RL in Name Only? Analyzing the Structural Assumptions in RL post-training for LLMs
作者: Soumya Rani Samineni, Durgesh Kalwar, Karthik Valmeekam, Kaya Stechly, Subbarao Kambhampati
分类: cs.LG, cs.AI
发布日期: 2025-05-19 (更新: 2025-11-10)
💡 一句话要点
分析RL微调LLM的结构性假设,揭示其退化为监督学习的本质
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 微调 结构性假设 监督学习
📋 核心要点
- 现有基于强化学习的LLM后训练方法,其有效性受到结构性假设的质疑,可能导致强化学习过程退化。
- 论文核心在于分析将LLM训练建模为MDP时的结构性假设,并证明这些假设使得RL训练等价于监督学习。
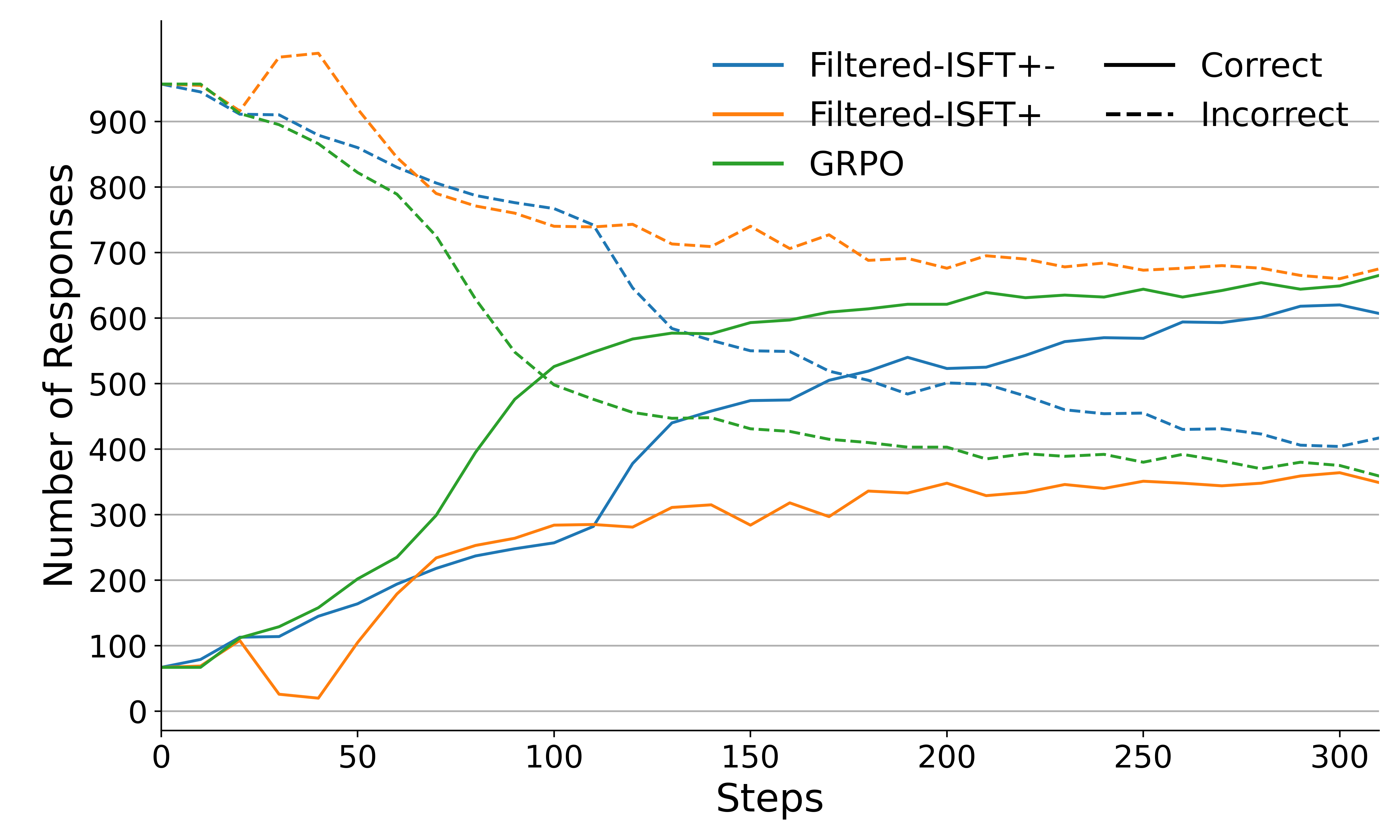
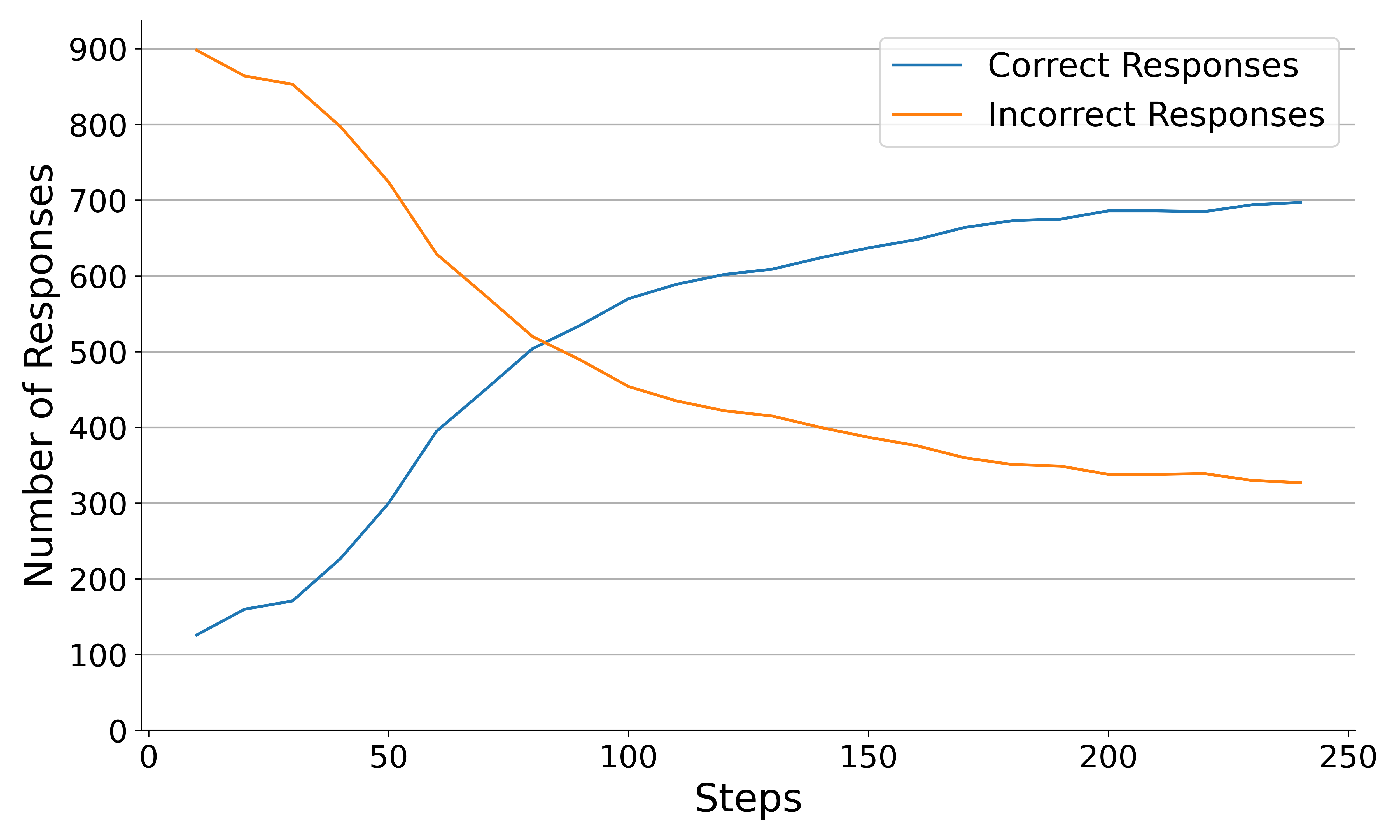
- 实验表明,在GSM8K等基准测试中,迭代监督微调可以达到与GRPO训练相当的性能,验证了论文的分析。
📝 摘要(中文)
本文 критически 分析了基于强化学习(RL)的大语言模型(LLM)后训练方法,特别是DeepSeek R1中应用的GRPO。尽管RL后训练因其提升推理能力而备受关注,但本文深入研究了这些方法背后的公式和假设。研究表明,将LLM训练建模为马尔可夫决策过程(MDP)时,常见的结构性假设会导致MDP退化,从而使RL/GRPO变得不必要。两个关键假设包括:将MDP状态定义为动作的连接(即状态成为上下文窗口,动作成为LLM中的token),以及将状态-动作轨迹的奖励均匀分配到整个轨迹上。通过综合分析,本文证明了这些简化假设使得该方法实际上等同于结果驱动的监督学习。在GSM8K和Countdown等基准测试中使用Qwen-2.5基础模型进行的实验表明,迭代监督微调(包含正负样本)可以达到与基于GRPO的训练相当的性能。此外,本文还指出,这些结构性假设间接激励RL生成更长的中间token序列,从而强化了“RL生成更长思考轨迹”的说法。虽然RL可能对提高LLM的推理能力非常有用,但本文的分析表明,在建模底层MDP时所做的简单结构性假设使得流行的LLM RL框架及其解释值得怀疑。
🔬 方法详解
问题定义:目前流行的使用强化学习(RL)对大型语言模型(LLM)进行微调的方法,声称能够提升LLM的推理能力。然而,这些方法通常基于一些简化的结构性假设,例如将LLM的生成过程建模成马尔可夫决策过程(MDP)时,对状态和奖励的定义进行了简化。这些简化是否合理,以及是否真的需要使用复杂的RL算法,是本文要解决的问题。现有方法的痛点在于,缺乏对这些结构性假设的深入分析,可能导致对RL效果的过度解读。
