Polar Sparsity: High Throughput Batched LLM Inferencing with Scalable Contextual Sparsity
作者: Susav Shrestha, Brad Settlemyer, Nikoli Dryden, Narasimha Reddy
分类: cs.LG, cs.AI
发布日期: 2025-05-20 (更新: 2025-11-11)
备注: NeurIPS 2025, 10 pages, 7 figures
🔗 代码/项目: GITHUB
💡 一句话要点
Polar Sparsity:通过可扩展的上下文稀疏性实现高吞吐量批量LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理 上下文稀疏性 Attention机制 模型加速 批量处理 GPU内核 Selective Head Attention
📋 核心要点
- 现有上下文稀疏方法在大型batch size下性能不佳,因为活跃神经元的联合迅速趋近于密集计算,限制了扩展性。
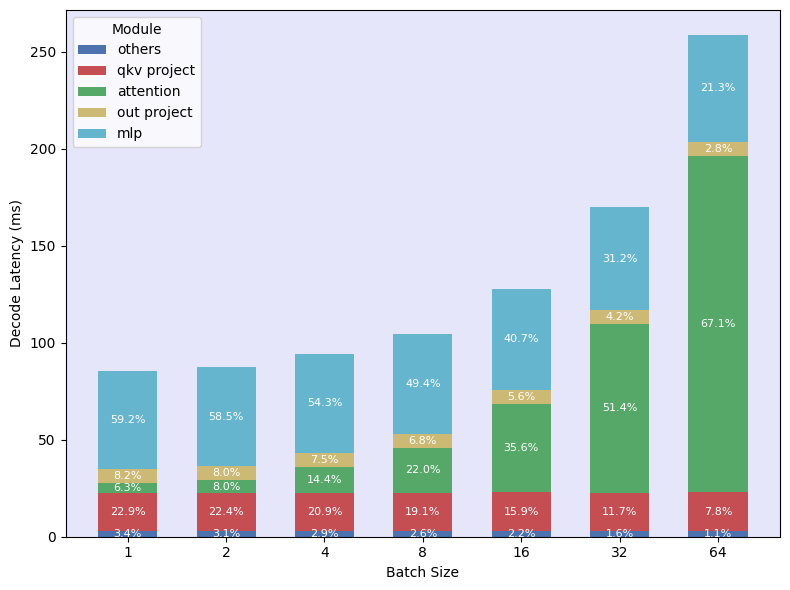
- Polar Sparsity的核心思想是利用Attention层在大型batch size下仍然保持稳定的head稀疏性,而MLP层的稀疏性则消失。
- 通过Selective Head Attention和稀疏感知GPU内核,Polar Sparsity在多个LLM模型上实现了高达2.2倍的端到端加速,且精度无损。
📝 摘要(中文)
加速大型语言模型(LLM)的推理对于需要高吞吐量和低延迟的实际部署至关重要。上下文稀疏性,即每个token动态激活模型参数的一个小子集,显示出前景,但由于活跃神经元的联合迅速接近密集计算,因此无法扩展到大型batch size。我们引入了Polar Sparsity,强调了随着batch size和序列长度的增加,稀疏性重要性从MLP层到Attention层的关键转变。虽然MLP层在batch处理下变得更具计算效率,但它们的稀疏性消失了。相比之下,attention在规模上变得越来越昂贵,而它们的head稀疏性保持稳定且与batch无关。我们开发了具有硬件高效、稀疏感知GPU内核的Selective Head Attention,为OPT、LLaMA-2&3、Qwen、Mistral等模型在各种batch size和序列长度上提供高达2.2倍的端到端加速,且不影响准确性。据我们所知,这是第一个证明上下文稀疏性可以有效扩展到大型batch size的工作,以最小的更改提供显着的推理加速,使Polar Sparsity适用于大规模、高吞吐量LLM部署系统。我们的代码可在https://github.com/susavlsh10/Polar-Sparsity获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理中,上下文稀疏性方法在大型batch size下扩展性差的问题。现有方法在处理大型batch size时,由于需要激活的神经元数量迅速增加,导致计算量逼近密集计算,无法有效利用稀疏性带来的加速优势。
核心思路:论文的核心思路是观察到在大型batch size下,MLP层的稀疏性逐渐消失,而Attention层的head稀疏性仍然保持稳定。因此,论文提出专注于利用Attention层的稀疏性来实现加速,避免了对MLP层进行稀疏化处理带来的性能瓶颈。这种设计基于对不同层在不同batch size下的稀疏性行为的深入分析。
技术框架:Polar Sparsity的技术框架主要包括以下几个部分:首先,对LLM模型中的不同层(MLP和Attention)在不同batch size下的稀疏性进行分析。然后,针对Attention层,提出Selective Head Attention机制,选择性地激活部分head。最后,开发硬件高效、稀疏感知GPU内核,以加速Selective Head Attention的计算。整体流程是:模型分析 -> 稀疏化策略设计 -> 硬件加速实现。
关键创新:论文最重要的技术创新点在于发现了Attention层在大型batch size下仍然保持稳定的head稀疏性,并据此提出了Selective Head Attention机制。与以往尝试对所有层进行稀疏化处理的方法不同,Polar Sparsity专注于利用Attention层的稀疏性,从而实现了更好的扩展性和加速效果。
关键设计:Selective Head Attention的关键设计在于如何选择要激活的head。具体实现细节未知,但可以推测可能采用基于重要性评分或概率分布的方法来选择head。此外,稀疏感知GPU内核的设计也至关重要,需要针对Selective Head Attention的特点进行优化,以充分利用硬件资源。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Polar Sparsity在OPT、LLaMA-2&3、Qwen、Mistral等多个LLM模型上实现了显著的加速效果。在不同的batch size和序列长度下,端到端加速高达2.2倍,且精度没有明显下降。这些结果证明了Polar Sparsity在实际应用中的有效性和优越性。
🎯 应用场景
Polar Sparsity具有广泛的应用前景,可用于加速各种大型语言模型的推理,尤其是在需要高吞吐量和低延迟的场景中,如在线对话系统、大规模文本生成和实时翻译等。该研究成果有助于降低LLM的部署成本,并促进其在更多实际应用中的普及。
📄 摘要(原文)
Accelerating large language model (LLM) inference is critical for real-world deployments requiring high throughput and low latency. Contextual sparsity, where each token dynamically activates only a small subset of the model parameters, shows promise but does not scale to large batch sizes due to union of active neurons quickly approaching dense computation. We introduce Polar Sparsity, highlighting a key shift in sparsity importance from MLP to Attention layers as we scale batch size and sequence length. While MLP layers become more compute-efficient under batching, their sparsity vanishes. In contrast, attention becomes increasingly more expensive at scale, while their head sparsity remains stable and batch-invariant. We develop Selective Head Attention with hardware-efficient, sparsity-aware GPU kernels, delivering up to (2.2\times) end-to-end speedups for models like OPT, LLaMA-2 \& 3, Qwen, Mistral across various batch sizes and sequence lengths without compromising accuracy. To our knowledge, this is the first work to demonstrate that contextual sparsity can scale effectively to large batch sizes, delivering substantial inference acceleration with minimal changes, making Polar Sparsity practical for large-scale, high-throughput LLM deployment systems. Our code is available at: https://github.com/susavlsh10/Polar-Sparsity.