FreeKV: Boosting KV Cache Retrieval for Efficient LLM Inference
作者: Guangda Liu, Chengwei Li, Zhenyu Ning, Jing Lin, Yiwu Yao, Danning Ke, Minyi Guo, Jieru Zhao
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-19 (更新: 2025-12-16)
💡 一句话要点
FreeKV:通过增强KV缓存检索提升LLM推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存 LLM推理 长上下文 推测执行 系统优化
📋 核心要点
- 长上下文LLM推理面临KV缓存过大的挑战,现有压缩方法损失精度,检索方法效率低。
- FreeKV通过推测检索将KV选择移出关键路径,并进行细粒度校正以保证精度。
- FreeKV采用混合KV布局和双缓冲流式召回,实验表明其加速比可达13倍,且精度损失小。
📝 摘要(中文)
大型语言模型(LLM)已被广泛部署,其上下文窗口迅速扩展以支持日益增长的应用需求。然而,长上下文带来了显著的部署挑战,主要是由于KV缓存的大小与上下文长度成正比增长。虽然已经提出了KV缓存压缩方法来解决这个问题,但KV丢弃方法会导致相当大的精度损失,而KV检索方法则面临显著的效率瓶颈。我们提出了FreeKV,一个算法-系统协同优化框架,以提高KV检索效率,同时保持精度。在算法方面,FreeKV引入了推测检索,将KV选择和召回过程移出关键路径,并结合细粒度校正以确保准确性。在系统方面,FreeKV采用跨CPU和GPU内存的混合KV布局,以消除碎片化数据传输,并利用双缓冲流式召回进一步提高效率。实验表明,FreeKV在各种场景和模型中实现了接近无损的精度,与SOTA KV检索方法相比,速度提高了高达13倍。
🔬 方法详解
问题定义:论文旨在解决长上下文LLM推理中,KV缓存过大导致的效率瓶颈问题。现有的KV缓存压缩方法,如KV丢弃,会造成精度损失;而KV检索方法,虽然能保留更多信息,但检索过程本身会引入显著的计算开销,成为新的性能瓶颈。
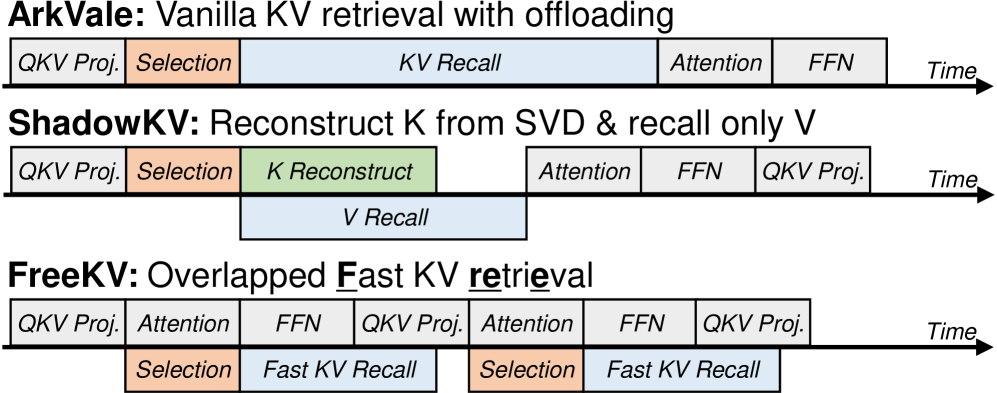
核心思路:FreeKV的核心思路是采用推测检索(Speculative Retrieval)来降低KV检索的延迟。通过预测哪些KV值可能被需要,提前进行检索,从而将检索过程从关键路径中移除。同时,为了保证精度,FreeKV引入了细粒度校正机制,对推测检索的结果进行修正。
技术框架:FreeKV是一个算法-系统协同优化框架。在算法层面,主要包含推测检索和细粒度校正两个阶段。推测检索阶段预测并检索可能需要的KV值;细粒度校正阶段对检索结果进行修正,以保证精度。在系统层面,FreeKV采用混合KV布局,将KV缓存分布在CPU和GPU内存中,并利用双缓冲流式召回机制,优化数据传输效率。
关键创新:FreeKV的关键创新在于推测检索机制。与传统的KV检索方法不同,FreeKV不是在需要KV值时才进行检索,而是提前进行预测和检索,从而降低了检索延迟。此外,细粒度校正机制保证了在推测检索的情况下,仍然能够保持较高的精度。
关键设计:FreeKV的推测检索机制需要设计合适的预测策略,以确定哪些KV值可能被需要。细粒度校正机制需要设计合适的校正方法,以修正推测检索带来的误差。混合KV布局需要考虑CPU和GPU内存的容量和带宽,以及数据传输的效率。双缓冲流式召回机制需要合理设置缓冲区的大小和数量,以平衡数据传输的延迟和开销。具体的参数设置和实现细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
