Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space
作者: Hengli Li, Chenxi Li, Tong Wu, Xuekai Zhu, Yuxuan Wang, Zhaoxin Yu, Eric Hanchen Jiang, Song-Chun Zhu, Zixia Jia, Ying Nian Wu, Zilong Zheng
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-19 (更新: 2026-01-19)
💡 一句话要点
提出LatentSeek,通过隐空间测试时策略梯度提升LLM推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 测试时自适应 策略梯度 隐空间 强化学习 实例级自适应
📋 核心要点
- 大型语言模型在推理能力上仍面临挑战,现有训练方法存在灾难性遗忘和数据稀缺问题。
- LatentSeek通过在隐空间进行测试时实例级自适应,利用策略梯度迭代优化隐表示,提升推理性能。
- 实验表明,LatentSeek在多个推理基准上优于思维链提示和微调方法,且具有高效性和可扩展性。
📝 摘要(中文)
大型语言模型(LLM)的推理能力是实现通用人工智能(AGI)的关键挑战。尽管模型性能随着训练规模的扩大而提高,但在训练算法(如灾难性遗忘)和新训练数据的有限性方面仍然存在重大挑战。作为一种替代方案,测试时扩展通过增加测试时计算而不更新参数来增强推理性能。与先前专注于token空间的方法不同,我们提出利用隐空间进行更有效的推理,并更好地遵循测试时扩展规律。我们引入了LatentSeek,这是一个新颖的框架,通过模型隐空间中的测试时实例级自适应(TTIA)来增强LLM推理。具体来说,LatentSeek利用策略梯度来迭代更新隐表示,并由自我生成的奖励信号引导。LatentSeek在一系列推理基准(包括GSM8K、MATH-500和AIME2024)上,跨多个LLM架构进行了评估。结果表明,LatentSeek始终优于强大的基线,如思维链提示和基于微调的方法。此外,我们的分析表明,LatentSeek非常高效,通常在几次迭代中即可收敛于平均复杂性的问题,同时也能从额外的迭代中受益,从而突出了隐空间中测试时扩展的潜力。这些发现使LatentSeek成为一种轻量级、可扩展且有效的解决方案,用于增强LLM的推理能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理任务中存在的不足,尤其是在训练数据有限或模型需要快速适应新任务时。现有方法,如微调,需要大量数据和计算资源,且可能导致灾难性遗忘。而基于token空间的测试时自适应方法可能效率较低,无法充分利用模型的潜在能力。
核心思路:论文的核心思路是在LLM的隐空间中进行测试时实例级自适应。通过在隐空间中调整表示,模型可以在不改变参数的情况下更好地适应特定输入,从而提高推理性能。这种方法借鉴了强化学习中的策略梯度思想,通过奖励信号引导隐表示的优化。
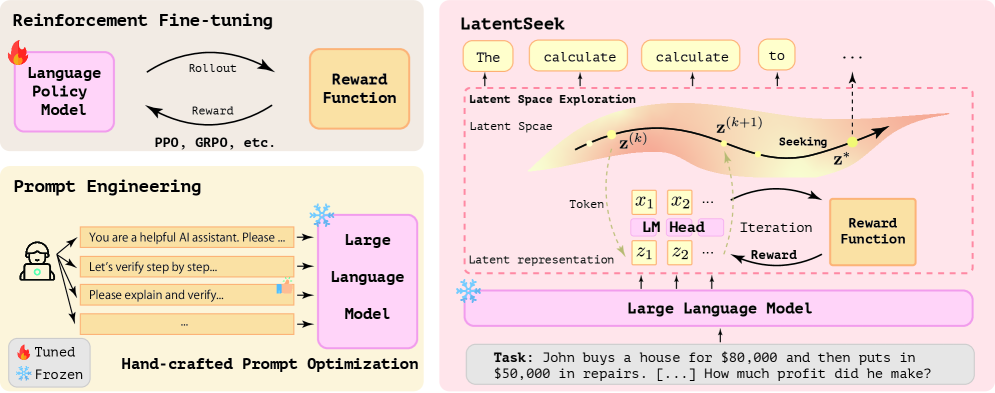
技术框架:LatentSeek框架包含以下主要步骤:1) 输入问题通过LLM编码器得到初始隐表示;2) 使用策略网络(Policy Network)对隐表示进行迭代更新;3) LLM解码器根据更新后的隐表示生成答案;4) 基于生成的答案,设计奖励函数,提供反馈信号;5) 使用策略梯度算法优化策略网络,使其能够生成更好的隐表示。整个过程在测试时进行,无需修改模型参数。
关键创新:LatentSeek的关键创新在于将测试时自适应从token空间转移到隐空间,并引入了策略梯度算法进行优化。与传统的微调方法相比,LatentSeek无需大量训练数据,且能快速适应新任务。与基于token空间的方法相比,隐空间操作更高效,能更好地利用模型的潜在能力。
关键设计:奖励函数的设计是LatentSeek的关键。论文中使用了自我生成的奖励信号,例如,通过检查生成的答案是否符合逻辑或是否包含关键信息来评估答案的质量。策略网络可以使用简单的多层感知机或更复杂的Transformer结构。策略梯度算法可以使用常见的REINFORCE或Actor-Critic方法。迭代次数是一个重要的超参数,需要在效率和性能之间进行权衡。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LatentSeek在GSM8K、MATH-500和AIME2024等推理基准上显著优于基线方法,包括思维链提示和微调。LatentSeek通常在几次迭代后即可收敛,且随着迭代次数的增加,性能持续提升,验证了测试时扩展在隐空间中的有效性。例如,在某些任务上,LatentSeek的性能提升超过10%。
🎯 应用场景
LatentSeek可应用于各种需要快速适应和推理能力的场景,如智能客服、自动问答系统、代码生成等。它尤其适用于数据稀缺或需要个性化定制的场景。该研究为提升LLM的推理能力提供了一种新的思路,有望推动LLM在实际应用中的更广泛应用。
📄 摘要(原文)
Reasoning ability, a core component of human intelligence, continues to pose a significant challenge for Large Language Models (LLMs) in the pursuit of AGI. Although model performance has improved under the training scaling law, significant challenges remain, particularly with respect to training algorithms, such as catastrophic forgetting, and the limited availability of novel training data. As an alternative, test-time scaling enhances reasoning performance by increasing test-time computation without parameter updating. Unlike prior methods in this paradigm focused on token space, we propose leveraging latent space for more effective reasoning and better adherence to the test-time scaling law. We introduce LatentSeek, a novel framework that enhances LLM reasoning through Test-Time Instance-level Adaptation (TTIA) within the model's latent space. Specifically, LatentSeek leverages policy gradient to iteratively update latent representations, guided by self-generated reward signals. LatentSeek is evaluated on a range of reasoning benchmarks, including GSM8K, MATH-500, and AIME2024, across multiple LLM architectures. Results show that LatentSeek consistently outperforms strong baselines, such as Chain-of-Thought prompting and fine-tuning-based methods. Furthermore, our analysis demonstrates that LatentSeek is highly efficient, typically converging within a few iterations for problems of average complexity, while also benefiting from additional iterations, thereby highlighting the potential of test-time scaling in the latent space. These findings position LatentSeek as a lightweight, scalable, and effective solution for enhancing the reasoning capabilities of LLMs.