Acoustic and Machine Learning Methods for Speech-Based Suicide Risk Assessment: A Systematic Review
作者: Ambre Marie, Marine Garnier, Thomas Bertin, Laura Machart, Guillaume Dardenne, Gwenolé Quellec, Sofian Berrouiguet
分类: eess.AS, cs.LG, cs.SD
发布日期: 2025-05-20 (更新: 2025-10-28)
备注: Preprint version of a manuscript submitted to the Journal of Affective Disorders
💡 一句话要点
利用语音声学特征和机器学习进行自杀风险评估的系统性综述
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自杀风险评估 语音分析 机器学习 声学特征 多模态融合
📋 核心要点
- 自杀风险评估面临挑战,现有方法在早期准确识别高危人群方面存在不足。
- 该综述聚焦语音声学特征,探索机器学习模型在自杀风险预测中的潜力。
- 研究发现声学特征在风险人群中存在显著差异,多模态融合提升了预测性能。
📝 摘要(中文)
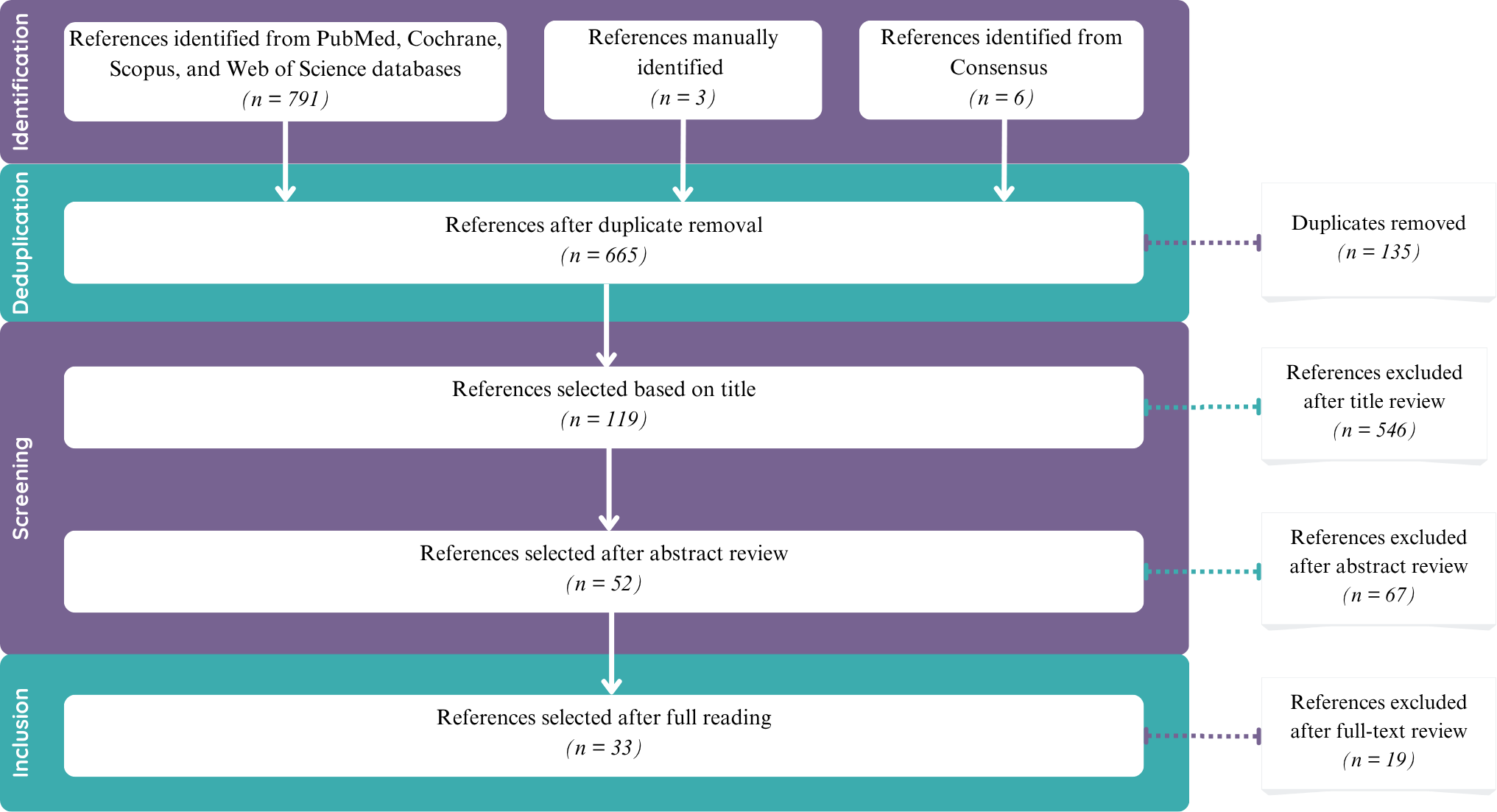
自杀仍然是一个公共健康挑战,需要改进检测方法以促进及时干预和治疗。本系统综述评估了人工智能(AI)和机器学习(ML)在通过语音声学分析评估自杀风险中的作用。遵循PRISMA指南,我们分析了从PubMed、Cochrane、Scopus和Web of Science数据库中选择的33篇文章。最近一次检索是在2025年2月进行的。使用PROBAST工具评估了偏倚风险。研究纳入了分析有自杀风险(RS)个体和无自杀风险(NRS)个体之间声学特征的研究,排除了缺乏声学数据、与自杀无关或缺乏足够方法学细节的研究。样本量差异很大,并根据研究以参与者或语音片段报告。基于声学特征和分类器性能对结果进行了叙述性综合。研究结果一致表明,RS和NRS人群之间存在显著的声学特征差异,特别是涉及抖动、基频(F0)、梅尔频率倒谱系数(MFCC)和功率谱密度(PSD)。分类器性能因算法、模态和语音引出方法而异,其中整合声学、语言和元数据特征的多模态方法表现出优越的性能。在29项基于分类器的研究中,报告的AUC值范围为0.62至0.985,准确率范围为60%至99.85%。大多数数据集在NRS方面是不平衡的,并且很少按组单独报告性能指标,限制了对效应方向的清晰识别。
🔬 方法详解
问题定义:该论文旨在解决自杀风险的早期和准确评估问题。现有方法,如传统的问卷调查和临床访谈,存在主观性强、耗时、难以大规模应用等痛点。利用语音作为一种非侵入式的生物标志物,结合机器学习技术,有望实现更客观、高效的自杀风险评估。
核心思路:核心思路是利用语音中蕴含的声学信息,这些信息可能反映了个体的情绪状态、生理压力等,从而与自杀风险相关联。通过提取语音的声学特征,并训练机器学习模型,可以学习到RS(有自杀风险)和NRS(无自杀风险)个体之间的差异,进而实现自杀风险的预测。
技术框架:整体框架包括数据收集、预处理、特征提取、模型训练和评估几个主要阶段。首先,收集RS和NRS个体的语音数据。然后,对语音数据进行预处理,例如降噪、标准化等。接着,提取语音的声学特征,例如基频、梅尔频率倒谱系数等。最后,使用机器学习算法(如支持向量机、随机森林等)训练分类模型,并使用交叉验证等方法评估模型的性能。
关键创新:关键创新在于将语音声学分析与机器学习相结合,用于自杀风险评估。与传统的评估方法相比,该方法具有客观、高效、可扩展等优点。此外,多模态融合也是一个重要的创新点,即将声学特征与语言特征、元数据等相结合,可以进一步提高预测的准确性。
关键设计:关键设计包括声学特征的选择、机器学习算法的选择、以及模型评估指标的选择。常用的声学特征包括基频(F0)、抖动(jitter)、梅尔频率倒谱系数(MFCC)、功率谱密度(PSD)等。常用的机器学习算法包括支持向量机(SVM)、随机森林(Random Forest)、深度神经网络(DNN)等。常用的模型评估指标包括准确率(Accuracy)、AUC(Area Under the Curve)、精确率(Precision)、召回率(Recall)等。此外,数据集的平衡性也是一个重要的考虑因素,需要采取相应的措施来处理不平衡数据集。
