This Time is Different: An Observability Perspective on Time Series Foundation Models
作者: Ben Cohen, Emaad Khwaja, Youssef Doubli, Salahidine Lemaachi, Chris Lettieri, Charles Masson, Hugo Miccinilli, Elise Ramé, Qiqi Ren, Afshin Rostamizadeh, Jean Ogier du Terrail, Anna-Monica Toon, Kan Wang, Stephan Xie, Zongzhe Xu, Viktoriya Zhukova, David Asker, Ameet Talwalkar, Othmane Abou-Amal
分类: cs.LG, cs.AI
发布日期: 2025-05-20 (更新: 2025-11-04)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出Toto:一个面向可观测性时间序列的预训练基础模型,并在大规模基准测试中取得领先成果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 基础模型 可观测性 预训练 大规模基准测试
📋 核心要点
- 现有时间序列基础模型在处理大规模、高维度、噪声大的可观测性数据时面临挑战,泛化能力不足。
- Toto通过decoder-only架构和针对可观测性数据特点的创新设计,提升模型对复杂时间序列的理解和预测能力。
- 实验表明,Toto在BOOM基准测试和通用时间序列预测基准测试中均取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
本文介绍了Toto,一个拥有1.51亿参数的时间序列预测基础模型。Toto采用现代的仅解码器架构,并结合了架构创新,旨在解决多元可观测性时间序列数据中存在的特定挑战。Toto的预训练语料库混合了可观测性数据、开放数据集和合成数据,其规模是领先的时间序列基础模型的4-10倍。此外,本文还引入了BOOM,一个大规模基准测试,包含来自2807个真实世界时间序列的3.5亿个观测值。Toto和BOOM的数据均来自Datadog的遥测和内部可观测性指标。广泛的评估表明,Toto在BOOM和已建立的通用时间序列预测基准测试中均实现了最先进的性能。Toto的模型权重、推理代码和评估脚本,以及BOOM的数据和评估代码,均以Apache 2.0许可证开源。
🔬 方法详解
问题定义:现有时间序列预测模型,特别是基础模型,在处理来自真实世界可观测性场景的数据时,面临着数据量大、维度高、噪声多等挑战。这些挑战导致模型泛化能力不足,难以准确预测未来的时间序列数据。现有方法通常依赖于较小的数据集或特定的领域知识,无法充分利用大规模可观测性数据的潜力。
核心思路:Toto的核心思路是构建一个大规模的、通用的时间序列基础模型,该模型能够从海量的可观测性数据中学习到通用的时间序列模式,并能够有效地处理高维度和噪声数据。通过预训练的方式,Toto可以学习到时间序列数据的内在结构和依赖关系,从而提高其在各种时间序列预测任务中的性能。
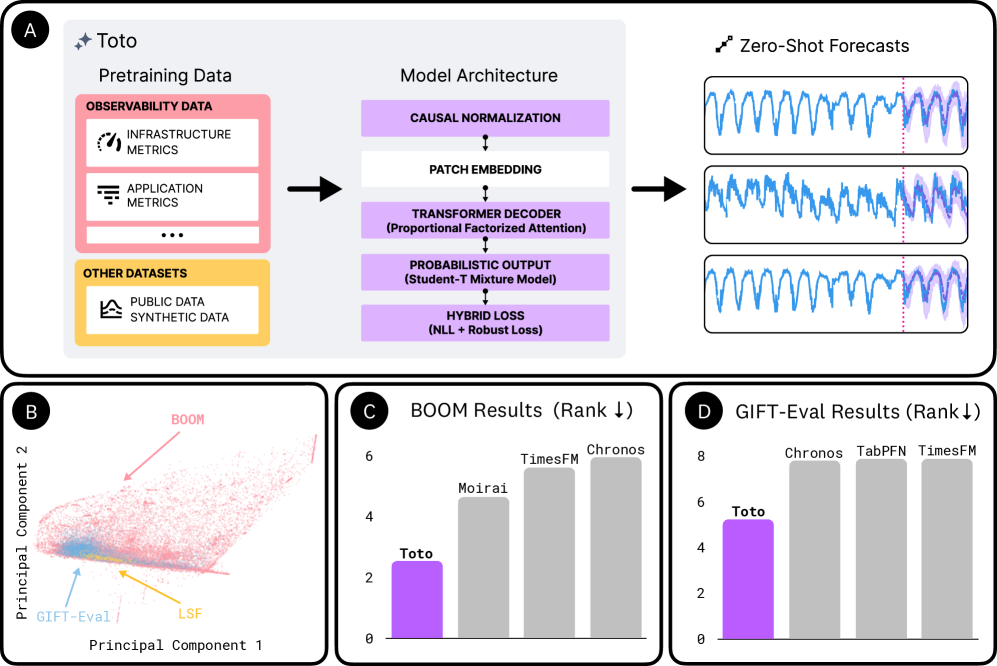
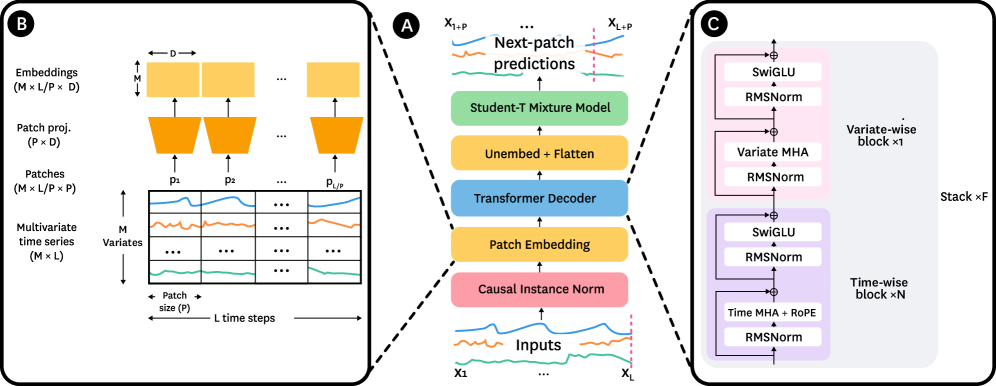
技术框架:Toto采用decoder-only架构,类似于Transformer模型。整体流程包括:1) 数据预处理:将可观测性数据、开放数据集和合成数据进行清洗、标准化和格式化;2) 模型预训练:使用大规模语料库对Toto进行预训练,学习时间序列数据的通用模式;3) 模型微调:在特定任务上对预训练模型进行微调,以适应特定任务的需求;4) 模型评估:在BOOM基准测试和通用时间序列预测基准测试中评估模型的性能。
