Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens
作者: Karthik Valmeekam, Kaya Stechly, Vardhan Palod, Atharva Gundawar, Subbarao Kambhampati
分类: cs.LG, cs.AI
发布日期: 2025-05-19 (更新: 2025-11-22)
💡 一句话要点
中间推理Token的有效性研究:语义并非必要条件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 大型语言模型 推理 Transformer模型 语义信息
📋 核心要点
- 现有研究过度强调思维链(CoT)的语义信息,未能充分理解其对模型推理能力的真正影响。
- 本研究通过控制实验,探究了推理轨迹的语义信息对模型性能的影响,包括正确和损坏的推理轨迹。
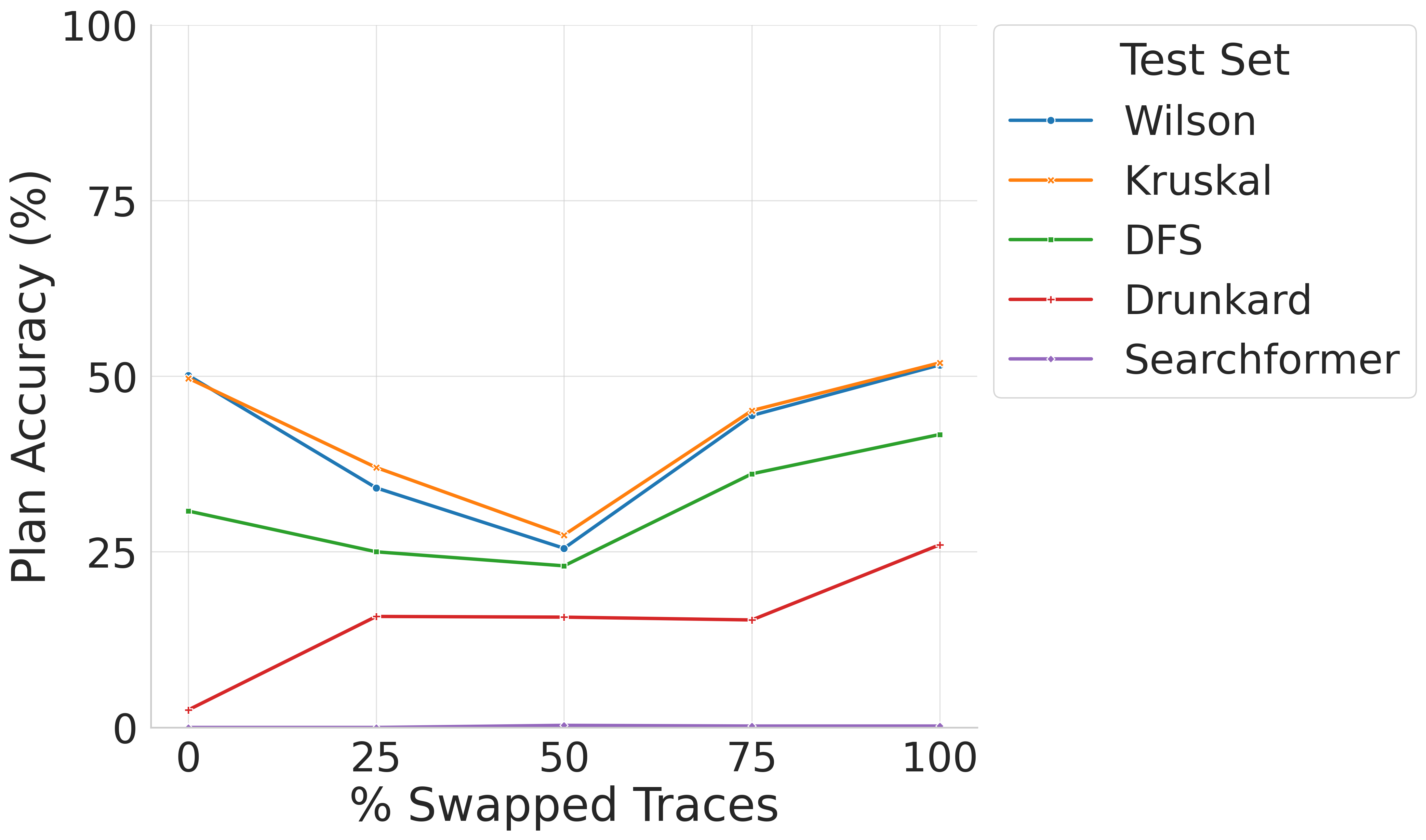
- 实验结果表明,即使使用损坏的推理轨迹,模型也能达到与使用正确轨迹相似甚至更好的性能,挑战了CoT语义重要性的假设。
📝 摘要(中文)
大型推理模型近期的显著成果通常归功于思维链(CoT),特别是通过在基础LLM采样的CoT上进行训练,以发现新的推理模式。尽管这些推理轨迹似乎有助于模型性能,但它们如何实际影响性能尚不清楚。为了系统地研究推导轨迹的语义作用,我们进行了一项受控研究,从头开始训练Transformer模型,使用形式上可验证的推理轨迹及其对应的解决方案。我们发现,尽管相对于仅使用解决方案的基线有显著提升,但即使在获得正确解决方案时,使用完全正确的轨迹训练的模型仍然可能产生无效的推理轨迹。更有趣的是,我们的实验表明,使用损坏的轨迹(其中间推理步骤与其伴随的问题无关)训练的模型,其性能与使用正确轨迹训练的模型相似,甚至在分布外任务上泛化能力更好。我们还研究了基于GRPO的强化学习后训练对轨迹有效性的影响,发现虽然解决方案的准确性有所提高,但轨迹有效性没有任何改善。最后,我们检查了推理轨迹长度是否反映了推理时的缩放比例,发现轨迹长度在很大程度上与所解决问题的底层计算复杂性无关。这些结果挑战了中间token或“思维链”反映或诱导可预测推理行为的假设,并告诫人们不要将这些输出拟人化或过度解读它们,尽管它们大多看似合理,但不能作为语言模型中类人或算法行为的证据。
🔬 方法详解
问题定义:论文旨在探究大型语言模型中,中间推理步骤(即Chain-of-Thought, CoT)的语义信息对于模型最终推理结果的影响。现有研究往往将CoT视为模型推理过程的忠实代理,并假设其语义正确性与模型性能直接相关。然而,这种假设缺乏充分的实验验证,并且可能导致对模型能力的过度解读。
核心思路:论文的核心思路是通过系统性的受控实验,剥离CoT的语义信息,观察模型在不同语义质量的CoT上的训练和推理表现。具体而言,论文比较了使用正确CoT、损坏CoT以及仅使用答案进行训练的模型性能,从而评估CoT的语义信息在模型学习过程中的作用。
技术框架:论文采用Transformer模型作为基础架构,并从头开始训练模型。实验流程主要包括以下几个步骤:1) 生成形式上可验证的推理轨迹及其对应的解决方案;2) 对推理轨迹进行损坏,生成语义不相关的CoT;3) 使用不同语义质量的CoT(正确、损坏)以及仅使用答案的数据集训练Transformer模型;4) 在分布内和分布外任务上评估模型的性能,包括解决方案的准确性和推理轨迹的有效性;5) 使用GRPO进行强化学习后训练,并评估其对轨迹有效性的影响。
关键创新:论文最重要的创新点在于挑战了CoT语义重要性的假设。实验结果表明,即使使用语义不相关的CoT进行训练,模型也能取得与使用正确CoT相似甚至更好的性能,这表明CoT可能仅仅作为一种中间表示,其语义信息并非模型推理的必要条件。
关键设计:论文的关键设计包括:1) 使用形式上可验证的推理轨迹,确保CoT的正确性;2) 通过随机替换CoT中的token,生成语义不相关的损坏CoT;3) 在分布内和分布外任务上评估模型的泛化能力;4) 使用GRPO进行强化学习后训练,以提高模型的解决方案准确性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用损坏的推理轨迹训练的模型,其性能与使用正确轨迹训练的模型相似,甚至在分布外任务上泛化能力更好。此外,基于GRPO的强化学习后训练虽然提高了解决方案的准确性,但并未改善轨迹的有效性。这些结果挑战了CoT语义重要性的假设。
🎯 应用场景
