Beyond Input Activations: Identifying Influential Latents by Gradient Sparse Autoencoders
作者: Dong Shu, Xuansheng Wu, Haiyan Zhao, Mengnan Du, Ninghao Liu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-12 (更新: 2025-09-23)
备注: EMNLP 2025 Main
💡 一句话要点
提出梯度稀疏自编码器(GradSAE),通过梯度信息识别大语言模型中具有影响力的隐变量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 大语言模型 可解释性 梯度分析 因果推断 模型引导 隐变量 表示学习
📋 核心要点
- 现有稀疏自编码器分析方法主要依赖输入侧激活,忽略了隐变量对模型输出的因果影响。
- GradSAE通过引入输出侧梯度信息,识别对模型输出具有高因果影响的关键隐变量。
- 实验验证了GradSAE能够有效识别有影响力的隐变量,并可用于更有效的模型引导。
📝 摘要(中文)
稀疏自编码器(SAEs)最近成为解释和引导大型语言模型(LLMs)内部表示的强大工具。然而,分析SAEs的传统方法通常只依赖于输入侧的激活,而没有考虑每个隐变量特征与模型输出之间的因果影响。本文基于两个关键假设:(1)激活的隐变量对模型输出的贡献并不相同;(2)只有具有高因果影响的隐变量才能有效地用于模型引导。为了验证这些假设,我们提出了一种简单而有效的方法,即梯度稀疏自编码器(GradSAE),它通过结合输出侧的梯度信息来识别最具影响力的隐变量。
🔬 方法详解
问题定义:现有方法在分析稀疏自编码器时,主要关注输入激活,忽略了不同隐变量对模型最终输出的贡献程度差异。激活的隐变量并不一定都对模型输出有重要影响,因此,简单地基于激活值来分析和引导模型可能效率低下,甚至引入噪声。
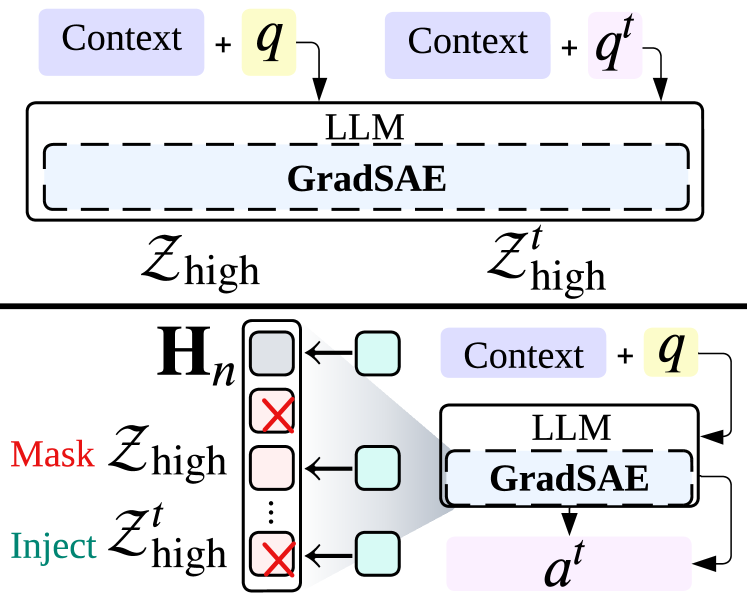
核心思路:论文的核心思路是,并非所有激活的隐变量都同等重要,只有那些对模型输出具有显著因果影响的隐变量才真正重要。因此,通过分析输出侧的梯度信息,可以识别出这些具有高影响力的隐变量,从而更有效地进行模型引导。
技术框架:GradSAE的整体框架是在传统稀疏自编码器的基础上,增加了一个梯度分析模块。首先,使用稀疏自编码器对LLM的内部表示进行编码,得到一组隐变量。然后,计算模型输出关于这些隐变量的梯度,利用梯度信息来评估每个隐变量对模型输出的影响力。最后,根据影响力大小对隐变量进行排序和筛选,选择最具影响力的隐变量用于后续分析和模型引导。
关键创新:GradSAE的关键创新在于将输出侧的梯度信息引入到稀疏自编码器的分析中。与传统方法只关注输入激活不同,GradSAE通过梯度来衡量隐变量对模型输出的实际影响,从而更准确地识别出重要的隐变量。这种方法能够有效区分激活但影响较小的隐变量和真正具有因果影响的隐变量。
关键设计:GradSAE的关键设计包括:(1) 如何有效地计算和利用输出侧的梯度信息;(2) 如何将梯度信息与稀疏自编码器的训练目标相结合,以鼓励模型学习到更具有因果影响的隐变量表示;(3) 如何选择合适的梯度度量方式,例如梯度范数或梯度方向,来评估隐变量的影响力。具体的损失函数设计和网络结构选择未知,需要参考论文细节。
🖼️ 关键图片


📊 实验亮点
论文提出的GradSAE方法能够有效识别对模型输出具有高因果影响的隐变量。具体实验结果未知,但可以推断,通过使用GradSAE选择的隐变量进行模型引导,可以获得比传统方法更好的性能提升,例如更高的生成质量、更强的可控性或更低的偏差。
🎯 应用场景
GradSAE可应用于大语言模型的解释性分析,帮助研究人员理解模型内部的工作机制。此外,它还可以用于模型引导,通过干预具有高影响力的隐变量来控制模型的行为。潜在的应用领域包括文本生成、对话系统、机器翻译等,可以提升模型的可控性和安全性。
📄 摘要(原文)
Sparse Autoencoders (SAEs) have recently emerged as powerful tools for interpreting and steering the internal representations of large language models (LLMs). However, conventional approaches to analyzing SAEs typically rely solely on input-side activations, without considering the causal influence between each latent feature and the model's output. This work is built on two key hypotheses: (1) activated latents do not contribute equally to the construction of the model's output, and (2) only latents with high causal influence are effective for model steering. To validate these hypotheses, we propose Gradient Sparse Autoencoder (GradSAE), a simple yet effective method that identifies the most influential latents by incorporating output-side gradient information.