Privacy-Preserving Analytics for Smart Meter (AMI) Data: A Hybrid Approach to Comply with CPUC Privacy Regulations
作者: Benjamin Westrich
分类: cs.CR, cs.LG, stat.ML
发布日期: 2025-05-13
💡 一句话要点
提出混合隐私保护架构,解决智能电表数据分析中的隐私合规问题
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 智能电表数据 隐私保护 差分隐私 联邦学习 合成数据 安全多方计算 同态加密
📋 核心要点
- 智能电表数据分析面临严格的隐私保护要求,现有方法难以兼顾数据效用和隐私合规性。
- 论文提出一种混合隐私保护架构,结合数据匿名化、隐私保护机器学习、合成数据生成和密码学技术。
- 该架构旨在满足加州隐私法规和FIPPs,同时支持能源消耗数据的高级分析,并提供了详细的数学证明和实践指导。
📝 摘要(中文)
智能电表(AMI)数据为公用事业和消费者提供了有价值的洞察,但也引发了严重的隐私问题。在加利福尼亚州,监管决策要求对客户能源使用数据进行严格的隐私保护,并遵循公平信息实践原则(FIPPs)。本文全面探讨了数据匿名化、隐私保护机器学习(差分隐私和联邦学习)、合成数据生成和密码学技术(安全多方计算、同态加密)等解决方案。这使得能够在不损害个人隐私的情况下,对能源消耗数据进行包括机器学习模型、统计和计量经济学分析在内的高级分析。我们评估了每种技术在公用事业数据分析中的理论基础、有效性和权衡,并提出了一个集成架构,结合这些方法来满足实际需求。该混合架构旨在确保符合加州隐私规则和FIPPs,同时支持有用的分析,从预测和个性化洞察到学术研究和计量经济学,同时严格保护个人隐私。提供了数学定义和推导,以严格证明隐私保证和效用影响。我们包括了这些技术的比较评估、架构图和流程图,以说明它们如何在实践中协同工作。最终形成了一个蓝图,供公用事业数据科学家和工程师在AMI数据处理中实施隐私设计,支持数据驱动的创新和严格的法规遵从。
🔬 方法详解
问题定义:智能电表数据包含用户的详细用电信息,直接发布或分析会泄露用户隐私。加州CPUC的规定要求对这些数据进行严格的隐私保护,但同时也需要利用这些数据进行有价值的分析,例如预测、个性化推荐和经济研究。现有方法,如简单的数据匿名化,可能无法提供足够的隐私保护,而过于严格的隐私保护措施又会降低数据的可用性。
核心思路:论文的核心思路是采用一种混合的隐私保护方法,将多种技术结合起来,以达到在隐私保护和数据效用之间的最佳平衡。不同的技术在不同的场景下有不同的优势和劣势,通过组合使用,可以克服单一技术的局限性。例如,可以使用差分隐私来保护机器学习模型的训练过程,使用合成数据来支持统计分析,并使用安全多方计算来执行需要多个数据所有者参与的计算。
技术框架:论文提出的混合架构包含以下几个主要模块:1) 数据预处理和匿名化:对原始数据进行清洗和初步的匿名化处理,例如删除标识符。2) 隐私保护机器学习:使用差分隐私或联邦学习等技术训练机器学习模型。3) 合成数据生成:生成与原始数据统计特征相似的合成数据,用于支持统计分析和研究。4) 安全多方计算和同态加密:使用密码学技术执行需要多个数据所有者参与的计算,同时保护数据的隐私。5) 隐私审计和合规性检查:定期对系统进行审计,确保其符合隐私法规和FIPPs。
关键创新:该论文的关键创新在于提出了一种集成的隐私保护架构,而不是仅仅依赖于单一的技术。这种混合方法可以根据具体的应用场景和隐私需求,灵活地选择和组合不同的技术,从而达到最佳的隐私保护和数据效用平衡。此外,论文还提供了详细的数学证明和实践指导,帮助公用事业公司实施隐私设计。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节,因为这些细节会根据具体的应用场景和所选择的隐私保护技术而有所不同。但是,论文强调了在选择和配置这些技术时需要考虑的因素,例如隐私预算、数据效用和计算成本。对于差分隐私,需要仔细选择隐私预算参数ε和δ,以控制隐私泄露的风险。对于联邦学习,需要设计合适的模型结构和训练策略,以确保模型的准确性和泛化能力。对于合成数据生成,需要选择合适的生成模型,并使用适当的评估指标来衡量合成数据的质量。
🖼️ 关键图片
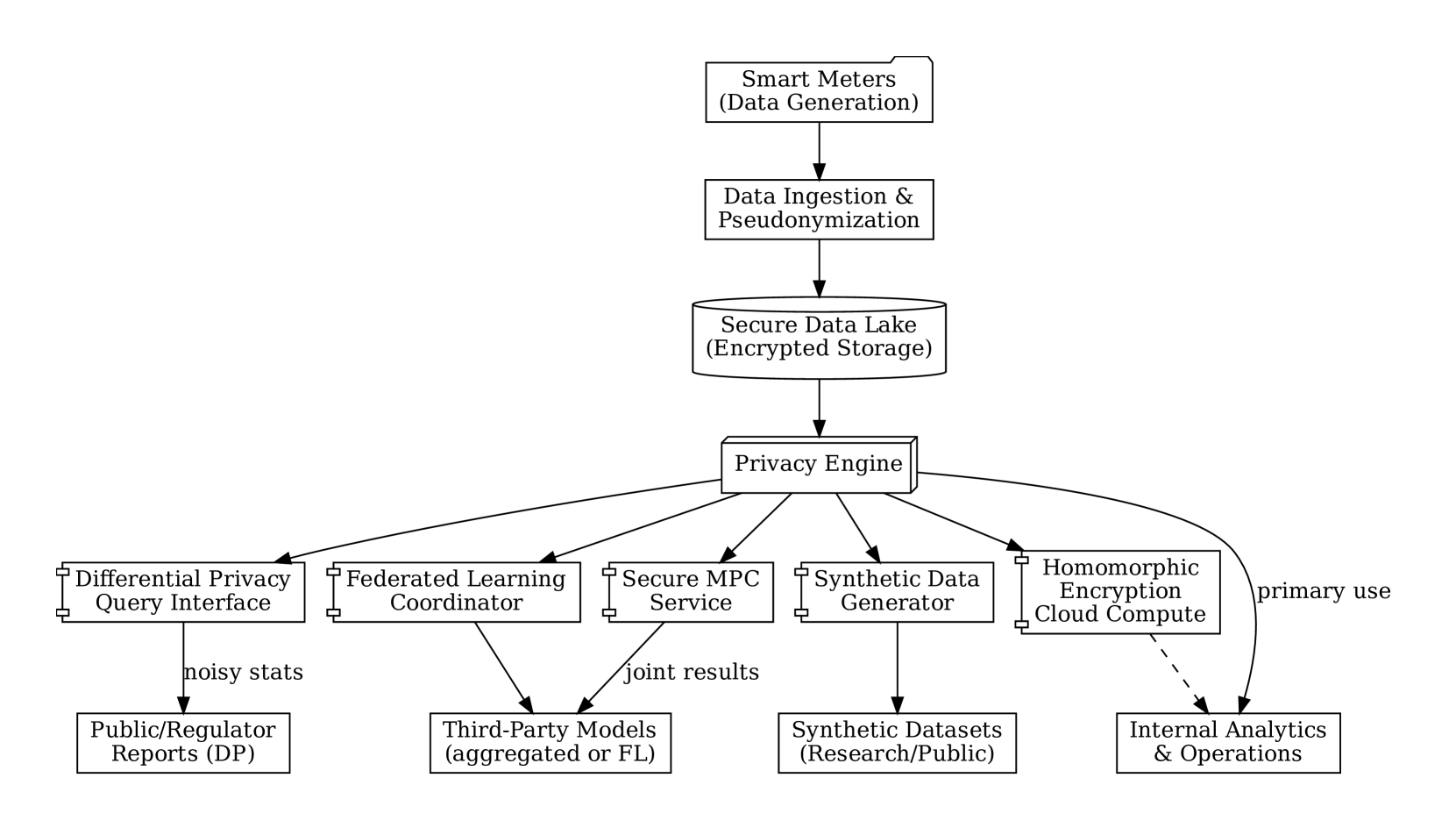
📊 实验亮点
论文提出了一个集成的隐私保护架构,并对各种隐私保护技术进行了比较评估。虽然没有提供具体的性能数据,但论文强调了该架构在满足加州隐私法规和FIPPs方面的优势,并提供了详细的数学证明和实践指导。该架构旨在在隐私保护和数据效用之间达到最佳平衡,支持各种高级分析应用。
