Towards Fair In-Context Learning with Tabular Foundation Models
作者: Patrik Kenfack, Samira Ebrahimi Kahou, Ulrich Aïvodji
分类: cs.LG
发布日期: 2025-05-14 (更新: 2026-01-05)
备注: Published in Transactions on Machine Learning Research (TMLR)
🔗 代码/项目: GITHUB
💡 一句话要点
针对表格数据ICL,提出不确定性采样方法,提升TabPFNv2等模型的公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 上下文学习 公平性 不确定性采样 预处理 Transformer TabPFNv2 算法歧视
📋 核心要点
- 表格基础模型在ICL中表现出色,但其公平性问题未被充分研究,可能导致对特定群体的歧视。
- 论文提出基于不确定性的样本选择策略,优先选择敏感属性预测不确定性高的样本,以提升公平性。
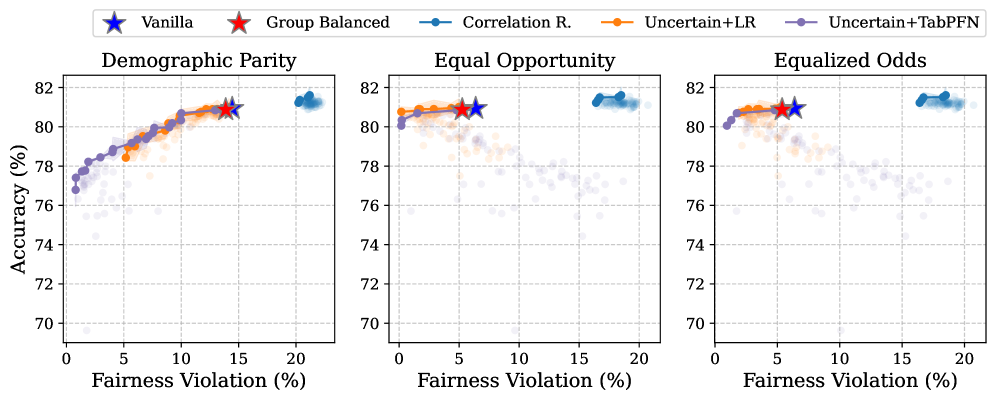
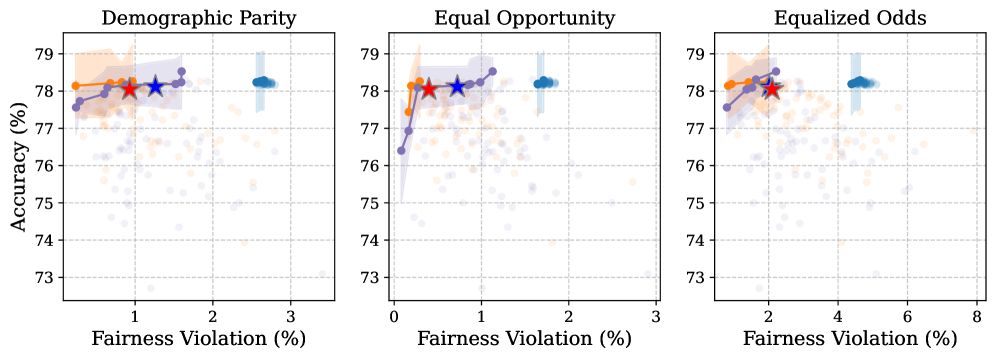
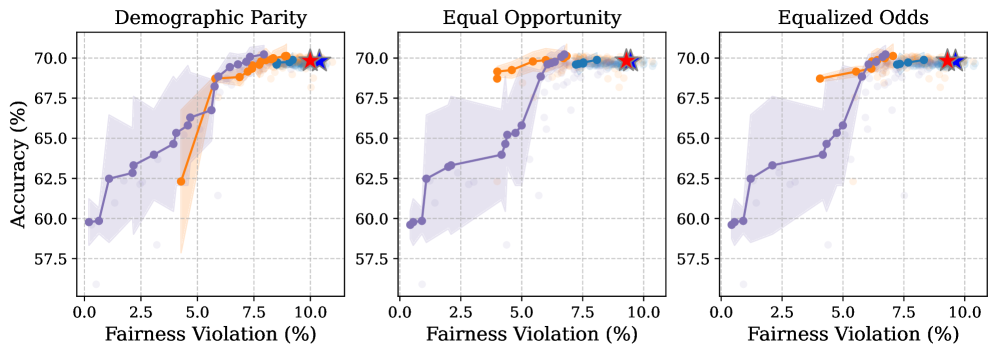
- 实验结果表明,该策略在提升人口统计均等性等公平性指标的同时,对预测准确性的影响很小。
📝 摘要(中文)
基于Transformer的表格基础模型最近在表格数据的上下文学习(ICL)方面表现出良好的性能,成为梯度提升树的有竞争力的替代方案。然而,这种新范式的公平性影响在很大程度上仍未被探索。我们首次研究了表格ICL中的公平性问题,评估了最近提出的三个基础模型--TabPFNv2、TabICL和TabDPT--在多个基准数据集上的表现。为了缓解偏差,我们探索了三种预处理的公平性增强方法:相关性移除(将输入特征与敏感属性去相关)、组平衡样本选择(确保受保护群体在上下文示例中具有相等的代表性)和基于不确定性的样本选择(优先考虑具有高敏感属性预测不确定性的上下文示例)。我们的实验表明,基于不确定性的策略始终如一地提高了群体公平性指标(例如,人口统计均等性、均等机会和均等赔率),同时对预测准确性的影响最小。我们发布了代码以方便重现。
🔬 方法详解
问题定义:表格基础模型在上下文学习中展现潜力,但其潜在的偏见可能导致对特定人群的不公平预测。现有方法缺乏对表格ICL公平性的系统性研究,并且没有有效的缓解策略。
核心思路:论文的核心思路是通过预处理阶段的样本选择来提升模型的公平性。具体而言,优先选择那些模型在预测敏感属性时具有较高不确定性的样本作为上下文示例。这样做的目的是让模型更多地关注那些容易产生偏见的样本,从而减少整体的偏见。
技术框架:整体框架包括三个主要步骤:1) 使用表格基础模型(如TabPFNv2, TabICL, TabDPT)进行初步预测;2) 使用三种预处理方法(相关性移除、组平衡样本选择、不确定性采样)选择上下文示例;3) 使用选择后的上下文示例进行ICL,并评估模型的公平性和准确性。
关键创新:关键创新在于提出了基于不确定性的样本选择策略,该策略能够有效地识别并优先选择那些容易导致偏见的样本。与传统的公平性增强方法(如相关性移除和组平衡采样)相比,该方法能够更直接地解决ICL中的公平性问题。