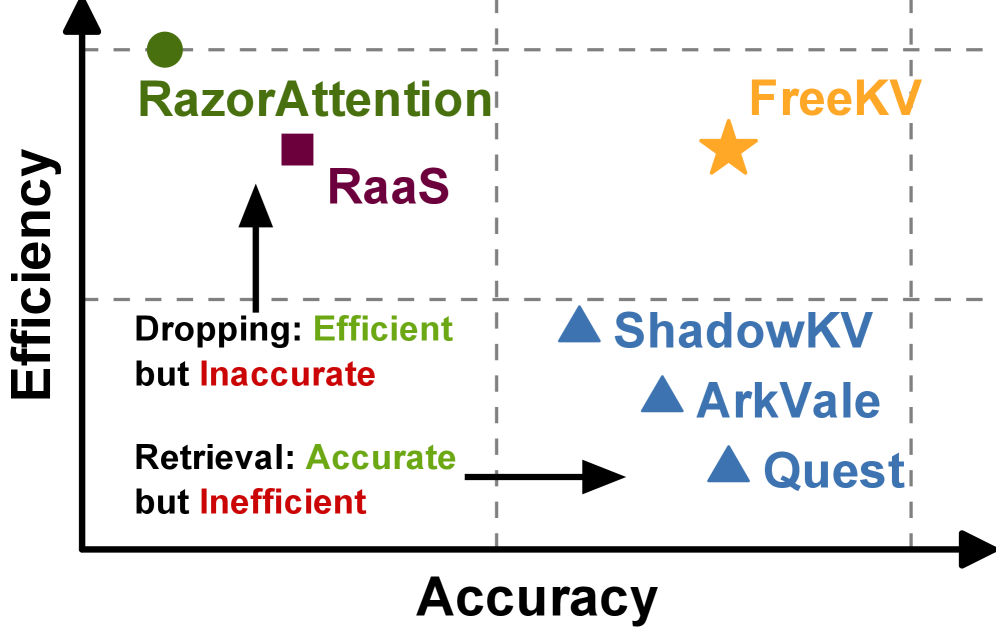
实验结果表明,FreeKV在各种场景和模型中实现了接近无损的精度。与SOTA KV检索方法相比,FreeKV的速度提高了高达13倍。这些结果表明,FreeKV是一种高效且准确的KV缓存检索方法,可以显著提升LLM推理效率。
🎯 应用场景
FreeKV可应用于各种需要处理长上下文的LLM应用场景,例如长文档摘要、代码生成、对话系统等。通过提高LLM推理效率,FreeKV可以降低部署成本,提升用户体验,并推动LLM在更多领域的应用。该研究对于优化LLM推理性能具有重要的实际价值和广泛的未来影响。
📄 摘要(原文)
Large language models (LLMs) have been widely deployed with rapidly expanding context windows to support increasingly demanding applications. However, long contexts pose significant deployment challenges, primarily due to the KV cache whose size grows proportionally with context length. While KV cache compression methods are proposed to address this issue, KV dropping methods incur considerable accuracy loss, and KV retrieval methods suffer from significant efficiency bottlenecks. We propose FreeKV, an algorithm-system co-optimization framework to enhance KV retrieval efficiency while preserving accuracy. On the algorithm side, FreeKV introduces speculative retrieval to shift the KV selection and recall processes out of the critical path, combined with fine-grained correction to ensure accuracy. On the system side, FreeKV employs hybrid KV layouts across CPU and GPU memory to eliminate fragmented data transfers, and leverages double-buffered streamed recall to further improve efficiency. Experiments demonstrate that FreeKV achieves near-lossless accuracy across various scenarios and models, delivering up to 13$\times$ speedup compared to SOTA KV retrieval methods.