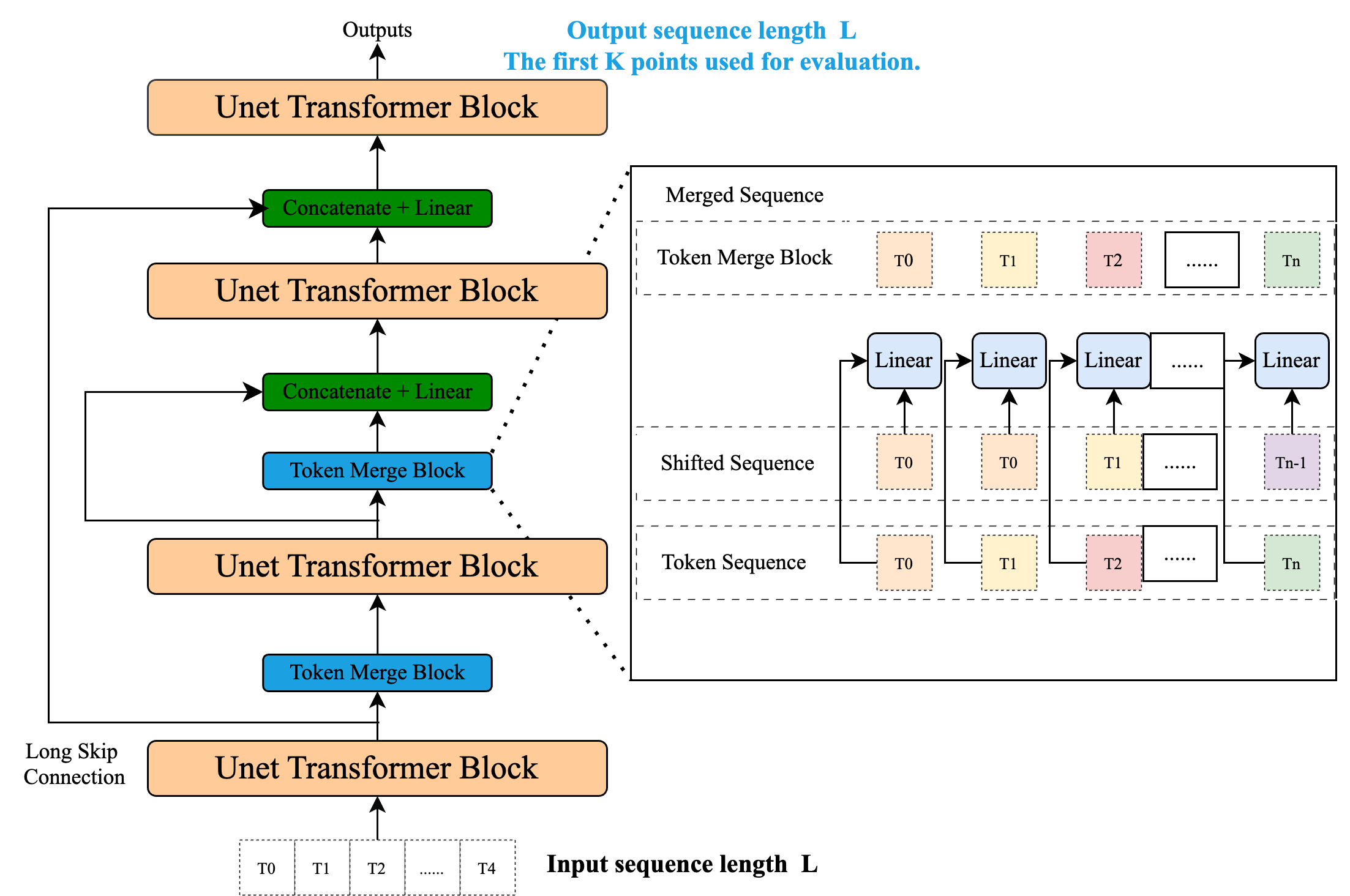
技术框架:YingLong模型是一个基于Transformer的编码器-only架构,使用双向注意力机制。模型首先通过掩码token恢复任务进行预训练,学习时间序列的表示。然后,模型可以用于零样本时间序列预测。为了提高预测的鲁棒性,论文还采用了多输入集成方法,即使用多个不同的输入来预测同一个输出,并将多个预测结果进行平均。
关键创新:论文的关键创新点在于:1) 提出了一种非因果的时间序列预测模型,可以利用未来信息进行预测;2) 发现了一种新的尺度效应,即更长的输出可以显著提高模型精度,这是由于模型进行了延迟的思维链推理。与现有方法的本质区别在于,YingLong不是一个因果模型,并且能够进行更复杂的推理。
关键设计:YingLong模型的关键设计包括:1) 使用双向注意力机制,允许模型同时关注过去和未来的信息;2) 使用掩码token恢复任务进行预训练,迫使模型学习时间序列的上下文信息;3) 采用多输入集成方法,提高预测的鲁棒性。论文中使用的损失函数是标准的交叉熵损失函数,用于衡量模型预测的token与真实token之间的差异。
🖼️ 关键图片

📊 实验亮点
YingLong模型在ETT和Weather数据集上取得了超过60%的最佳性能,并在GIFT-Eval基准测试中显著优于其他时间序列基座模型和端到端训练模型,分别提升了14%和44%(基于排名)。这些结果表明,YingLong模型具有很强的泛化能力和优越的预测性能。
🎯 应用场景
该研究成果可广泛应用于各种时间序列预测场景,例如金融市场预测、天气预报、电力负荷预测、交通流量预测等。通过提高预测精度,可以帮助企业和个人做出更明智的决策,从而提高效率和降低风险。未来,该研究可以进一步扩展到多变量时间序列预测和异常检测等领域。
📄 摘要(原文)
We present a joint forecasting framework for time series prediction that contrasts with traditional direct or recursive methods. This framework achieves state-of-the-art performance for our designed foundation model, YingLong, and reveals a novel scaling effect: longer outputs significantly enhance model accuracy due to delayed chain-of-thought reasoning in our non-causal approach. YingLong is a non-causal, bidirectional attention encoder-only transformer trained through masked token recovery, aligning more effectively with language understanding tasks than with generation tasks. Additionally, we boost performance by tackling output variance with a multi-input ensemble. We release four foundation models ranging from 6M to 300M parameters, demonstrating superior results in zero-shot tasks on the ETT and Weather datasets. YingLong achieves more than 60% best performance. To ensure generalizability, we assessed the models using the GIFT-Eval benchmark, which comprises 23 time series datasets across 7 domains. Yinglong significantly outperformed the best time-series foundation models, end-to-end trained models by 14% and 44% in rank respectively.The pretrained 300M model is available at https://huggingface.co/qcw1314/YingLong_300m