关键设计:不确定性度量是关键设计。论文可能使用了诸如熵、方差或模型置信度等指标来衡量预测的不确定性。具体实现细节未知,但核心思想是选择那些模型预测结果最不确定的样本。此外,如何平衡公平性和准确性也是一个关键设计点,论文通过实验证明了该方法在提升公平性的同时,对准确性的影响很小。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于不确定性的样本选择策略能够显著提升表格ICL的公平性,例如在人口统计均等性、均等机会和均等赔率等指标上均有提升。更重要的是,这种提升是在对预测准确性影响最小的情况下实现的,表明该方法能够在公平性和准确性之间取得良好的平衡。具体提升幅度未知,需要参考论文原文。
🎯 应用场景
该研究成果可应用于金融风控、医疗诊断、招聘筛选等领域,在这些领域中,表格数据被广泛使用,并且公平性至关重要。通过提升表格基础模型在ICL中的公平性,可以减少算法歧视,确保不同群体受到公平对待,从而构建更负责任和可信赖的AI系统。
📄 摘要(原文)
Transformer-based tabular foundation models have recently demonstrated promising in-context learning (ICL) performance on structured data, emerging as competitive alternatives to gradient-boosted trees. However, the fairness implications of this new paradigm remain largely unexplored. We present the first investigation of fairness in tabular ICL, evaluating three recently proposed foundation models--TabPFNv2, TabICL, and TabDPT--on multiple benchmark datasets. To mitigate biases, we explore three pre-processing fairness-enhancing methods: correlation removal (decorrelating input features from the sensitive attribute), group-balanced sample selection (ensuring equal representation of protected groups in context examples), and uncertainty-based sample selection (prioritizing context examples with high sensitive-attribute prediction uncertainty). Our experiments show that the uncertainty-based strategy consistently improves group fairness metrics (e.g., demographic parity, equalized odds, and equal opportunity) with minimal impact on predictive accuracy. We release our code to facilitate reproducibility https://github.com/patrikken/Fair-TabICL.