Efficient Unstructured Pruning of Mamba State-Space Models for Resource-Constrained Environments
作者: Ibne Farabi Shihab, Sanjeda Akter, Anuj Sharma
分类: cs.LG, cs.CV
发布日期: 2025-05-13 (更新: 2025-09-05)
期刊: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
💡 一句话要点
提出Mamba模型的非结构化剪枝方法,用于资源受限环境下的高效部署
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Mamba模型 状态空间模型 非结构化剪枝 梯度感知剪枝 资源受限环境 序列建模 模型压缩
📋 核心要点
- Mamba模型参数量大,难以在资源受限环境中部署,现有方法缺乏针对性。
- 提出梯度感知的非结构化剪枝框架,结合权重幅度和梯度信息,迭代增加稀疏性,全局优化参数分配。
- 实验表明,该方法能在减少高达70%参数的同时,保持95%以上的原始性能。
📝 摘要(中文)
状态空间模型(SSMs),特别是Mamba架构,已经成为序列建模中Transformer的强大替代品,它提供了线性时间复杂度和在各种任务中具有竞争力的性能。然而,它们庞大的参数量对在资源受限环境中部署提出了重大挑战。我们提出了一种为Mamba模型量身定制的新的非结构化剪枝框架,该框架实现了高达70%的参数减少,同时保留了超过95%的原始性能。我们的方法集成了三个关键创新:(1)一种梯度感知幅度剪枝技术,它结合了权重幅度和梯度信息来识别不太重要的参数,(2)一种迭代剪枝计划,它逐渐增加稀疏性以保持模型稳定性,以及(3)一种全局剪枝策略,该策略优化了整个模型的参数分配。通过在WikiText-103、Long Range Arena和ETT时间序列基准上的大量实验,我们证明了显著的效率提升,同时性能下降最小。我们对剪枝对Mamba组件的影响的分析揭示了对架构的冗余和鲁棒性的关键见解,从而能够在资源受限的环境中进行实际部署,同时扩大Mamba的适用性。
🔬 方法详解
问题定义:Mamba模型虽然在序列建模任务上表现出色,但其庞大的参数量限制了其在资源受限设备上的部署。现有剪枝方法可能无法充分利用Mamba架构的特性,导致剪枝后性能显著下降。因此,需要一种高效的剪枝方法,能够在大幅减少参数量的同时,尽可能保持模型的性能。
