Fine-tuning Quantized Neural Networks with Zeroth-order Optimization
作者: Sifeng Shang, Jiayi Zhou, Chenyu Lin, Minxian Li, Kaiyang Zhou
分类: cs.LG, cs.CL, cs.CV
发布日期: 2025-05-19 (更新: 2025-09-01)
💡 一句话要点
提出量化零阶优化(QZO),在极低内存下微调量化神经网络。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化神经网络 零阶优化 低精度训练 大语言模型 内存优化
📋 核心要点
- 现有大模型微调方法面临GPU内存瓶颈,尤其是在模型权重、梯度和优化器状态上消耗巨大。
- 论文提出量化零阶优化(QZO),通过扰动量化尺度估计梯度,避免了反量化和重构,降低内存占用。
- 实验表明,QZO能显著降低内存成本,例如在4位LLM上降低18倍以上,并能在24GB GPU上微调Llama-2-13B。
📝 摘要(中文)
随着大型语言模型规模的指数级增长,GPU内存已成为将这些模型适配到下游任务的瓶颈。本文旨在通过在一个统一的框架内,最小化模型权重、梯度和优化器状态的内存使用,来突破内存高效训练的极限。我们的想法是利用零阶优化消除梯度和优化器状态,零阶优化通过在正向传播过程中扰动权重来近似梯度,从而识别梯度方向。为了最小化权重的内存使用,我们采用模型量化,例如从bfloat16转换为int4。然而,由于离散权重和连续梯度之间的精度差距,直接将零阶优化应用于量化权重是不可行的,否则需要反量化和重新量化。为了克服这个挑战,我们提出量化零阶优化(QZO),这是一种简单而有效的方法,它扰动连续量化尺度以进行梯度估计,并使用方向导数裁剪方法来稳定训练。QZO与基于标量和基于码本的后训练量化方法正交。与16位全参数微调相比,QZO可以将4位LLM的总内存成本降低18倍以上,并能够在单个24GB GPU中微调Llama-2-13B。代码将公开发布。
🔬 方法详解
问题定义:论文旨在解决大型语言模型微调过程中GPU内存消耗过大的问题。现有方法,如全参数微调,需要存储模型权重、梯度和优化器状态,导致内存需求巨大,难以在资源受限的设备上进行。直接对量化后的模型进行零阶优化不可行,因为离散的量化权重与连续的梯度之间存在精度差异,需要进行反量化和重新量化,增加了计算复杂度和内存开销。
核心思路:论文的核心思路是利用零阶优化来消除梯度和优化器状态的存储,并通过扰动量化尺度来估计梯度,从而避免直接操作离散的量化权重。这种方法能够在保持模型量化的同时,实现高效的梯度估计和模型微调,显著降低内存占用。
技术框架:QZO的整体框架包括以下几个主要步骤:1) 模型量化:将模型权重从高精度格式(如bfloat16)量化为低精度格式(如int4)。2) 零阶梯度估计:通过扰动连续的量化尺度来近似梯度。具体来说,对量化尺度进行微小的扰动,计算模型输出的变化,从而估计梯度方向。3) 方向导数裁剪:为了稳定训练过程,采用方向导数裁剪方法,限制梯度更新的幅度。4) 模型更新:根据估计的梯度和裁剪后的方向导数,更新模型权重。
关键创新:QZO的关键创新在于:1) 将零阶优化应用于量化模型,避免了反量化和重新量化操作,显著降低了内存占用。2) 通过扰动连续的量化尺度来估计梯度,解决了离散权重和连续梯度之间的精度差异问题。3) 提出了方向导数裁剪方法,稳定了训练过程,避免了梯度爆炸等问题。
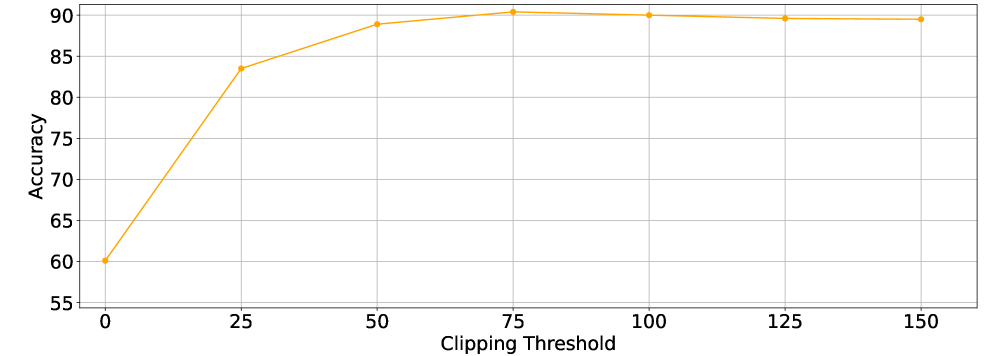
关键设计:QZO的关键设计包括:1) 量化方案的选择:论文采用了一种通用的量化方案,可以与不同的量化方法(如标量量化和码本量化)结合使用。2) 扰动尺度的选择:扰动尺度的大小会影响梯度估计的精度和训练的稳定性,需要根据具体任务进行调整。3) 方向导数裁剪的阈值:裁剪阈值的选择会影响训练的收敛速度和模型的性能,需要进行实验验证。
🖼️ 关键图片


📊 实验亮点
实验结果表明,QZO在保持模型性能的同时,显著降低了内存占用。例如,在4位LLM上,QZO可以将总内存成本降低18倍以上。此外,QZO还能够在单个24GB GPU上微调Llama-2-13B,这在以前是难以实现的。这些结果表明,QZO是一种高效且实用的模型微调方法。
🎯 应用场景
QZO具有广泛的应用前景,尤其是在资源受限的设备上部署和微调大型语言模型。例如,可以在移动设备、嵌入式系统或低端GPU上进行模型微调,从而实现个性化推荐、智能助手等应用。此外,QZO还可以用于加速模型训练和降低训练成本,提高AI模型的普及率。
📄 摘要(原文)
As the size of large language models grows exponentially, GPU memory has become a bottleneck for adapting these models to downstream tasks. In this paper, we aim to push the limits of memory-efficient training by minimizing memory usage on model weights, gradients, and optimizer states, within a unified framework. Our idea is to eliminate both gradients and optimizer states using zeroth-order optimization, which approximates gradients by perturbing weights during forward passes to identify gradient directions. To minimize memory usage on weights, we employ model quantization, e.g., converting from bfloat16 to int4. However, directly applying zeroth-order optimization to quantized weights is infeasible due to the precision gap between discrete weights and continuous gradients, which would otherwise require de-quantization and re-quantization. To overcome this challenge, we propose Quantized Zeroth-order Optimization (QZO), a simple yet effective approach that perturbs the continuous quantization scale for gradient estimation and uses a directional derivative clipping method to stabilize training. QZO is orthogonal to both scalar-based and codebook-based post-training quantization methods. Compared to full-parameter fine-tuning in 16 bits, QZO can reduce the total memory cost by more than 18$\times$ for 4-bit LLMs, and enables fine-tuning Llama-2-13B within a single 24GB GPU. Code will be released publicly.