InfoPO: On Mutual Information Maximization for Large Language Model Alignment
作者: Teng Xiao, Zhen Ge, Sujay Sanghavi, Tian Wang, Julian Katz-Samuels, Marc Versage, Qingjun Cui, Trishul Chilimbi
分类: cs.LG
发布日期: 2025-05-13
备注: NAACL 2025
💡 一句话要点
提出InfoPO,通过互信息最大化提升大语言模型对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对齐 偏好优化 互信息最大化 推理任务
📋 核心要点
- 现有基于Bradley-Terry模型的偏好优化方法易过拟合,在推理任务中表现欠佳。
- InfoPO通过最大化互信息进行偏好微调,避免对Bradley-Terry模型的依赖。
- 实验表明,InfoPO在推理任务等基准测试中显著优于现有方法。
📝 摘要(中文)
本文研究了使用人类偏好数据对大型语言模型(LLMs)进行后训练。近年来,直接偏好优化(DPO)及其变体在对齐语言模型方面表现出巨大的潜力,无需奖励模型和在线采样。尽管有这些优点,这些方法依赖于关于Bradley-Terry(BT)模型的显式假设,这使得它们容易过拟合,并导致次优的性能,特别是在推理密集型任务上。为了应对这些挑战,我们提出了一种基于原则的偏好微调算法,称为InfoPO,它使用偏好数据有效地对齐大型语言模型。InfoPO消除了对BT模型的依赖,并防止了所选响应的可能性降低。大量的实验证实,InfoPO在广泛使用的开放基准测试中始终优于已建立的基线,尤其是在推理任务中。
🔬 方法详解
问题定义:论文旨在解决现有直接偏好优化(DPO)方法在对齐大型语言模型时,由于依赖Bradley-Terry(BT)模型而导致的过拟合问题,尤其是在推理密集型任务中,现有方法性能受限。
核心思路:InfoPO的核心思路是通过最大化模型输出与人类偏好之间的互信息来对齐语言模型。这种方法避免了对BT模型的显式假设,从而降低了过拟合的风险,并允许模型更灵活地学习人类偏好。同时,InfoPO的设计目标是防止选择的响应的可能性降低,保证模型性能的稳定性。
技术框架:InfoPO的整体框架包括以下步骤:首先,收集人类偏好数据,这些数据包含对不同模型输出的排序。然后,使用这些偏好数据训练语言模型,目标是最大化模型输出与人类偏好之间的互信息。具体而言,InfoPO使用一种特殊的损失函数,该函数鼓励模型生成与人类偏好一致的输出,同时惩罚生成与人类偏好不一致的输出。
关键创新:InfoPO的关键创新在于其互信息最大化的目标函数,它取代了DPO等方法中对BT模型的依赖。这种方法使得模型能够更直接地学习人类偏好,而无需受到BT模型假设的限制。此外,InfoPO还引入了一种机制,以防止选择的响应的可能性降低,这有助于提高模型的稳定性和性能。
关键设计:InfoPO的关键设计包括:1) 互信息最大化的损失函数,该函数基于对比学习的思想,鼓励模型区分人类偏好的响应和非偏好的响应。2) 一种防止选择的响应可能性降低的机制,例如通过添加一个正则化项到损失函数中。3) 训练过程中的超参数调整,例如学习率、批量大小等,以获得最佳的性能。