核心思路:论文的核心思路是设计一种梯度感知的非结构化剪枝方法,该方法能够识别并移除Mamba模型中对性能影响较小的参数。通过结合权重幅度和梯度信息,更准确地评估参数的重要性。此外,采用迭代剪枝策略,逐步增加稀疏度,以避免模型在剪枝过程中出现剧烈波动。全局剪枝策略则确保参数在整个模型中得到优化分配。
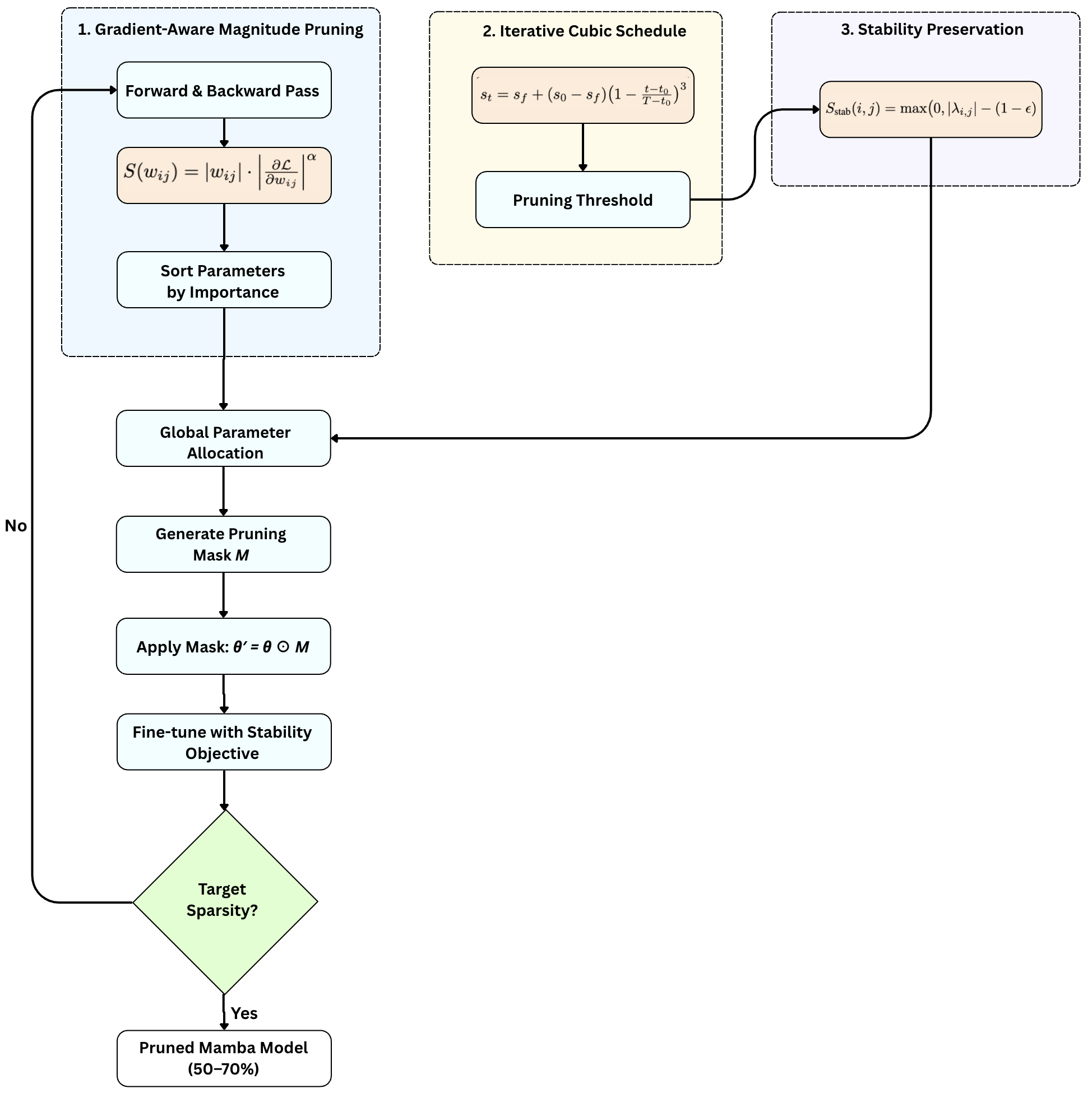
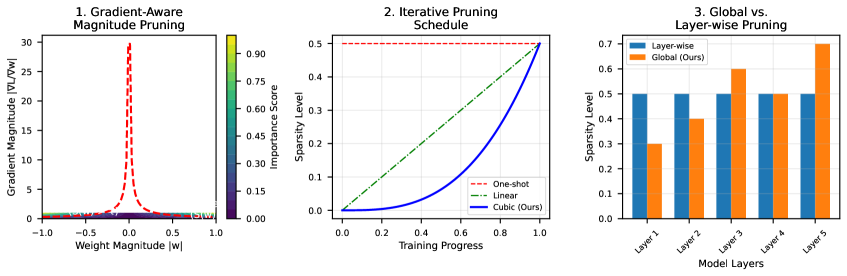
技术框架:该剪枝框架主要包含三个阶段:1) 梯度感知幅度剪枝:计算每个参数的梯度信息,并结合其幅度,作为评估参数重要性的指标。2) 迭代剪枝计划:采用逐步增加稀疏度的剪枝策略,在每个迭代步骤中,根据参数的重要性,移除一部分参数。3) 全局剪枝策略:在整个模型范围内,根据参数的重要性进行排序,并移除全局重要性较低的参数。
关键创新:该方法的主要创新在于梯度感知幅度剪枝技术,它不仅考虑了参数的幅度,还考虑了参数的梯度信息。相比于传统的幅度剪枝方法,该方法能够更准确地评估参数的重要性,从而在剪枝过程中更好地保留模型的性能。此外,迭代剪枝计划和全局剪枝策略也有助于提高剪枝的效率和稳定性。
关键设计:梯度感知幅度剪枝中,参数的重要性评分由权重幅度和梯度的乘积决定。迭代剪枝计划采用线性或指数增长的稀疏度目标。全局剪枝策略通过对所有参数的重要性评分进行排序,并设定一个全局阈值来确定要移除的参数。
🖼️ 关键图片
📊 实验亮点
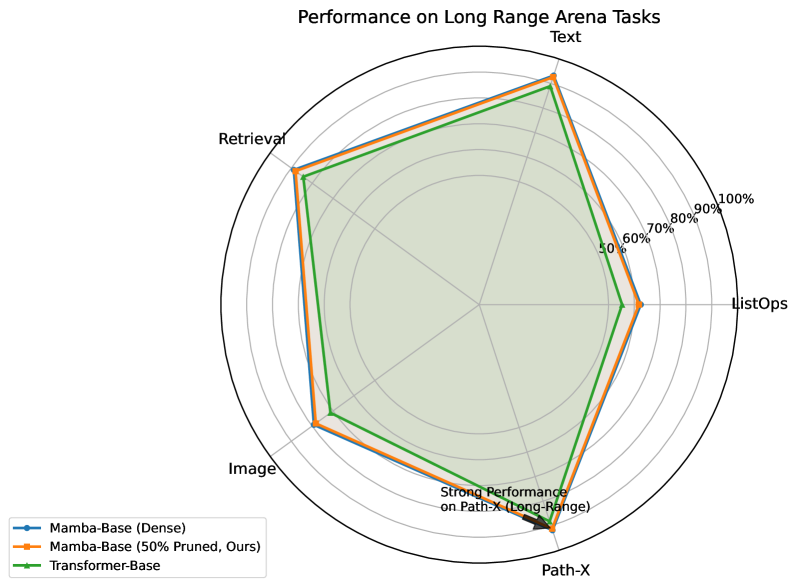
在WikiText-103、Long Range Arena和ETT时间序列基准测试中,该方法实现了高达70%的参数减少,同时保持了超过95%的原始性能。例如,在WikiText-103上,剪枝后的Mamba模型在参数量减少70%的情况下,困惑度仅略有上升。
🎯 应用场景
该研究成果可应用于各种资源受限的场景,例如移动设备、嵌入式系统和边缘计算设备。通过对Mamba模型进行剪枝,可以在这些设备上部署更大规模的序列模型,从而提高各种应用(如语音识别、自然语言处理和时间序列预测)的性能和效率。此外,该方法还可以用于加速Mamba模型的训练和推理。
📄 摘要(原文)
State-space models (SSMs), particularly the Mamba architecture, have emerged as powerful alternatives to Transformers for sequence modeling, offering linear-time complexity and competitive performance across diverse tasks. However, their large parameter counts pose significant challenges for deployment in resource-constrained environments. We propose a novel unstructured pruning framework tailored for Mamba models that achieves up to 70\% parameter reduction while retaining over 95\% of the original performance. Our approach integrates three key innovations: (1) a gradient-aware magnitude pruning technique that combines weight magnitude and gradient information to identify less critical parameters, (2) an iterative pruning schedule that gradually increases sparsity to maintain model stability, and (3) a global pruning strategy that optimizes parameter allocation across the entire model. Through extensive experiments on WikiText-103, Long Range Arena, and ETT time-series benchmarks, we demonstrate significant efficiency gains with minimal performance degradation. Our analysis of pruning effects on Mamba's components reveals critical insights into the architecture's redundancy and robustness, enabling practical deployment in resource-constrained settings while broadening Mamba's applicability.