Safety Subspaces are Not Linearly Distinct: A Fine-Tuning Case Study
作者: Kaustubh Ponkshe, Shaan Shah, Raghav Singhal, Praneeth Vepakomma
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-20 (更新: 2025-10-04)
备注: Kaustubh Ponkshe, Shaan Shah, and Raghav Singhal contributed equally to this work
🔗 代码/项目: GITHUB
💡 一句话要点
大型语言模型安全性微调研究:安全子空间并非线性可分
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性对齐 微调 安全子空间 线性可分性
📋 核心要点
- 大型语言模型通过安全对齐来保证输出的安全性,但微调容易破坏这种安全性,现有方法难以有效防御。
- 该论文的核心思想是检验安全相关行为是否集中在特定的线性子空间中,以及这些子空间是否能与通用学习分离。
- 实验结果表明,安全行为与有用行为的子空间重叠,安全性与通用学习高度纠缠,子空间防御存在根本性限制。
📝 摘要(中文)
大型语言模型(LLMs)依赖于安全对齐来生成符合社会规范的响应。然而,这种行为已知是脆弱的:进一步的微调,即使在良性或轻微污染的数据上,也可能降低安全性并重新引入有害行为。越来越多的研究表明,对齐可能对应于权重空间中可识别的方向,形成可以被隔离或保留的子空间,以防御未对齐。在这项工作中,我们对这一观点进行了全面的实证研究。我们研究了安全相关行为是否集中在特定的线性子空间中,是否可以与通用学习分离,以及有害性是否源于激活中可区分的模式。在权重和激活空间中,我们的发现是一致的:放大安全行为的子空间也放大了有用的行为,并且具有不同安全含义的提示激活了重叠的表示。我们表明,安全性高度纠缠于模型的一般学习组件,而不是存在于不同的方向上。这表明基于子空间的防御面临根本性的限制,并强调需要替代策略来在持续训练下保持安全性。我们通过对来自 Llama 和 Qwen 系列的五个开源 LLM 的多项实验证实了这些发现。我们的代码已在 https://github.com/CERT-Lab/safety-subspaces 上公开。
🔬 方法详解
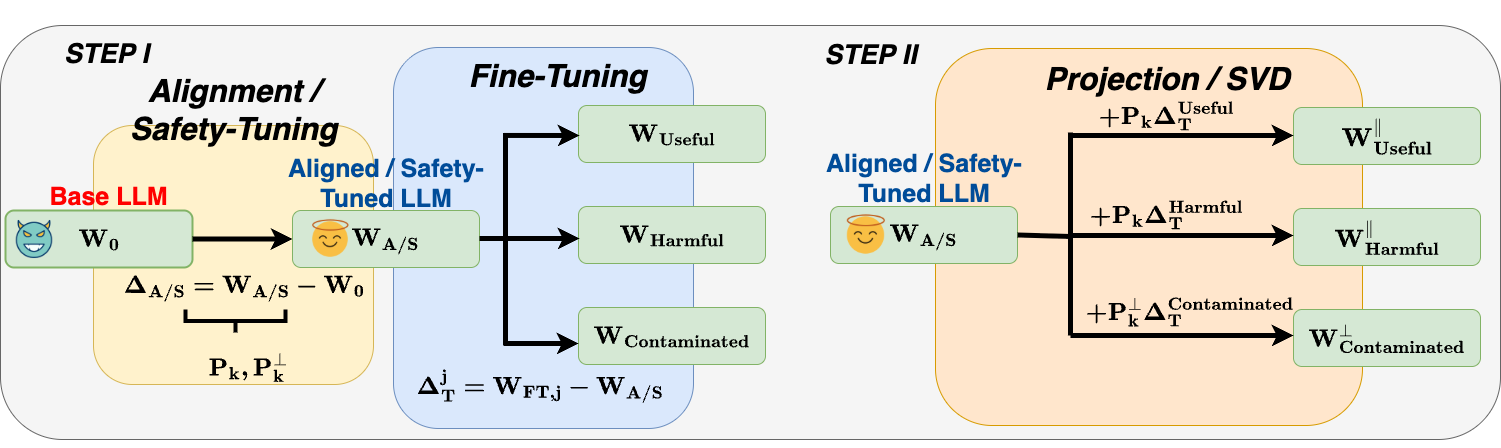
问题定义:大型语言模型在经过安全对齐后,仍然容易受到微调的影响,导致安全性下降,重新出现有害行为。现有的研究试图通过识别和隔离权重空间中的安全子空间来解决这个问题,但这些方法的效果和适用性尚不明确。论文旨在深入研究安全子空间的性质,验证其是否真的存在且线性可分,以及是否能够有效地防御微调带来的安全性问题。
核心思路:论文的核心思路是通过实证研究,检验安全相关行为是否集中在特定的线性子空间中,以及这些子空间是否能够与通用学习分离。如果安全子空间确实存在且线性可分,那么就可以通过保留或隔离这些子空间来防御微调带来的安全性问题。反之,如果安全子空间与通用学习高度纠缠,那么基于子空间的防御方法将面临根本性的限制。
技术框架:论文的技术框架主要包括以下几个步骤:1)选择多个开源LLM(Llama和Qwen系列)作为实验对象;2)设计一系列安全相关的提示和任务,用于评估模型的安全性;3)使用不同的微调策略,模拟实际应用中可能出现的安全性问题;4)分析权重空间和激活空间,识别与安全相关的子空间;5)评估这些子空间是否线性可分,以及是否能够有效地防御微调带来的安全性问题。
关键创新:论文最重要的技术创新点在于,通过全面的实证研究,揭示了安全子空间并非线性可分,而是与通用学习高度纠缠。这一发现挑战了现有基于子空间的防御方法,并为未来的研究方向提供了新的思路。论文还通过分析激活空间,进一步验证了安全相关行为与通用学习之间的复杂关系。
关键设计:论文的关键设计包括:1)选择了多个具有代表性的开源LLM,以保证实验结果的泛化性;2)设计了多种安全相关的提示和任务,涵盖了不同的安全风险;3)使用了不同的微调策略,模拟了实际应用中可能出现的安全性问题;4)采用了多种分析方法,包括主成分分析(PCA)和线性判别分析(LDA),以识别和评估安全子空间。