该研究成果可应用于提升大型语言模型的训练效率和鲁棒性。通过降低对中间推理步骤语义正确性的要求,可以减少数据标注成本,并提高模型在噪声数据上的泛化能力。此外,该研究也对CoT的解释性和可靠性提出了质疑,有助于更理性地评估和利用大型语言模型。
📄 摘要(原文)
Recent impressive results from large reasoning models have been interpreted as a triumph of Chain of Thought (CoT), especially of training on CoTs sampled from base LLMs to help find new reasoning patterns. While these traces certainly seem to help model performance, it is not clear how they actually influence it, with some works ascribing semantics to the traces and others cautioning against relying on them as transparent and faithful proxies of the model's internal computational process. To systematically investigate the role of end-user semantics of derivational traces, we set up a controlled study where we train transformer models from scratch on formally verifiable reasoning traces and the solutions they lead to. We notice that, despite significant gains over the solution-only baseline, models trained on entirely correct traces can still produce invalid reasoning traces even when arriving at correct solutions. More interestingly, our experiments also show that models trained on corrupted traces, whose intermediate reasoning steps bear no relation to the problem they accompany, perform similarly to those trained on correct ones, and even generalize better on out-of-distribution tasks. We also study the effect of GRPO-based RL post-training on trace validity, noting that while solution accuracy increase, this is not accompanied by any improvements in trace validity. Finally, we examine whether reasoning-trace length reflects inference-time scaling and find that trace length is largely agnostic to the underlying computational complexity of the problem being solved. These results challenge the assumption that intermediate tokens or ``Chains of Thought'' reflect or induce predictable reasoning behaviors and caution against anthropomorphizing such outputs or over-interpreting them (despite their mostly seemingly forms) as evidence of human-like or algorithmic behaviors in language models.