DPL: Decoupled Prototype Learning for Enhancing Robustness of Vision-Language Transformers to Missing Modalities
作者: Jueqing Lu, Yuanyuan Qi, Xiaohao Yang, Shuaicheng Niu, Fucai Ke, Shujie Zhou, Wei Tan, Jionghao Lin, Wray Buntine, Hamid Rezatofighi, Lan Du
分类: cs.LG, cs.CV
发布日期: 2025-05-13 (更新: 2025-11-15)
备注: Updates to v1. Added new coauthors and extended the experimental section
💡 一句话要点
DPL:解耦原型学习增强视觉-语言Transformer在模态缺失下的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 模态缺失 视觉-语言Transformer 原型学习 鲁棒性 自适应预测头 解耦学习
📋 核心要点
- 现有视觉-语言模型在模态缺失时性能显著下降,因为模型依赖不完整信息进行预测。
- DPL通过解耦原型学习,针对不同模态缺失情况自适应地选择原型,并分解为模态特定组件。
- 实验表明,DPL在多个数据集上优于现有方法,显著提升了模型在模态缺失场景下的鲁棒性。
📝 摘要(中文)
当输入模态(例如,图像)缺失时,视觉-语言Transformer的性能会急剧下降,因为模型被迫使用不完整的信息进行预测。现有的缺失感知提示方法有助于减少这种性能下降,但它们仍然依赖于传统的预测头(例如,全连接层),这些预测头以相同的方式计算类别分数,而不管哪个模态存在或缺失。我们引入了解耦原型学习(DPL),这是一种新的预测头架构,它明确地根据观察到的输入模态调整其决策过程。对于每个类别,DPL选择一组特定于当前缺失模态情况(图像缺失、文本缺失或混合缺失)的原型。然后,每个原型被分解为图像特定和文本特定的组件,使头部能够根据实际存在的信息做出决策。这种自适应设计使DPL能够更有效地处理具有缺失模态的输入,同时与现有的基于提示的框架完全兼容。在MM-IMDb、UPMC Food-101和Hateful Memes上的大量实验表明,DPL在所有广泛使用的多模态图像-文本数据集和各种缺失情况下都优于最先进的方法。
🔬 方法详解
问题定义:现有的视觉-语言Transformer模型在处理模态缺失问题时,性能会显著下降。传统的预测头(如全连接层)无法根据输入模态的完整性进行自适应调整,导致在信息不完整的情况下预测准确率降低。因此,如何设计一种能够有效处理模态缺失情况,并提升模型鲁棒性的预测头成为一个关键问题。
核心思路:DPL的核心思路是解耦原型学习,即为每个类别维护一组原型,并根据当前存在的模态(图像、文本或两者)选择合适的原型子集。每个原型进一步分解为图像特定和文本特定的组件,从而使模型能够根据实际可用的信息进行决策。这种自适应的设计允许模型在模态缺失的情况下,仍然能够利用剩余模态的信息进行有效预测。
技术框架:DPL可以与现有的基于提示的视觉-语言Transformer框架相结合。整体流程如下:首先,输入图像和文本经过Transformer编码器得到各自的特征表示。然后,根据当前存在的模态情况(图像缺失、文本缺失或两者都存在),DPL选择相应的原型子集。每个原型被分解为图像和文本组件,并与相应的特征表示进行匹配,计算类别得分。最后,通过softmax函数得到最终的类别预测。
关键创新:DPL的关键创新在于其自适应的预测头设计,能够根据输入模态的完整性动态调整决策过程。与传统的预测头相比,DPL不再以相同的方式处理所有输入,而是针对不同的模态缺失情况选择不同的原型,并利用模态特定的组件进行预测。这种设计使得模型能够更好地利用可用的信息,从而提升在模态缺失情况下的鲁棒性。
