Foundations of Unknown-aware Machine Learning
作者: Xuefeng Du
分类: cs.LG
发布日期: 2025-05-20
备注: PhD Dissertation
💡 一句话要点
提出未知感知机器学习框架,提升开放世界中AI模型的可靠性与安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 未知感知学习 分布外检测 异常值合成 大型语言模型安全 多模态模型安全
📋 核心要点
- 现有机器学习模型在开放世界中面临分布偏移和未知类别带来的挑战,导致对分布外数据预测置信度过高。
- 论文提出未知感知学习框架,通过优化模型在分布内准确性和分布外可靠性,使模型能够识别和处理未知输入。
- 论文开发了多种方法,包括异常值合成、利用未标记数据增强OOD检测,以及针对LLM和多模态模型的安全工具。
📝 摘要(中文)
本论文致力于解决开放世界部署中机器学习模型的可靠性和安全性问题,这是人工智能安全的核心挑战。论文开发了算法和理论基础,以应对由分布不确定性和未知类别引起的关键可靠性问题,涵盖了从标准神经网络到大型语言模型(LLMs)等现代基础模型。传统的学习范式,如经验风险最小化(ERM),假设训练和推理之间没有分布偏移,这通常导致模型对分布外(OOD)输入产生过度自信的预测。本论文引入了新的框架,联合优化模型在分布内数据的准确性和对未知数据的可靠性。核心贡献在于开发了一种未知感知学习框架,使模型能够识别和处理新的输入,而无需标记的OOD数据。此外,论文还提出了用于LLM幻觉检测的HaloScope,用于防御多模态模型中恶意提示的MLLMGuard,以及用于清理人类反馈数据以实现更好对齐的数据清洗方法。这些工具针对威胁大规模模型部署安全性的失效模式。
🔬 方法详解
问题定义:论文旨在解决机器学习模型在开放世界部署时,由于训练数据与实际应用场景存在分布差异,以及模型无法识别未知类别输入而导致的可靠性和安全性问题。现有方法,如经验风险最小化(ERM),在面对分布外(OOD)数据时,往往会产生过度自信的错误预测,无法有效识别和处理未知输入。
核心思路:论文的核心思路是构建一个“未知感知”的学习框架,使模型不仅能够准确预测训练数据中的类别,还能识别和处理未知的、分布外的数据。这通过在训练过程中引入对未知数据的建模和优化来实现,从而提高模型在实际部署中的鲁棒性和可靠性。
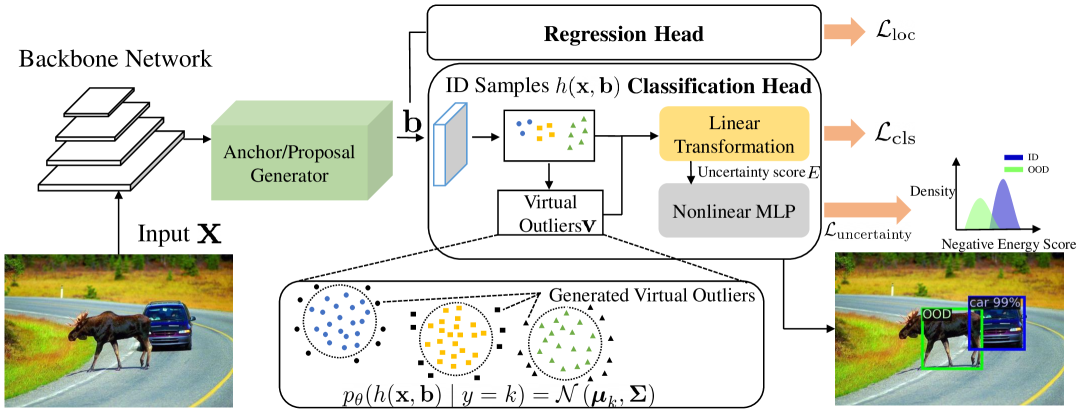
技术框架:论文提出的框架包含多个关键模块。首先,通过异常值合成方法(VOS, NPOS, DREAM-OOD)生成具有信息量的未知数据,用于训练模型区分已知和未知输入。其次,利用未标记的“野外”数据,通过SAL框架增强OOD检测能力,使其适应真实部署条件。最后,针对大型语言模型(LLM)和多模态模型,开发了HaloScope和MLLMGuard等工具,用于检测幻觉和防御恶意提示。
关键创新:论文的关键创新在于提出了一个完整的未知感知学习范式,从数据生成、模型训练到安全工具开发,全面提升了模型在开放世界中的可靠性。与传统方法相比,该框架不需要预先标记的OOD数据,而是通过合成和利用未标记数据来学习区分已知和未知,更符合实际应用场景。
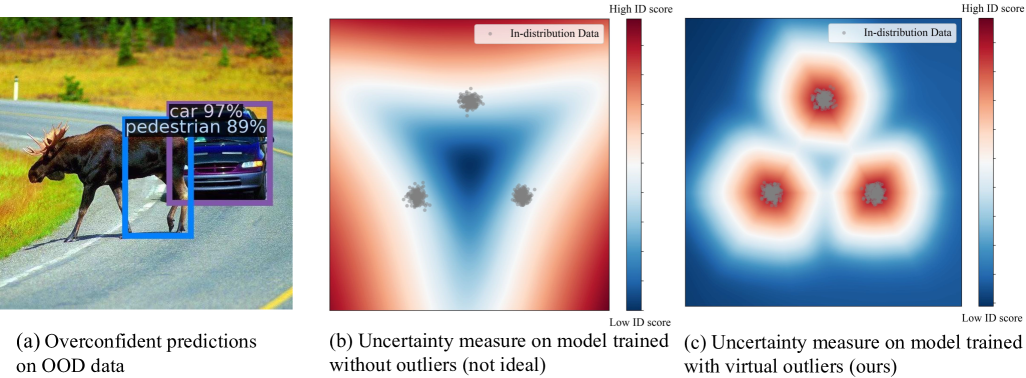
关键设计:异常值合成方法(VOS, NPOS, DREAM-OOD)的设计目标是生成具有挑战性的、能够有效区分已知和未知的数据。SAL框架的关键在于如何利用未标记数据来提升OOD检测的准确性和鲁棒性,可能涉及到自监督学习、对比学习等技术。HaloScope和MLLMGuard等安全工具则需要针对LLM和多模态模型的特点进行设计,例如,HaloScope可能利用模型内部的置信度信息或外部知识库来检测幻觉,MLLMGuard可能采用对抗训练或输入过滤等方法来防御恶意提示。
🖼️ 关键图片

📊 实验亮点
论文提出了多种创新方法,并在多个数据集上进行了实验验证。例如,提出的异常值合成方法能够有效提升OOD检测的准确率,利用未标记数据进行OOD检测的方法在真实场景下表现出良好的鲁棒性。针对LLM和多模态模型的安全工具也取得了显著的效果,能够有效检测幻觉和防御恶意提示。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、医疗诊断、金融风控等对安全性要求极高的领域。通过提高模型对未知情况的识别和处理能力,可以有效降低误判风险,提升系统的整体可靠性。未来,该研究有望推动人工智能在开放环境中的安全部署和应用,减少人为干预,实现更智能、更可靠的AI系统。
