Accelerating Visual-Policy Learning through Parallel Differentiable Simulation
作者: Haoxiang You, Yilang Liu, Ian Abraham
分类: cs.LG, cs.RO
发布日期: 2025-05-15 (更新: 2025-11-10)
💡 一句话要点
提出一种并行可微仿真加速视觉策略学习算法,提升训练效率和性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉策略学习 可微仿真 策略梯度 机器人控制 强化学习
📋 核心要点
- 现有视觉策略学习方法计算成本高昂,依赖专门的可微渲染软件,限制了其在复杂环境中的应用。
- 该论文通过解耦渲染过程和计算图,利用可微仿真和一阶解析策略梯度,实现了高效的视觉策略学习。
- 实验表明,该方法显著减少了训练时间,并在复杂任务(如人形运动)上取得了显著的性能提升,最终回报提升高达4倍。
📝 摘要(中文)
本文提出了一种计算高效的视觉策略学习算法,该算法利用可微仿真和一阶解析策略梯度。我们的方法将渲染过程与计算图解耦,从而能够与现有的可微仿真生态系统无缝集成,而无需专门的可微渲染软件。这种解耦不仅降低了计算和内存开销,而且有效地衰减了策略梯度范数,从而实现了更稳定和更平滑的优化。我们在使用现代GPU加速仿真的标准视觉控制基准上评估了我们的方法。实验表明,我们的方法显著减少了实际训练时间,并且在最终回报方面始终优于所有基线方法。值得注意的是,在诸如人形运动等复杂任务上,我们的方法在最终回报方面实现了4倍的提升,并且成功地在单个GPU上于4小时内学习到人形跑步策略。
🔬 方法详解
问题定义:视觉策略学习旨在让智能体仅通过视觉输入学习控制策略。现有方法通常计算成本高昂,特别是当涉及复杂环境和高维状态空间时。此外,许多方法依赖于专门的可微渲染软件,这限制了它们与现有仿真生态系统的集成,并增加了开发和维护的复杂性。因此,如何降低计算成本,提高训练效率,并实现与现有仿真环境的无缝集成,是视觉策略学习领域面临的关键挑战。
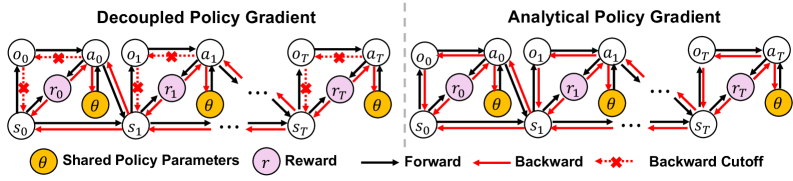
核心思路:该论文的核心思路是将渲染过程从计算图中解耦。通过这种解耦,可以避免对整个渲染过程进行反向传播,从而显著降低计算和内存开销。此外,解耦还可以有效地衰减策略梯度范数,从而实现更稳定和更平滑的优化。这种设计使得该方法能够与现有的可微仿真生态系统无缝集成,而无需专门的可微渲染软件。
技术框架:该方法主要包含以下几个关键模块:1) 视觉感知模块:负责从视觉输入中提取有用的特征表示。2) 策略网络:根据视觉特征输出控制动作。3) 可微仿真环境:用于模拟智能体与环境的交互,并提供奖励信号。4) 策略梯度优化器:利用一阶解析策略梯度更新策略网络参数。整体流程是:智能体在仿真环境中执行策略,收集经验数据,然后利用可微仿真计算策略梯度,并使用优化器更新策略网络。
关键创新:该论文最重要的技术创新点在于将渲染过程从计算图中解耦。这种解耦不仅降低了计算和内存开销,而且有效地衰减了策略梯度范数,从而实现了更稳定和更平滑的优化。与现有方法相比,该方法不需要专门的可微渲染软件,可以与现有的可微仿真生态系统无缝集成,从而降低了开发和维护的复杂性。
关键设计:该方法使用一阶解析策略梯度进行策略优化。具体来说,该方法使用REINFORCE算法的变体,并利用可微仿真环境计算策略梯度。为了进一步提高训练效率,该方法还采用了并行计算技术,在多个GPU上同时运行多个仿真环境。损失函数通常是期望回报的负值,目标是最大化智能体在仿真环境中的累积奖励。网络结构的选择取决于具体的任务,通常采用卷积神经网络(CNN)或循环神经网络(RNN)作为视觉感知模块和策略网络。
🖼️ 关键图片

📊 实验亮点
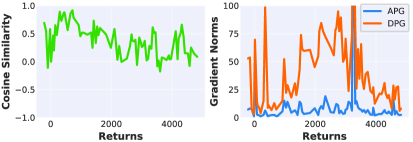
实验结果表明,该方法在标准视觉控制基准上显著减少了训练时间,并在最终回报方面始终优于所有基线方法。在人形运动等复杂任务上,该方法在最终回报方面实现了4倍的提升,并且成功地在单个GPU上于4小时内学习到人形跑步策略。这些结果表明,该方法具有很强的实用性和竞争力。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域。通过高效的视觉策略学习,可以使智能体在复杂环境中自主学习完成各种任务,例如机器人导航、物体抓取、自动驾驶车辆的路径规划等。该方法降低了训练成本,加速了算法迭代,有望推动相关技术在实际场景中的应用。
📄 摘要(原文)
In this work, we propose a computationally efficient algorithm for visual policy learning that leverages differentiable simulation and first-order analytical policy gradients. Our approach decouple the rendering process from the computation graph, enabling seamless integration with existing differentiable simulation ecosystems without the need for specialized differentiable rendering software. This decoupling not only reduces computational and memory overhead but also effectively attenuates the policy gradient norm, leading to more stable and smoother optimization. We evaluate our method on standard visual control benchmarks using modern GPU-accelerated simulation. Experiments show that our approach significantly reduces wall-clock training time and consistently outperforms all baseline methods in terms of final returns. Notably, on complex tasks such as humanoid locomotion, our method achieves a $4\times$ improvement in final return, and successfully learns a humanoid running policy within 4 hours on a single GPU.