核心思路:本文的核心思路是,通过分析RL微调LLM过程中常见的结构性假设,证明这些假设会导致MDP的退化,使得RL过程实际上等同于监督学习。具体来说,论文关注两个关键假设:一是将MDP的状态定义为动作的简单连接(即上下文窗口),二是将奖励均匀分配到整个动作序列上。通过理论分析和实验验证,论文表明在这些假设下,RL过程的目标函数与监督学习的目标函数高度相似。
技术框架:论文没有提出新的技术框架,而是对现有基于RL的LLM微调框架进行了分析。其分析流程主要包括:1) 梳理现有方法中常见的结构性假设;2) 从理论上分析这些假设对MDP的影响;3) 设计实验验证在这些假设下,RL方法与监督学习方法的性能差异。论文主要使用了Qwen-2.5作为基础模型,并在GSM8K和Countdown等基准测试上进行了实验。
关键创新:本文最重要的技术创新点在于,揭示了RL微调LLM过程中结构性假设的潜在问题,并证明在这些假设下,RL过程可能退化为监督学习。这种分析为理解RL在LLM微调中的作用提供了新的视角,并挑战了现有对RL效果的过度解读。
关键设计:论文的关键设计在于,通过理论分析和实验验证相结合的方式,证明了结构性假设对RL过程的影响。在实验方面,论文设计了迭代监督微调的基线方法,并与基于GRPO的训练方法进行了对比。迭代监督微调的关键在于,同时使用正样本和负样本进行训练,以模拟RL中的奖励机制。论文没有详细说明具体的参数设置和网络结构,但使用了Qwen-2.5作为基础模型,并采用了常见的训练技巧。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,在GSM8K和Countdown等基准测试中,使用Qwen-2.5基础模型进行迭代监督微调,可以达到与基于GRPO的训练相当的性能。这一结果表明,在特定的结构性假设下,RL微调的优势可能被高估,简单的监督学习方法可能更有效。具体的性能数据和提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果有助于更深入地理解强化学习在大型语言模型微调中的作用,避免过度解读RL带来的性能提升。研究结果可以指导研究人员在设计RL微调算法时,更加谨慎地选择结构性假设,或者探索更有效的建模方法。此外,该研究也提示我们可以使用更简单的监督学习方法,在特定场景下达到与RL相当的性能。
📄 摘要(原文)
Reinforcement learning-based post-training of large language models (LLMs) has recently gained attention, particularly following the release of DeepSeek R1, which applied GRPO for fine-tuning. Amid the growing hype around improved reasoning abilities attributed to RL post-training, we critically examine the formulation and assumptions underlying these methods. We start by highlighting the popular structural assumptions made in modeling LLM training as a Markov Decision Process (MDP), and show how they lead to a degenerate MDP that doesn't quite need the RL/GRPO apparatus. The two critical structural assumptions include (1) making the MDP states be just a concatenation of the actions-with states becoming the context window and the actions becoming the tokens in LLMs and (2) splitting the reward of a state-action trajectory uniformly across the trajectory. Through a comprehensive analysis, we demonstrate that these simplifying assumptions make the approach effectively equivalent to an outcome-driven supervised learning. Our experiments on benchmarks including GSM8K and Countdown using Qwen-2.5 base models show that iterative supervised fine-tuning, incorporating both positive and negative samples, achieves performance comparable to GRPO-based training. We will also argue that the structural assumptions indirectly incentivize the RL to generate longer sequences of intermediate tokens-which in turn feeds into the narrative of "RL generating longer thinking traces." While RL may well be a very useful technique for improving the reasoning abilities of LLMs, our analysis shows that the simplistic structural assumptions made in modeling the underlying MDP render the popular LLM RL frameworks and their interpretations questionable.