Quartet: Native FP4 Training Can Be Optimal for Large Language Models
作者: Roberto L. Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, Dan Alistarh
分类: cs.LG
发布日期: 2025-05-20 (更新: 2026-01-15)
🔗 代码/项目: GITHUB
💡 一句话要点
Quartet:原生FP4训练为大语言模型提供最优解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: FP4训练 低精度训练 大语言模型 Blackwell架构 CUDA内核
📋 核心要点
- 现有FP4训练方法精度损失大,依赖混合精度,无法充分发挥硬件潜力。
- Quartet通过新的低精度缩放定律指导,优化FP4训练,实现精度与计算的平衡。
- 实验表明,Quartet在Llama模型上实现了与FP16和FP8相当甚至更优的性能。
📝 摘要(中文)
直接以低精度训练大型语言模型(LLMs)是一种通过提高吞吐量和能源效率来解决计算成本的方法。为此,NVIDIA最新的Blackwell架构支持使用FP4变体的极低精度运算。然而,目前用于FP4精度训练LLM的算法面临着严重的精度下降,并且通常依赖于混合精度回退。在本文中,我们研究了硬件支持的FP4训练,并提出了一种新的方法,用于精确的端到端FP4训练,其中所有主要的计算(即线性层)都在低精度下进行。通过对Llama类型模型的大量评估,我们揭示了一种新的低精度缩放定律,该定律量化了跨位宽和训练设置的性能权衡。在这一研究的指导下,我们设计了一种在精度与计算方面“最优”的技术,称为Quartet。我们使用为Blackwell定制的优化CUDA内核实现了Quartet,证明了完全基于FP4的训练是FP16半精度和FP8训练的有竞争力的替代方案。我们的代码可在https://github.com/IST-DASLab/Quartet获得。
🔬 方法详解
问题定义:现有的大语言模型FP4训练方法存在精度下降的问题,需要依赖混合精度训练,无法充分利用NVIDIA Blackwell架构提供的硬件加速FP4计算能力。这限制了训练吞吐量和能源效率的提升。
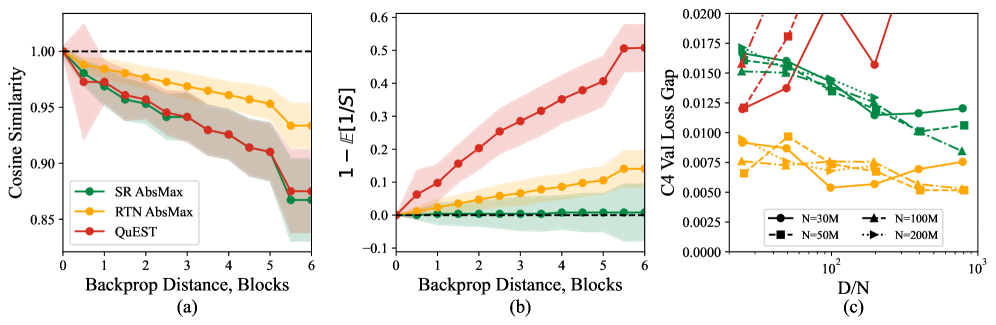
核心思路:论文的核心思路是深入研究FP4训练的精度损失原因,通过实验揭示低精度训练的缩放规律,并基于此设计一种新的FP4训练方法,在保证精度的前提下,充分利用FP4的计算优势。Quartet旨在实现完全基于FP4的端到端训练,避免混合精度带来的复杂性和性能瓶颈。
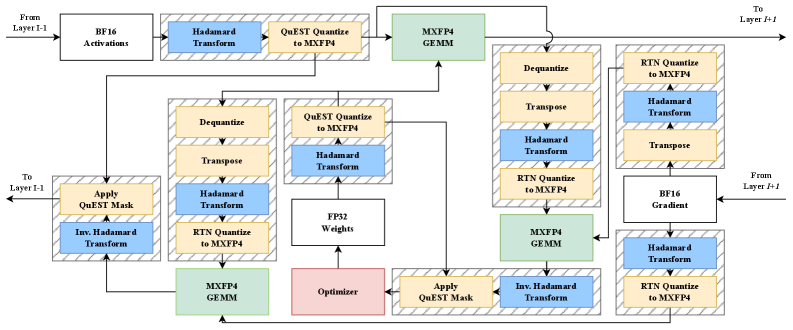
技术框架:Quartet的整体框架包括以下几个关键部分:1) 低精度缩放规律的探索,通过实验分析不同位宽和训练设置下的性能表现;2) 基于缩放规律,设计优化的FP4训练策略;3) 使用优化的CUDA内核,在NVIDIA Blackwell架构上高效实现Quartet算法。该框架旨在实现精度、计算效率和硬件利用率之间的最佳平衡。
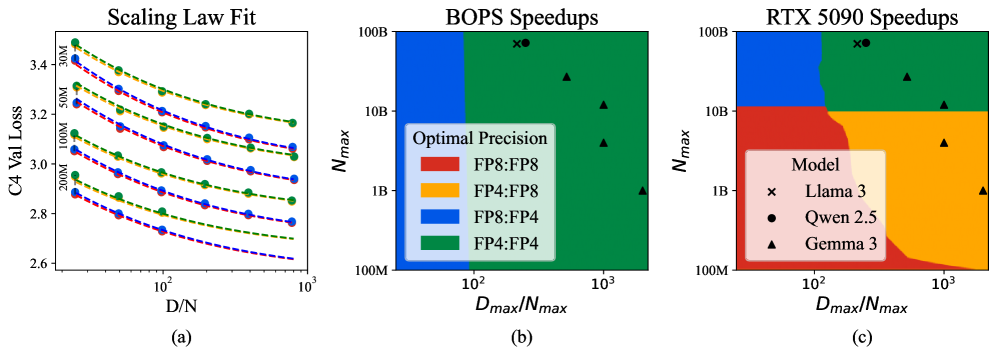