🖼️ 关键图片
📊 实验亮点
该综述分析了29项基于分类器的研究,AUC值范围为0.62至0.985,准确率范围为60%至99.85%。多模态方法,即整合声学、语言和元数据特征的方法,表现出更优越的性能。研究结果表明,语音声学特征在自杀风险评估中具有重要价值。
🎯 应用场景
该研究成果可应用于心理健康服务、危机干预中心、在线心理咨询平台等场景,实现对潜在自杀风险人群的早期筛查和干预。通过集成到智能手机应用或可穿戴设备中,可以实现对个体自杀风险的实时监测和预警,为预防自杀提供新的技术手段。
📄 摘要(原文)
Suicide remains a public health challenge, necessitating improved detection methods to facilitate timely intervention and treatment. This systematic review evaluates the role of Artificial Intelligence (AI) and Machine Learning (ML) in assessing suicide risk through acoustic analysis of speech. Following PRISMA guidelines, we analyzed 33 articles selected from PubMed, Cochrane, Scopus, and Web of Science databases. The last search was conducted in February 2025. Risk of bias was assessed using the PROBAST tool. Studies analyzing acoustic features between individuals at risk of suicide (RS) and those not at risk (NRS) were included, while studies lacking acoustic data, a suicide-related focus, or sufficient methodological details were excluded. Sample sizes varied widely and were reported in terms of participants or speech segments, depending on the study. Results were synthesized narratively based on acoustic features and classifier performance. Findings consistently showed significant acoustic feature variations between RS and NRS populations, particularly involving jitter, fundamental frequency (F0), Mel-frequency cepstral coefficients (MFCC), and power spectral density (PSD). Classifier performance varied based on algorithms, modalities, and speech elicitation methods, with multimodal approaches integrating acoustic, linguistic, and metadata features demonstrating superior performance. Among the 29 classifier-based studies, reported AUC values ranged from 0.62 to 0.985 and accuracies from 60% to 99.85%. Most datasets were imbalanced in favor of NRS, and performance metrics were rarely reported separately by group, limiting clear identification of direction of effect.