Analog Foundation Models
作者: Julian Büchel, Iason Chalas, Giovanni Acampa, An Chen, Omobayode Fagbohungbe, Sidney Tsai, Kaoutar El Maghraoui, Manuel Le Gallo, Abbas Rahimi, Abu Sebastian
分类: cs.LG
发布日期: 2025-05-14 (更新: 2025-10-27)
备注: Neural Information Processing Systems (NeurIPS) 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种通用方法以适应模拟内存计算的LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模拟内存计算 大型语言模型 低精度量化 鲁棒性训练 能效优化
📋 核心要点
- 现有的大型语言模型在模拟内存计算硬件上无法达到4位精度的性能,主要受限于计算噪声和量化约束。
- 本文提出了一种通用的适应方法,使得大型语言模型能够在低精度模拟硬件上有效执行,克服了噪声和量化问题。
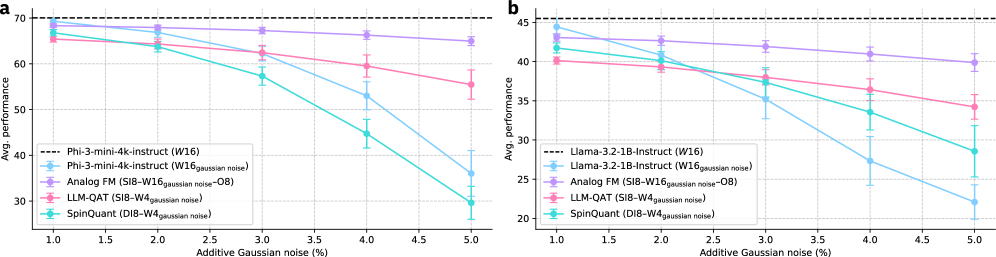
- 实验结果显示,经过该方法训练的模型在性能上与4位权重和8位激活的基线相当,并在测试时计算扩展方面表现更佳。
📝 摘要(中文)
模拟内存计算(AIMC)是一种有前景的计算范式,旨在提高神经网络推理的速度和能效,超越传统冯·诺依曼架构的限制。然而,AIMC带来了计算噪声和输入输出量化的严格限制,导致现有的大型语言模型(LLM)在4位精度下无法正常工作。本文提出了一种通用且可扩展的方法,能够有效适应LLM在噪声和低精度模拟硬件上的执行。我们的研究表明,经过该方法训练的模型在保持性能的同时,能够在低精度数字硬件上进行量化推理,并且在测试时计算扩展方面表现优于传统模型。代码可在https://github.com/IBM/analog-foundation-models获取。
🔬 方法详解
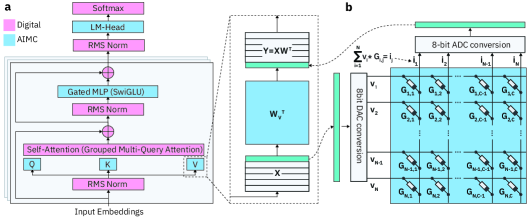
问题定义:本文旨在解决大型语言模型在模拟内存计算硬件上执行时因计算噪声和量化限制导致的性能下降问题。现有方法主要集中于小型视觉模型,缺乏针对LLM的通用解决方案。
核心思路:我们提出了一种通用且可扩展的训练方法,通过对模型进行鲁棒性调整,使其能够在噪声和低精度条件下保持性能。该方法的设计旨在最大限度地减少量化带来的精度损失。
技术框架:整体架构包括模型的鲁棒性训练、量化适应和测试时计算扩展三个主要模块。首先,通过特定的训练策略提高模型对噪声的抵抗力;其次,进行模型量化以适应低精度硬件;最后,优化测试时的计算策略以提升性能。
关键创新:本研究的主要创新在于提出了一种针对LLM的通用适应方法,使其能够在模拟硬件上高效执行,填补了现有研究的空白。与传统方法相比,我们的方法在处理大规模模型时表现出更好的鲁棒性和适应性。
关键设计:在训练过程中,我们采用了特定的损失函数来平衡模型的精度与鲁棒性,同时在量化过程中精确控制权重和激活的位数,以确保模型在低精度硬件上的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过我们的方法训练的模型在4位权重和8位激活的基线下,能够保持相当的性能。此外,模型在测试时的计算扩展表现优于传统方法,显示出更好的可扩展性和效率。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和智能助手等。通过提高大型语言模型在低能耗硬件上的执行效率,能够推动边缘计算和移动设备的智能化发展,具有重要的实际价值和未来影响。
📄 摘要(原文)
Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models.