🖼️ 关键图片
📊 实验亮点
该研究通过对Llama和Qwen系列等五个开源LLM进行实验,发现放大安全行为的子空间也放大了有用的行为,并且具有不同安全含义的提示激活了重叠的表示。这表明安全性高度纠缠于模型的一般学习组件,而不是存在于不同的方向上。这一发现对基于子空间的防御方法提出了挑战。
🎯 应用场景
该研究成果对大型语言模型的安全对齐具有重要意义。它表明,简单地隔离或保留安全子空间可能无法有效防御微调带来的安全性问题。未来的研究需要探索更复杂的安全对齐策略,例如,在微调过程中动态调整模型的权重,或者使用对抗训练来增强模型的鲁棒性。该研究还有助于开发更有效的安全评估方法,以及更好地理解大型语言模型的内部机制。
📄 摘要(原文)
Large Language Models (LLMs) rely on safety alignment to produce socially acceptable responses. However, this behavior is known to be brittle: further fine-tuning, even on benign or lightly contaminated data, can degrade safety and reintroduce harmful behaviors. A growing body of work suggests that alignment may correspond to identifiable directions in weight space, forming subspaces that could, in principle, be isolated or preserved to defend against misalignment. In this work, we conduct a comprehensive empirical study of this perspective. We examine whether safety-relevant behavior is concentrated in specific linear subspaces, whether it can be separated from general-purpose learning, and whether harmfulness arises from distinguishable patterns in activations. Across both weight and activation spaces, our findings are consistent: subspaces that amplify safe behaviors also amplify useful ones, and prompts with different safety implications activate overlapping representations. Rather than residing in distinct directions, we show that safety is highly entangled with the general learning components of the model. This suggests that subspace-based defenses face fundamental limitations and underscores the need for alternative strategies to preserve safety under continued training. We corroborate these findings with multiple experiments on five open-source LLMs from the Llama and Qwen families. Our code is publicly available at: https://github.com/CERT-Lab/safety-subspaces.