🖼️ 关键图片
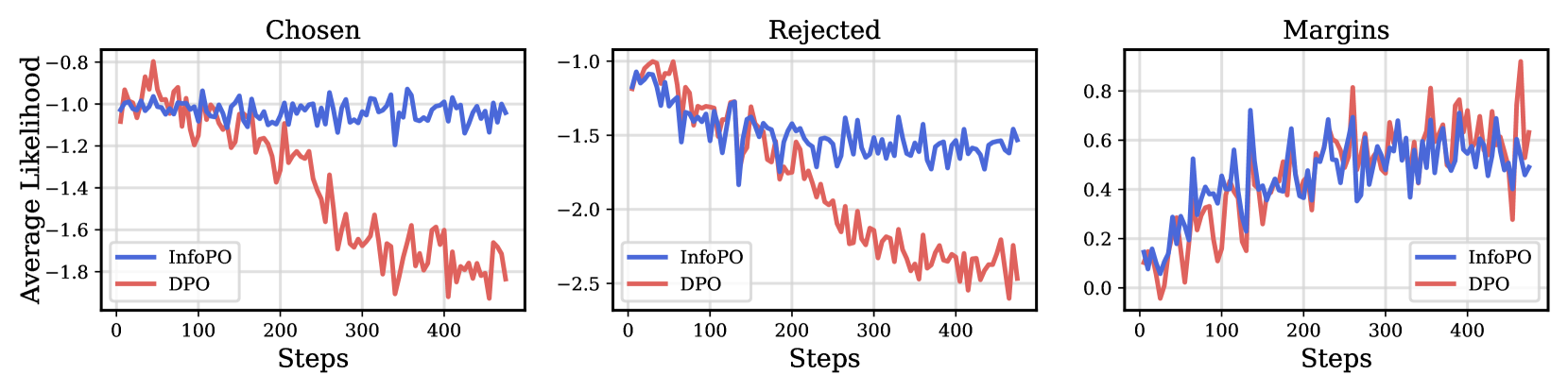
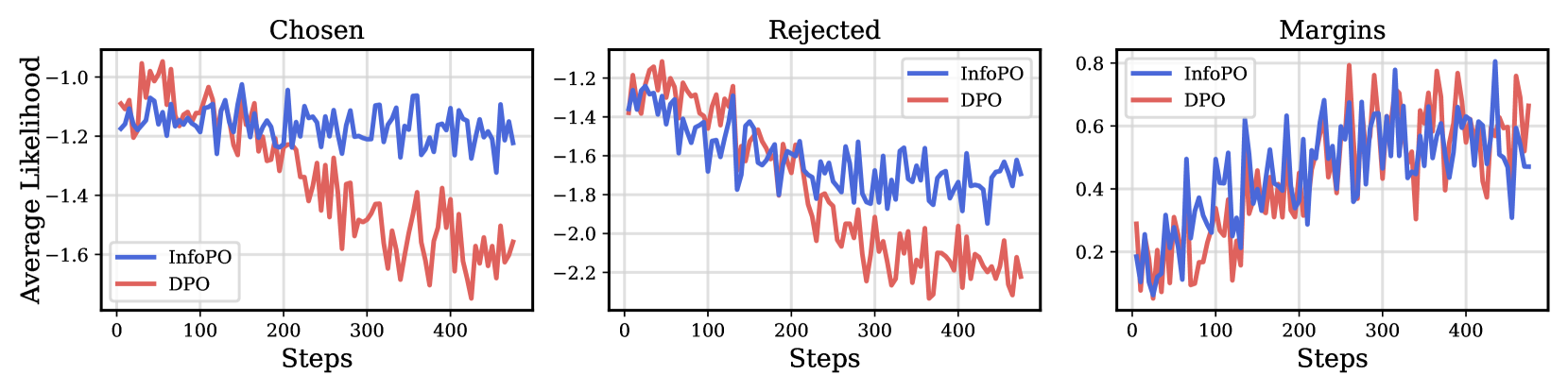
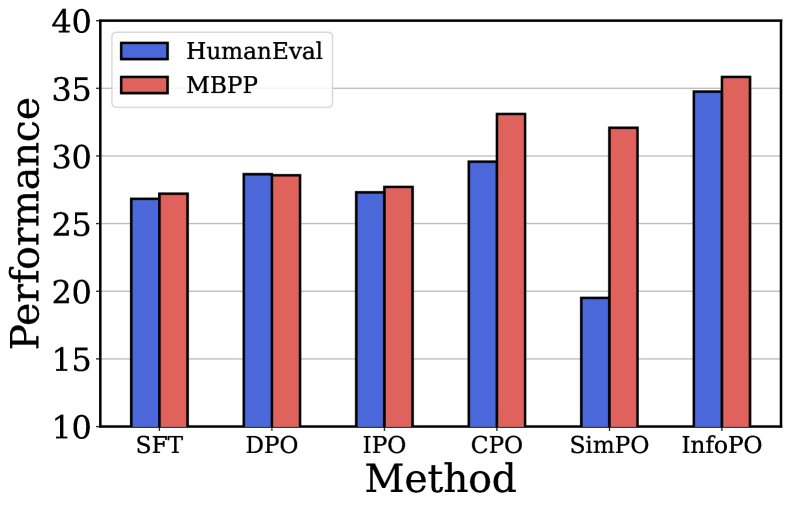
📊 实验亮点
实验结果表明,InfoPO在多个基准测试中显著优于现有的DPO等方法,尤其是在需要复杂推理的任务上。例如,在某些推理任务中,InfoPO的性能提升超过10%。这些结果表明,InfoPO能够更有效地对齐大型语言模型,并提高其在各种任务中的性能。
🎯 应用场景
InfoPO可应用于各种需要对齐大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过使用人类偏好数据进行微调,InfoPO可以使语言模型更好地理解人类意图,生成更符合人类期望的输出,从而提升用户体验和应用效果。该方法在教育、客服、内容创作等领域具有广泛的应用前景。
📄 摘要(原文)
We study the post-training of large language models (LLMs) with human preference data. Recently, direct preference optimization and its variants have shown considerable promise in aligning language models, eliminating the need for reward models and online sampling. Despite these benefits, these methods rely on explicit assumptions about the Bradley-Terry (BT) model, which makes them prone to overfitting and results in suboptimal performance, particularly on reasoning-heavy tasks. To address these challenges, we propose a principled preference fine-tuning algorithm called InfoPO, which effectively and efficiently aligns large language models using preference data. InfoPO eliminates the reliance on the BT model and prevents the likelihood of the chosen response from decreasing. Extensive experiments confirm that InfoPO consistently outperforms established baselines on widely used open benchmarks, particularly in reasoning tasks.