Structured Agent Distillation for Large Language Model
作者: Jun Liu, Zhenglun Kong, Peiyan Dong, Changdi Yang, Tianqi Li, Hao Tang, Geng Yuan, Wei Niu, Wenbin Zhang, Pu Zhao, Xue Lin, Dong Huang, Yanzhi Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-20 (更新: 2025-09-30)
💡 一句话要点
提出结构化Agent蒸馏方法,压缩LLM Agent并保持推理和行动一致性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识蒸馏 Agent学习 结构化学习 推理与行动 模型压缩 决策智能
📋 核心要点
- 大型语言模型Agent推理能力强但模型体积大,部署成本高昂,需要有效的压缩方法。
- 结构化Agent蒸馏将轨迹分解为推理和行动片段,并分别进行知识对齐,提升蒸馏效果。
- 实验表明,该方法在多个任务上优于传统蒸馏和模仿学习,实现了显著的模型压缩。
📝 摘要(中文)
大型语言模型(LLMs)在ReAct框架中展现出强大的决策能力,能够交错进行推理和行动。然而,实际部署受到高昂的推理成本和庞大的模型尺寸的限制。我们提出了结构化Agent蒸馏,该框架将基于大型LLM的Agent压缩为更小的学生模型,同时保留推理的保真度和行动的一致性。与标准的token级别蒸馏不同,我们的方法将轨迹分割为{[REASON]}和{[ACT]}跨度,应用特定于片段的损失来使每个组件与教师的行为对齐。这种结构感知的监督使紧凑的Agent能够更好地复制教师的决策过程。在ALFWorld、HotPotQA-ReAct和WebShop上的实验表明,我们的方法始终优于token级别和模仿学习基线,实现了显著的压缩,同时性能下降最小。缩放和消融结果进一步突出了跨度级别对齐对于高效和可部署Agent的重要性。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)Agent,例如基于ReAct框架的Agent,虽然在决策方面表现出色,但其庞大的模型尺寸和高昂的推理成本限制了它们在实际场景中的部署。传统的token级别蒸馏方法在压缩这些Agent时,难以保证推理过程的保真度和行动的一致性,导致性能显著下降。
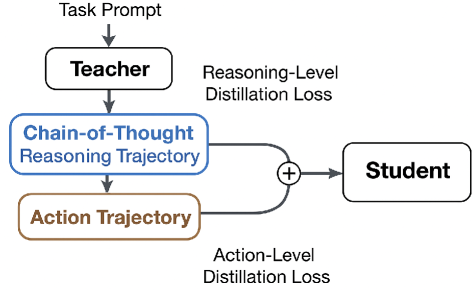
核心思路:论文的核心思路是利用Agent轨迹的结构信息,将轨迹分解为推理(REASON)和行动(ACT)两个关键片段,并针对每个片段采用特定的损失函数进行知识蒸馏。通过这种结构感知的监督,可以使学生模型更好地学习教师模型的决策过程,从而在压缩模型尺寸的同时,保持Agent的性能。
技术框架:结构化Agent蒸馏框架主要包含以下几个步骤:1) 使用大型LLM Agent(教师模型)生成Agent轨迹数据。2) 将Agent轨迹数据分割为推理(REASON)和行动(ACT)片段。3) 使用学生模型模仿教师模型的行为,并分别计算推理片段和行动片段的损失。4) 使用总损失函数训练学生模型。总损失函数通常由推理损失和行动损失加权组成。
关键创新:该方法最重要的创新点在于提出了结构感知的蒸馏方法,将Agent轨迹分解为推理和行动片段,并分别进行知识对齐。与传统的token级别蒸馏方法相比,该方法能够更好地保留教师模型的决策过程,从而在压缩模型尺寸的同时,保持Agent的性能。
关键设计:关键设计包括:1) 如何有效地将Agent轨迹分割为推理和行动片段。可以使用正则表达式或者其他自然语言处理技术来识别推理和行动片段。2) 如何设计推理损失和行动损失。推理损失可以使用交叉熵损失或者KL散度损失,行动损失可以使用交叉熵损失或者行为克隆损失。3) 如何选择合适的学生模型。可以选择较小的LLM或者其他类型的模型,例如Transformer模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,结构化Agent蒸馏方法在ALFWorld、HotPotQA-ReAct和WebShop等任务上,始终优于token级别蒸馏和模仿学习基线。例如,在ALFWorld任务上,使用结构化Agent蒸馏方法训练的学生模型,在模型尺寸显著减小的情况下,性能仅下降了很小一部分,甚至在某些指标上超过了教师模型。这表明该方法能够有效地压缩LLM Agent,同时保持其决策能力。
🎯 应用场景
该研究成果可应用于各种需要智能Agent进行决策的场景,例如智能客服、游戏AI、自动驾驶、机器人控制等。通过将大型LLM Agent压缩为更小的模型,可以降低部署成本,提高推理速度,从而使这些Agent能够更广泛地应用于实际场景中。此外,该方法还可以用于训练更高效的强化学习Agent。
📄 摘要(原文)
Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.