Certifying Stability of Reinforcement Learning Policies using Generalized Lyapunov Functions
作者: Kehan Long, Jorge Cortés, Nikolay Atanasov
分类: cs.LG, cs.RO, eess.SY, math.OC
发布日期: 2025-05-16 (更新: 2026-01-12)
备注: NeurIPS 2025
💡 一句话要点
提出基于广义Lyapunov函数的强化学习策略稳定性验证方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 稳定性验证 Lyapunov函数 控制理论 神经网络 吸引域 安全关键系统
📋 核心要点
- 传统Lyapunov方法难以验证强化学习策略的稳定性,因为其要求过于严格,难以满足。
- 该论文提出一种学习广义Lyapunov函数的方法,通过增强RL价值函数并放宽递减条件,实现稳定性验证。
- 实验表明,该方法成功验证了在多个基准测试中训练的RL策略的稳定性,并扩大了可认证的吸引域。
📝 摘要(中文)
为超越经验性能并提供系统行为保证,为强化学习(RL)策略下的闭环系统建立稳定性证书至关重要。经典的Lyapunov方法要求Lyapunov函数严格逐步递减,但对于学习到的策略,这种证书很难构建。RL价值函数是一个自然的选择,但如何将其用于此目的尚不清楚。为了获得直觉,我们首先研究线性二次调节器(LQR)问题,并提出两个关键观察结果。首先,可以通过将LQR策略的价值函数与系统动力学和阶段成本相关的残差项相结合来获得Lyapunov函数。其次,经典的Lyapunov递减要求可以放宽为广义Lyapunov条件,仅要求在多个时间步长上平均递减。利用这种直觉,我们考虑非线性环境,并提出一种通过用神经网络残差项增强RL价值函数来学习广义Lyapunov函数的方法。我们的方法成功地验证了在Gymnasium和DeepMind Control基准上训练的RL策略的稳定性。我们还将该方法扩展到使用多步Lyapunov损失联合训练神经控制器和稳定性证书,与经典的Lyapunov方法相比,从而获得了更大的可认证吸引域内部近似。总的来说,我们的公式通过使证书更容易构建,从而为广泛的具有学习策略的系统实现了稳定性认证,从而弥合了经典控制理论和现代基于学习的方法之间的差距。
🔬 方法详解
问题定义:论文旨在解决强化学习策略的稳定性验证问题。现有方法,特别是基于经典Lyapunov理论的方法,由于需要严格的Lyapunov函数递减,难以应用于通过强化学习得到的复杂策略。这限制了强化学习在安全关键型系统中的应用,因为无法保证系统的稳定性。
核心思路:论文的核心思路是引入广义Lyapunov函数,并将其与强化学习的价值函数相结合。广义Lyapunov函数允许在多个时间步长上平均递减,而不是要求每一步都严格递减,从而放宽了稳定性验证的条件。通过将价值函数与一个残差项结合,可以更容易地构造满足广义Lyapunov条件的函数。
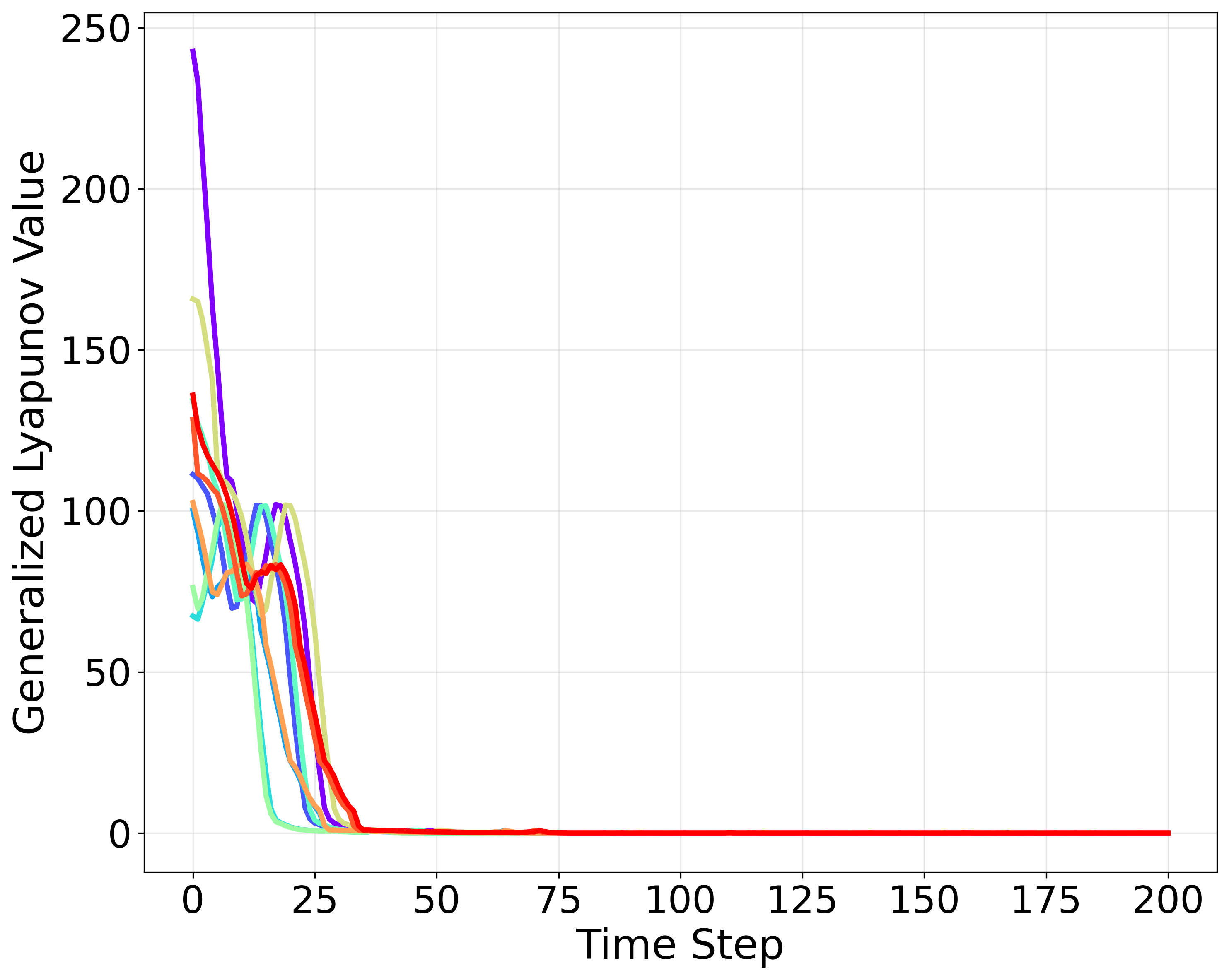
技术框架:该方法包含以下几个主要步骤:1) 利用强化学习算法训练一个策略,并得到相应的价值函数。2) 使用神经网络学习一个残差项,该残差项与价值函数结合形成广义Lyapunov函数。3) 定义一个多步Lyapunov损失函数,用于训练神经网络,使得广义Lyapunov函数满足平均递减的条件。4) 使用训练好的广义Lyapunov函数验证策略的稳定性,并估计吸引域。
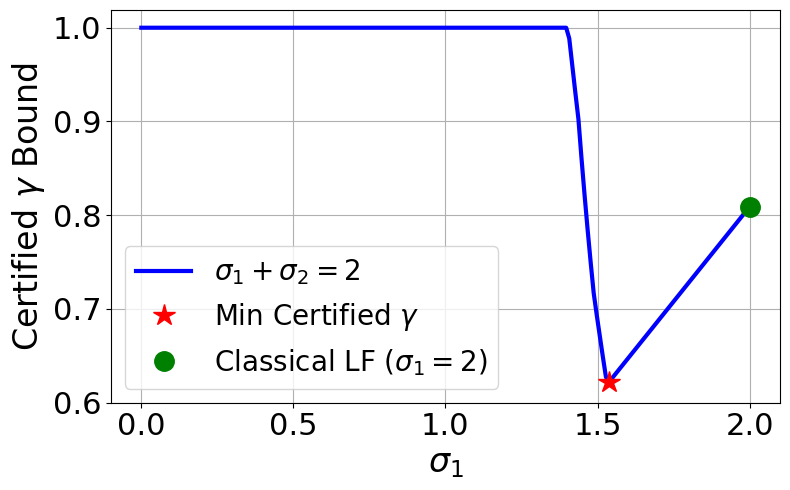
关键创新:该论文的关键创新在于:1) 提出了广义Lyapunov函数的概念,并将其应用于强化学习策略的稳定性验证。2) 提出了一种通过学习残差项来构造广义Lyapunov函数的方法,使得稳定性证书更容易构建。3) 提出了一种多步Lyapunov损失函数,用于联合训练神经控制器和稳定性证书。
关键设计:关键设计包括:1) 残差项使用神经网络进行参数化,以便能够处理复杂的非线性系统。2) 多步Lyapunov损失函数的设计,该损失函数鼓励广义Lyapunov函数在多个时间步长上平均递减。损失函数通常包含一个惩罚项,用于确保Lyapunov函数在状态空间中是正定的。3) 吸引域的估计方法,通常基于对Lyapunov函数的水平集进行分析。
🖼️ 关键图片

📊 实验亮点
