RLVR-World: Training World Models with Reinforcement Learning
作者: Jialong Wu, Shaofeng Yin, Ningya Feng, Mingsheng Long
分类: cs.LG, cs.AI
发布日期: 2025-05-20 (更新: 2025-10-25)
备注: NeurIPS 2025. Code is available at project website: https://thuml.github.io/RLVR-World/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出RLVR-World,利用强化学习优化世界模型,提升生成模型的任务特定效用。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 强化学习 可验证奖励 自回归预测 任务特定优化
📋 核心要点
- 现有世界模型的训练目标(如MLE)与任务特定目标(如预测准确性)不一致,导致模型效用受限。
- RLVR-World利用强化学习,将世界模型的训练目标直接与任务特定指标对齐,通过可验证奖励驱动模型优化。
- 实验表明,RLVR-World在文本游戏、网页导航和机器人操作等领域,显著提升了语言和视频世界模型的性能。
📝 摘要(中文)
世界模型旨在预测动作驱动下的状态转移,并在多种模态中得到广泛应用。然而,诸如最大似然估计(MLE)等标准训练目标,通常与世界模型的任务特定目标不一致,例如,准确性或感知质量等转移预测指标。本文提出了RLVR-World,一个统一的框架,利用带有可验证奖励的强化学习(RLVR)来直接优化世界模型,使其更好地服务于这些指标。尽管我们将世界建模定义为token化序列的自回归预测,RLVR-World将解码预测的指标评估为可验证的奖励。我们在包括文本游戏、网页导航和机器人操作等多个领域的语言和视频世界模型上展示了显著的性能提升。我们的工作表明,除了最近在推理语言模型方面的进展之外,RLVR为更广泛地提升生成模型的效用提供了一个有希望的后训练范式。代码、数据集、模型和视频样本可在项目网站上找到:https://thuml.github.io/RLVR-World。
🔬 方法详解
问题定义:现有世界模型的训练方法,如最大似然估计(MLE),通常关注整体的生成质量,而忽略了特定任务的需求。例如,在机器人操作中,模型可能生成视觉上逼真的视频,但无法准确预测下一步动作的结果。这种不一致性导致世界模型在实际应用中的效果不佳。
核心思路:RLVR-World的核心思想是将世界模型的训练过程视为一个强化学习问题。通过定义与任务相关的奖励函数,例如预测的准确性或感知质量,RLVR-World可以引导模型学习更符合任务需求的表示和预测。这种方法允许模型直接优化其在特定任务上的性能,而不是仅仅追求整体的生成质量。
技术框架:RLVR-World框架包含以下几个主要模块:1) 世界模型:负责根据当前状态和动作预测下一个状态。该模型可以是基于语言的或基于视频的,采用自回归预测token化序列的方式。2) 奖励函数:根据预测结果和真实结果计算奖励。奖励函数的设计至关重要,需要能够准确反映任务的需求。3) 强化学习算法:使用强化学习算法(如策略梯度或Q-learning)来优化世界模型的参数,使其能够获得更高的奖励。4) 可验证奖励:使用可验证的奖励函数,确保奖励信号的可靠性和有效性。
关键创新:RLVR-World的关键创新在于将强化学习与可验证奖励相结合,直接优化世界模型以适应特定任务。与传统的训练方法相比,RLVR-World能够更好地对齐模型的训练目标和实际应用需求,从而提高模型的效用。此外,该框架具有通用性,可以应用于不同模态(如语言和视频)和不同领域的任务。
关键设计:RLVR-World的关键设计包括:1) Token化方法:将状态和动作表示为token序列,以便使用自回归模型进行预测。2) 奖励函数设计:根据具体任务设计合适的奖励函数,例如,在文本游戏中,可以使用预测的文本与目标文本的相似度作为奖励;在机器人操作中,可以使用预测的物体位置与真实位置的距离作为奖励。3) 强化学习算法选择:选择合适的强化学习算法来优化世界模型的参数。论文中可能使用了策略梯度或Q-learning等算法。4) 奖励缩放:对奖励进行缩放,以确保强化学习算法的稳定性和收敛性。
🖼️ 关键图片


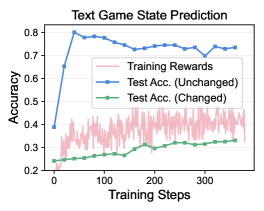
📊 实验亮点
实验结果表明,RLVR-World在文本游戏、网页导航和机器人操作等多个领域都取得了显著的性能提升。例如,在文本游戏中,RLVR-World能够更准确地预测下一步的文本状态,从而提高游戏AI的智能水平。在机器人操作中,RLVR-World能够更准确地预测机器人的运动轨迹,从而提高机器人的控制精度。
🎯 应用场景
RLVR-World具有广泛的应用前景,包括游戏AI、机器人控制、自动驾驶、网页内容生成等领域。通过优化世界模型,可以使AI系统更好地理解环境,做出更明智的决策,并生成更符合用户需求的文本或视频内容。该研究有望推动人工智能在各个领域的应用。
📄 摘要(原文)
World models predict state transitions in response to actions and are increasingly developed across diverse modalities. However, standard training objectives such as maximum likelihood estimation (MLE) often misalign with task-specific goals of world models, i.e., transition prediction metrics like accuracy or perceptual quality. In this paper, we present RLVR-World, a unified framework that leverages reinforcement learning with verifiable rewards (RLVR) to directly optimize world models for such metrics. Despite formulating world modeling as autoregressive prediction of tokenized sequences, RLVR-World evaluates metrics of decoded predictions as verifiable rewards. We demonstrate substantial performance gains on both language- and video-based world models across domains, including text games, web navigation, and robot manipulation. Our work indicates that, beyond recent advances in reasoning language models, RLVR offers a promising post-training paradigm for enhancing the utility of generative models more broadly. Code, datasets, models, and video samples are available at the project website: https://thuml.github.io/RLVR-World.