关键创新:Quartet的关键创新在于:1) 揭示了一种新的低精度缩放定律,为FP4训练的优化提供了理论指导;2) 设计了一种精度与计算最优的FP4训练技术,实现了完全基于FP4的端到端训练;3) 通过优化的CUDA内核,充分利用了NVIDIA Blackwell架构的硬件加速能力。
关键设计:Quartet的关键设计细节包括:1) 基于低精度缩放定律,选择合适的FP4变体和训练参数;2) 优化线性层的计算,减少FP4精度带来的误差累积;3) 设计合适的梯度缩放和量化策略,保证训练的稳定性和收敛性;4) 使用优化的CUDA内核,充分利用Blackwell架构的Tensor Core加速FP4计算。
🖼️ 关键图片
📊 实验亮点
Quartet在Llama类型模型上进行了广泛的评估,实验结果表明,完全基于FP4的Quartet训练可以达到与FP16半精度和FP8训练相当甚至更优的性能。这证明了FP4训练在大语言模型上的可行性和竞争力,为未来的低精度训练研究提供了新的方向。
🎯 应用场景
Quartet技术可应用于各种需要高效训练的大语言模型场景,例如自然语言处理、机器翻译、文本生成等。通过降低计算成本和能源消耗,Quartet有望加速大模型的开发和部署,并推动人工智能技术的普及。此外,该研究对于探索更低精度训练方法,进一步提升计算效率具有重要的指导意义。
📄 摘要(原文)
Training large language models (LLMs) models directly in low-precision offers a way to address computational costs by improving both throughput and energy efficiency. For those purposes, NVIDIA's recent Blackwell architecture facilitates very low-precision operations using FP4 variants. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we investigate hardware-supported FP4 training and introduce a new approach for accurate, end-to-end FP4 training with all the major computations (i.e., linear layers) in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across bit-widths and training setups. Guided by this investigation, we design an "optimal" technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for Blackwell, demonstrating that fully FP4-based training is a competitive alternative to FP16 half-precision and to FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.