关键创新:Toto的关键创新在于其针对可观测性数据特点的架构设计和大规模预训练语料库。具体来说,Toto采用了专门设计的注意力机制和嵌入层,以更好地处理高维度和噪声数据。此外,Toto的预训练语料库规模是现有时间序列基础模型的4-10倍,包含了各种类型的可观测性数据,从而提高了模型的泛化能力。
关键设计:Toto模型包含1.51亿参数。预训练语料库混合了可观测性数据、开放数据集和合成数据。模型采用decoder-only架构,并针对时间序列数据进行了优化。具体的技术细节包括:1) 专门设计的注意力机制,用于处理高维度时间序列数据;2) 优化的嵌入层,用于学习时间序列数据的特征表示;3) 大规模预训练语料库,用于提高模型的泛化能力。损失函数未知。
🖼️ 关键图片

📊 实验亮点
Toto在BOOM基准测试和通用时间序列预测基准测试中均取得了SOTA性能。具体来说,Toto在BOOM基准测试中的性能优于现有最佳模型,并且在多个通用时间序列预测基准测试中也取得了显著的提升。这些结果表明,Toto是一个有效的、通用的时间序列基础模型,具有很强的实际应用价值。
🎯 应用场景
Toto可应用于各种可观测性场景,例如服务器性能监控、网络流量预测、应用健康状况评估等。通过准确预测未来的时间序列数据,Toto可以帮助运维团队及时发现和解决潜在问题,提高系统的可靠性和可用性。此外,Toto还可以应用于其他时间序列预测任务,例如金融市场预测、能源消耗预测等,具有广泛的应用前景。
📄 摘要(原文)
We introduce Toto, a time series forecasting foundation model with 151 million parameters. Toto uses a modern decoder-only architecture coupled with architectural innovations designed to account for specific challenges found in multivariate observability time series data. Toto's pre-training corpus is a mixture of observability data, open datasets, and synthetic data, and is 4-10$\times$ larger than those of leading time series foundation models. Additionally, we introduce BOOM, a large-scale benchmark consisting of 350 million observations across 2,807 real-world time series. For both Toto and BOOM, we source observability data exclusively from Datadog's own telemetry and internal observability metrics. Extensive evaluations demonstrate that Toto achieves state-of-the-art performance on both BOOM and on established general purpose time series forecasting benchmarks. Toto's model weights, inference code, and evaluation scripts, as well as BOOM's data and evaluation code, are all available as open source under the Apache 2.0 License available at https://huggingface.co/Datadog/Toto-Open-Base-1.0 and https://github.com/DataDog/toto.