🎯 应用场景
该研究成果可应用于智能电网数据分析、医疗健康数据共享、金融数据安全等领域。通过该混合隐私保护架构,可以在保护用户隐私的前提下,实现数据驱动的创新,例如智能电网的优化运行、个性化医疗服务的提供、金融风险的有效控制。该研究有助于推动数据安全共享和利用,促进相关产业的健康发展。
📄 摘要(原文)
Advanced Metering Infrastructure (AMI) data from smart electric and gas meters enables valuable insights for utilities and consumers, but also raises significant privacy concerns. In California, regulatory decisions (CPUC D.11-07-056 and D.11-08-045) mandate strict privacy protections for customer energy usage data, guided by the Fair Information Practice Principles (FIPPs). We comprehensively explore solutions drawn from data anonymization, privacy-preserving machine learning (differential privacy and federated learning), synthetic data generation, and cryptographic techniques (secure multiparty computation, homomorphic encryption). This allows advanced analytics, including machine learning models, statistical and econometric analysis on energy consumption data, to be performed without compromising individual privacy. We evaluate each technique's theoretical foundations, effectiveness, and trade-offs in the context of utility data analytics, and we propose an integrated architecture that combines these methods to meet real-world needs. The proposed hybrid architecture is designed to ensure compliance with California's privacy rules and FIPPs while enabling useful analytics, from forecasting and personalized insights to academic research and econometrics, while strictly protecting individual privacy. Mathematical definitions and derivations are provided where appropriate to demonstrate privacy guarantees and utility implications rigorously. We include comparative evaluations of the techniques, an architecture diagram, and flowcharts to illustrate how they work together in practice. The result is a blueprint for utility data scientists and engineers to implement privacy-by-design in AMI data handling, supporting both data-driven innovation and strict regulatory compliance.