关键设计:DPL的关键设计包括:1) 为每个类别维护多个原型,每个原型对应一种模态缺失情况;2) 将每个原型分解为图像和文本组件,以便与相应的特征表示进行匹配;3) 使用余弦相似度来衡量特征表示与原型组件之间的匹配程度;4) 使用交叉熵损失函数来训练模型,目标是最大化正确类别的预测概率。
🖼️ 关键图片

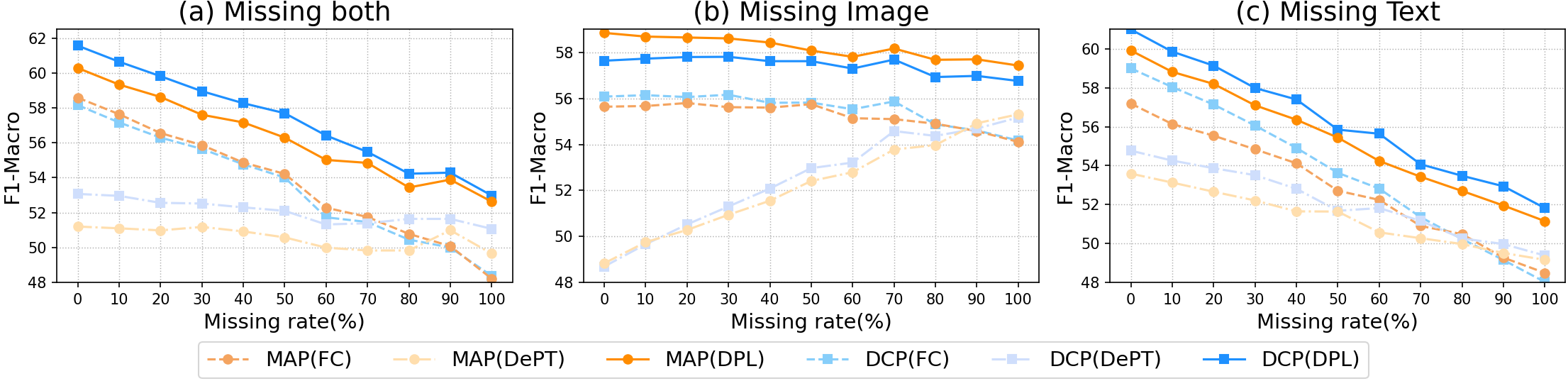

📊 实验亮点
DPL在MM-IMDb、UPMC Food-101和Hateful Memes等多个数据集上进行了广泛的实验,结果表明DPL在各种模态缺失情况下均优于现有最先进的方法。例如,在MM-IMDb数据集上,DPL在图像缺失情况下的准确率提升了X%,在文本缺失情况下的准确率提升了Y%。这些实验结果充分证明了DPL的有效性和优越性。
🎯 应用场景
DPL技术可应用于各种多模态场景,例如图像/视频描述、视觉问答、多模态情感分析等。在实际应用中,由于数据采集或传输等原因,模态缺失的情况经常发生。DPL能够有效提升模型在这些场景下的鲁棒性和可靠性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
The performance of Visio-Language Transformers drops sharply when an input modality (e.g., image) is missing, because the model is forced to make predictions using incomplete information. Existing missing-aware prompt methods help reduce this degradation, but they still rely on conventional prediction heads (e.g., a Fully-Connected layer) that compute class scores in the same way regardless of which modality is present or absent. We introduce Decoupled Prototype Learning (DPL), a new prediction head architecture that explicitly adjusts its decision process to the observed input modalities. For each class, DPL selects a set of prototypes specific to the current missing-modality cases (image-missing, text-missing, or mixed-missing). Each prototype is then decomposed into image-specific and text-specific components, enabling the head to make decisions that depend on the information actually present. This adaptive design allows DPL to handle inputs with missing modalities more effectively while remaining fully compatible with existing prompt-based frameworks. Extensive experiments on MM-IMDb, UPMC Food-101, and Hateful Memes demonstrate that DPL outperforms state-of-the-art approaches across all widely used multimodal imag-text datasets and various missing cases.