📄 摘要(原文)
Ensuring the reliability and safety of machine learning models in open-world deployment is a central challenge in AI safety. This thesis develops both algorithmic and theoretical foundations to address key reliability issues arising from distributional uncertainty and unknown classes, from standard neural networks to modern foundation models like large language models (LLMs). Traditional learning paradigms, such as empirical risk minimization (ERM), assume no distribution shift between training and inference, often leading to overconfident predictions on out-of-distribution (OOD) inputs. This thesis introduces novel frameworks that jointly optimize for in-distribution accuracy and reliability to unseen data. A core contribution is the development of an unknown-aware learning framework that enables models to recognize and handle novel inputs without labeled OOD data. We propose new outlier synthesis methods, VOS, NPOS, and DREAM-OOD, to generate informative unknowns during training. Building on this, we present SAL, a theoretical and algorithmic framework that leverages unlabeled in-the-wild data to enhance OOD detection under realistic deployment conditions. These methods demonstrate that abundant unlabeled data can be harnessed to recognize and adapt to unforeseen inputs, providing formal reliability guarantees. The thesis also extends reliable learning to foundation models. We develop HaloScope for hallucination detection in LLMs, MLLMGuard for defending against malicious prompts in multimodal models, and data cleaning methods to denoise human feedback used for better alignment. These tools target failure modes that threaten the safety of large-scale models in deployment. Overall, these contributions promote unknown-aware learning as a new paradigm, and we hope it can advance the reliability of AI systems with minimal human efforts.