该论文在Gymnasium和DeepMind Control基准测试中验证了所提出方法的有效性。实验结果表明,该方法能够成功验证强化学习策略的稳定性,并扩大了可认证的吸引域。与传统的Lyapunov方法相比,该方法能够获得更大的吸引域内部近似,这意味着可以保证系统在更大的状态范围内保持稳定。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、航空航天等安全关键领域。通过验证强化学习策略的稳定性,可以确保系统在复杂环境中的安全运行。例如,在自动驾驶中,可以验证车辆控制策略的稳定性,避免发生碰撞等事故。此外,该方法还可以用于设计更稳定的强化学习策略,提高系统的鲁棒性。
📄 摘要(原文)
Establishing stability certificates for closed-loop systems under reinforcement learning (RL) policies is essential to move beyond empirical performance and offer guarantees of system behavior. Classical Lyapunov methods require a strict stepwise decrease in the Lyapunov function but such certificates are difficult to construct for learned policies. The RL value function is a natural candidate but it is not well understood how it can be adapted for this purpose. To gain intuition, we first study the linear quadratic regulator (LQR) problem and make two key observations. First, a Lyapunov function can be obtained from the value function of an LQR policy by augmenting it with a residual term related to the system dynamics and stage cost. Second, the classical Lyapunov decrease requirement can be relaxed to a generalized Lyapunov condition requiring only decrease on average over multiple time steps. Using this intuition, we consider the nonlinear setting and formulate an approach to learn generalized Lyapunov functions by augmenting RL value functions with neural network residual terms. Our approach successfully certifies the stability of RL policies trained on Gymnasium and DeepMind Control benchmarks. We also extend our method to jointly train neural controllers and stability certificates using a multi-step Lyapunov loss, resulting in larger certified inner approximations of the region of attraction compared to the classical Lyapunov approach. Overall, our formulation enables stability certification for a broad class of systems with learned policies by making certificates easier to construct, thereby bridging classical control theory and modern learning-based methods.