Securing Transfer-Learned Networks with Reverse Homomorphic Encryption
作者: Robert Allison, Tomasz Maciążek, Henry Bourne
分类: cs.CR, cs.LG
发布日期: 2025-05-20 (更新: 2025-10-27)
备注: added protection via RHE and black box attacks
💡 一句话要点
提出反向同态加密方法,保护迁移学习网络免受训练数据重建攻击
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 同态加密 迁移学习 数据隐私 重建攻击 神经网络
📋 核心要点
- 现有的训练数据重建攻击对神经网络的安全性构成威胁,尤其是在数据敏感的场景下,差分隐私防御在小样本学习中效果不佳。
- 论文提出一种反向同态加密方法,通过加密迁移学习的权重而非输入数据,在保护训练数据隐私的同时,避免了对整个分类器进行同态加密的开销。
- 实验表明,该方法能够在保护训练数据免受重建攻击的同时,保持分类器的准确性,优于传统的差分隐私方法。
📝 摘要(中文)
关于训练数据重建攻击的大量文献引发了人们对部署在敏感数据上训练的神经网络分类器的严重担忧。差分隐私(DP)训练(例如,使用DP-SGD)可以防御此类攻击,但对于大型训练数据集,只会导致网络效用损失最小。然而,对于使用小类数据集训练的网络,DP的有效性存在疑问。本文通过显著扩展少样本迁移学习图像分类器在现实对抗威胁模型下的重建攻击能力,直接证明了这种脆弱性。设计了新的白盒和黑盒攻击,发现DP-SGD无法在不显著降低分类器效用的情况下防御这些攻击。为了解决这个问题,提出了一种新颖的同态加密(HE)方法,该方法可以在不降低模型准确性的情况下保护训练数据。传统的HE保护模型的输入数据,并且需要对整个分类器进行昂贵的同态实现。相比之下,本文的新方案计算效率高,并且保护训练数据而不是输入数据。这是通过一种简单的角色反转来实现的,其中分类器输入数据未加密,但迁移学习的权重已加密。分类器输出保持加密状态,从而防止白盒和黑盒(以及任何其他)训练数据重建攻击。在这种新方案下,只有具有私有解密密钥的可信方才能获得分类器类别决策。
🔬 方法详解
问题定义:论文旨在解决迁移学习场景下,神经网络模型容易受到训练数据重建攻击的问题。现有的差分隐私方法在小样本学习中效果不佳,无法有效防御此类攻击,同时可能导致模型性能显著下降。传统的同态加密方法计算开销巨大,难以实际应用。
核心思路:论文的核心思路是反转同态加密的应用对象。传统方法加密输入数据,而该论文加密迁移学习得到的模型权重。这样,即使攻击者可以访问未加密的输入数据和加密的模型权重,也无法推断出原始训练数据。同时,由于只需要加密模型权重,计算开销大大降低。
技术框架:该方法主要包含以下几个阶段:1. 使用未加密的训练数据进行迁移学习,得到预训练的模型权重。2. 使用同态加密算法加密预训练的模型权重。3. 使用未加密的输入数据和加密的模型权重进行推理,得到加密的分类结果。4. 只有拥有私钥的可信方才能解密分类结果,得到最终的分类决策。
关键创新:最重要的技术创新点在于反向同态加密的应用。与传统的同态加密方法相比,该方法不需要对整个分类器进行同态实现,大大降低了计算复杂度。此外,该方法直接保护了训练数据,而不是输入数据,从而有效防御了训练数据重建攻击。
关键设计:论文中关键的设计包括:1. 选择合适的同态加密算法,以保证加密的安全性和计算效率。2. 设计合理的密钥管理方案,确保只有可信方才能访问私钥。3. 优化推理过程,以减少加密计算带来的性能损失。具体的参数设置、损失函数和网络结构等细节取决于具体的应用场景和数据集。
🖼️ 关键图片

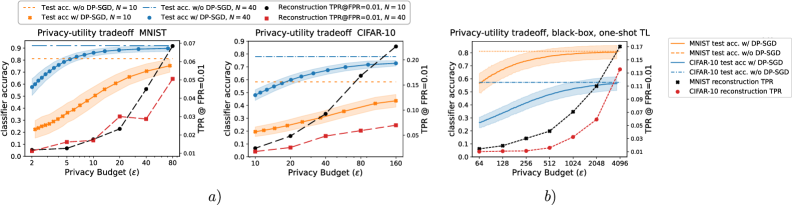

📊 实验亮点
论文通过实验证明,所提出的反向同态加密方法能够有效防御训练数据重建攻击,同时保持分类器的准确性。与传统的差分隐私方法相比,该方法在小样本学习场景下具有显著优势,能够在保护数据隐私的同时,避免模型性能的显著下降。具体的性能数据和提升幅度取决于具体的实验设置和数据集,但总体趋势表明该方法具有良好的实用价值。
🎯 应用场景
该研究成果可应用于医疗、金融等对数据隐私要求较高的领域。例如,在医疗影像分析中,可以使用该方法保护患者的医疗影像数据,同时利用迁移学习提高诊断的准确性。在金融风控中,可以使用该方法保护用户的交易数据,同时构建有效的风险评估模型。该方法还有助于促进跨机构的数据共享和合作,在保护数据隐私的前提下,实现数据的价值最大化。
📄 摘要(原文)
The growing body of literature on training-data reconstruction attacks raises significant concerns about deploying neural network classifiers trained on sensitive data. However, differentially private (DP) training (e.g. using DP-SGD) can defend against such attacks with large training datasets causing only minimal loss of network utility. Folklore, heuristics, and (albeit pessimistic) DP bounds suggest this fails for networks trained with small per-class datasets, yet to the best of our knowledge the literature offers no compelling evidence. We directly demonstrate this vulnerability by significantly extending reconstruction attack capabilities under a realistic adversary threat model for few-shot transfer learned image classifiers. We design new white-box and black-box attacks and find that DP-SGD is unable to defend against these without significant classifier utility loss. To address this, we propose a novel homomorphic encryption (HE) method that protects training data without degrading model's accuracy. Conventional HE secures model's input data and requires costly homomorphic implementation of the entire classifier. In contrast, our new scheme is computationally efficient and protects training data rather than input data. This is achieved by means of a simple role-reversal where classifier input data is unencrypted but transfer-learned weights are encrypted. Classifier outputs remain encrypted, thus preventing both white-box and black-box (and any other) training-data reconstruction attacks. Under this new scheme only a trusted party with a private decryption key can obtain the classifier class decisions.