DSADF: Thinking Fast and Slow for Decision Making
作者: Zhihao Dou, Dongfei Cui, Jun Yan, Weida Wang, Benteng Chen, Haoming Wang, Zeke Xie, Shufei Zhang
分类: cs.LG, cs.AI
发布日期: 2025-05-13 (更新: 2025-08-25)
💡 一句话要点
提出DSADF双系统决策框架,提升强化学习智能体在动态环境中的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 视觉语言模型 双系统 决策框架 动态环境 泛化能力 自适应决策
📋 核心要点
- 现有强化学习方法在动态环境中泛化能力不足,且与大型语言模型或视觉语言模型的结合缺乏有效协调。
- DSADF框架模仿人类快慢思考模式,利用强化学习智能体和视觉语言模型分别进行快速决策和深度推理。
- 在Crafter和Housekeep游戏中,DSADF显著提升了智能体在已知和未知任务中的决策能力。
📝 摘要(中文)
强化学习(RL)智能体在定义明确的环境中表现出色,但由于依赖试错交互,难以将其学习到的策略泛化到动态环境中。最近的研究探索了应用大型语言模型(LLM)或视觉语言模型(VLM)来通过策略优化指导或先验知识来提升RL智能体的泛化能力。然而,这些方法通常缺乏RL智能体和基础模型之间的无缝协调,导致在不熟悉的环境中做出不合理的决策并产生效率瓶颈。如何充分利用基础模型的推理能力和RL智能体的快速响应能力,并加强两者之间的交互以形成双系统,仍然是一个悬而未决的科学问题。为了解决这个问题,我们从卡尼曼的快思考(系统1)和慢思考(系统2)理论中汲取灵感,证明平衡直觉和深度推理可以在复杂世界中实现灵活的决策。在本研究中,我们提出了一个双系统自适应决策框架(DSADF),集成了两个互补的模块:系统1,包括一个RL智能体和一个用于快速直观决策的记忆空间;系统2,由VLM驱动,用于深度分析推理。DSADF通过结合两个系统的优势,促进高效和自适应的决策。在视频游戏环境Crafter和Housekeep中的实证研究表明了我们提出的方法的有效性,显示了对未见和已知任务的决策能力的显著改进。
🔬 方法详解
问题定义:论文旨在解决强化学习智能体在动态、未知的环境中泛化能力差的问题。现有方法要么过度依赖试错,要么与大型语言模型/视觉语言模型的结合不够紧密,导致决策效率低下或不合理。这些方法无法充分利用基础模型的推理能力和强化学习智能体的快速反应能力。
核心思路:论文的核心思路是借鉴人类的“快思考”和“慢思考”双系统模型。通过构建一个包含快速反应的强化学习智能体(系统1)和深度推理的视觉语言模型(系统2)的框架,实现快速、直观的决策与深度、分析的推理之间的平衡。这种设计旨在提高智能体在复杂环境中的适应性和决策质量。
技术框架:DSADF框架包含两个主要模块:系统1和系统2。系统1由一个强化学习智能体和一个记忆空间组成,负责快速、直观的决策。系统2由一个视觉语言模型驱动,负责深度分析推理。整体流程是:首先,系统1基于当前环境状态和记忆进行快速决策;然后,系统2对环境状态进行分析,并对系统1的决策进行评估和修正;最后,系统1根据系统2的反馈更新其策略和记忆。
关键创新:该论文的关键创新在于提出了一个双系统自适应决策框架,将强化学习智能体的快速决策能力与视觉语言模型的深度推理能力相结合。与现有方法相比,DSADF能够更有效地利用基础模型的知识,并在动态环境中做出更合理、更高效的决策。
关键设计:论文中关键的设计包括:1. 如何选择合适的强化学习算法作为系统1的基础;2. 如何选择合适的视觉语言模型作为系统2的基础;3. 如何设计系统1和系统2之间的交互机制,例如,系统2如何评估和修正系统1的决策;4. 如何设计记忆空间,以便系统1能够快速访问和利用历史经验。具体的参数设置、损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


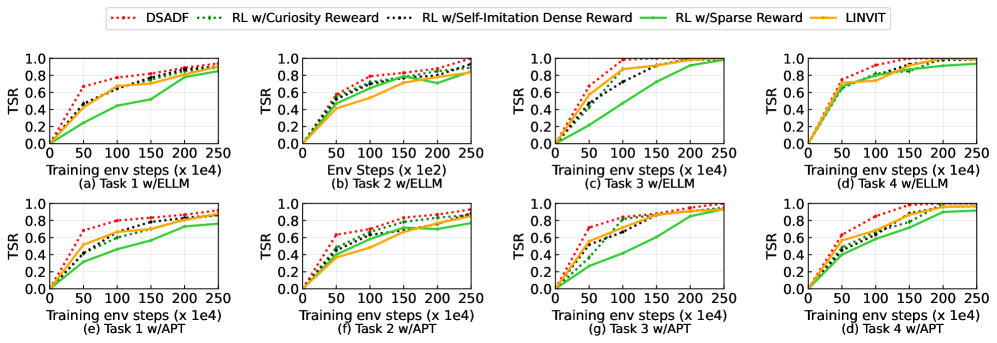
📊 实验亮点
实验结果表明,DSADF在Crafter和Housekeep游戏中显著提升了智能体的决策能力。具体性能数据和对比基线在摘要中未给出,属于未知信息。但论文强调,DSADF在未见过的任务中也表现出良好的泛化能力,证明了其有效性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域,尤其是在需要智能体在复杂、动态环境中做出快速、合理决策的场景。通过结合强化学习的快速反应能力和视觉语言模型的深度推理能力,可以提升智能体的适应性和决策质量,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Although Reinforcement Learning (RL) agents are effective in well-defined environments, they often struggle to generalize their learned policies to dynamic settings due to their reliance on trial-and-error interactions. Recent work has explored applying Large Language Models (LLMs) or Vision Language Models (VLMs) to boost the generalization of RL agents through policy optimization guidance or prior knowledge. However, these approaches often lack seamless coordination between the RL agent and the foundation model, leading to unreasonable decision-making in unfamiliar environments and efficiency bottlenecks. Making full use of the inferential capabilities of foundation models and the rapid response capabilities of RL agents and enhancing the interaction between the two to form a dual system is still a lingering scientific question. To address this problem, we draw inspiration from Kahneman's theory of fast thinking (System 1) and slow thinking (System 2), demonstrating that balancing intuition and deep reasoning can achieve nimble decision-making in a complex world. In this study, we propose a Dual-System Adaptive Decision Framework (DSADF), integrating two complementary modules: System 1, comprising an RL agent and a memory space for fast and intuitive decision making, and System 2, driven by a VLM for deep and analytical reasoning. DSADF facilitates efficient and adaptive decision-making by combining the strengths of both systems. The empirical study in the video game environment: Crafter and Housekeep demonstrates the effectiveness of our proposed method, showing significant improvements in decision abilities for both unseen and known tasks.