Multimodal Cancer Modeling in the Age of Foundation Model Embeddings
作者: Steven Song, Morgan Borjigin-Wang, Irene Madejski, Robert L. Grossman
分类: cs.LG, cs.AI
发布日期: 2025-05-12 (更新: 2026-01-24)
备注: camera ready version for ML4H 2025, typo corrected
💡 一句话要点
提出基于Foundation Model嵌入的多模态癌症建模方法,提升癌症生存预测性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 癌症建模 Foundation Model 文本嵌入 生存预测
📋 核心要点
- 现有癌症生存预测方法依赖于针对TCGA数据集定制的深度学习模型,缺乏通用性和可迁移性。
- 论文提出利用Foundation Model提取多模态特征嵌入,并融合基因组、临床和病理报告文本信息,实现更有效的癌症建模。
- 实验结果表明,该方法能够有效融合多模态数据,并提升癌症生存预测的性能,同时验证了病理报告文本信息的价值。
📝 摘要(中文)
本研究利用癌症基因组图谱(TCGA)中整合的基因组学、临床和影像数据,探索基于Foundation Model (FM) 嵌入的多模态癌症建模方法。TCGA数据已推动了癌症研究的诸多发现,并作为大规模参考数据集。虽然TCGA包含病理报告等自由文本数据,但以往研究对其利用不足。本文研究了在癌症数据的多模态、零样本FM嵌入上训练经典机器学习模型的能力。结果表明,多模态融合简便有效,优于单模态模型。此外,研究还展示了包含病理报告文本的益处,并严格评估了基于模型的文本摘要和幻觉的影响。总而言之,我们提出了一种以嵌入为中心的多模态癌症建模方法。
🔬 方法详解
问题定义:现有癌症建模方法通常针对特定任务和数据集设计,泛化能力有限。TCGA数据集中包含大量的病理报告文本信息,但以往研究对其利用不足,未能充分挖掘其价值。因此,如何有效利用多模态数据,特别是病理报告文本,提升癌症建模的性能是一个关键问题。
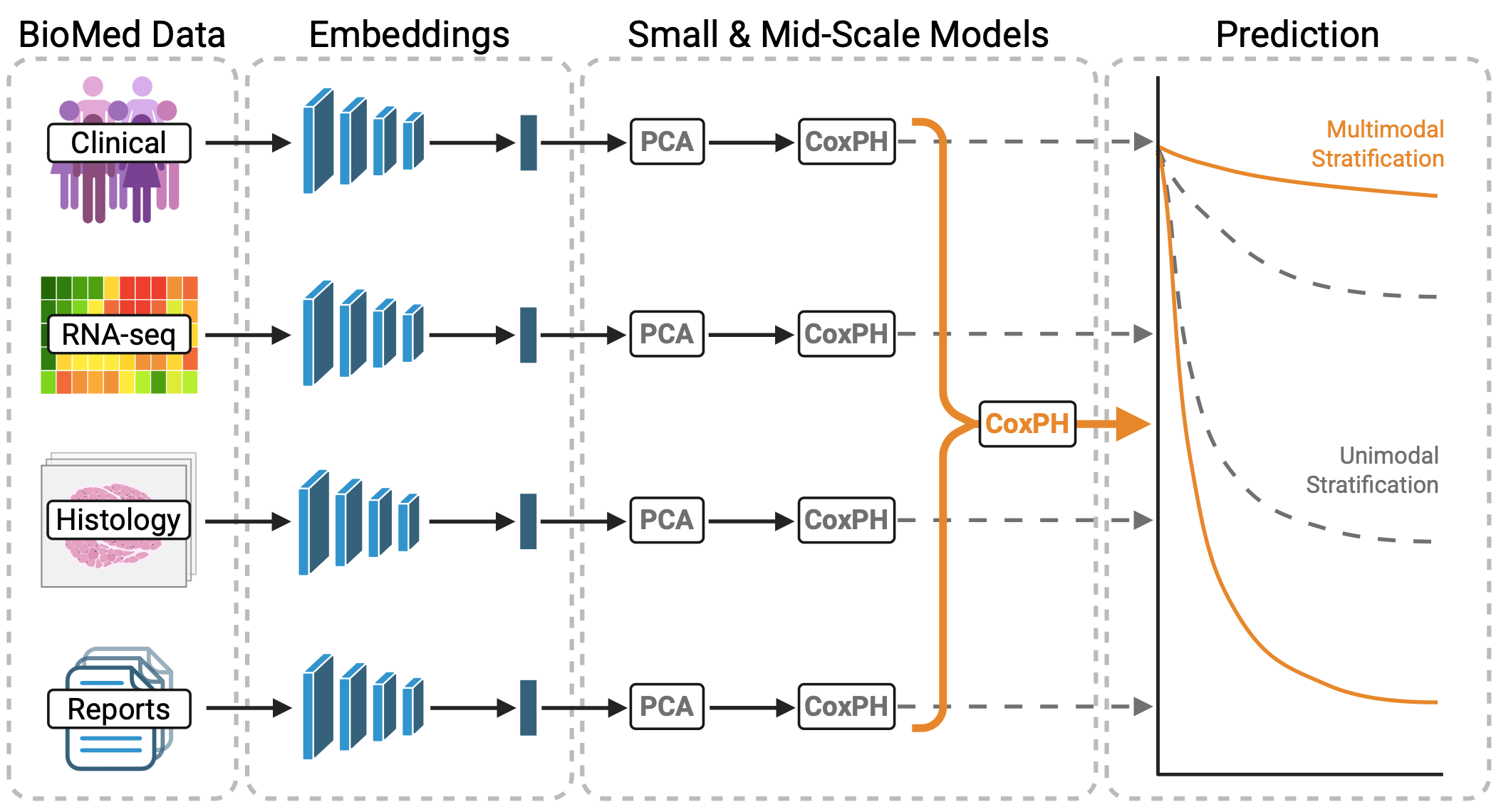
核心思路:论文的核心思路是利用Foundation Model (FM) 提取多模态数据的特征嵌入,将不同模态的数据映射到统一的向量空间,然后在此基础上训练经典的机器学习模型。这种方法可以充分利用FM的强大表征能力,同时避免了从头训练深度学习模型的复杂性。通过融合基因组、临床和病理报告文本信息,可以更全面地了解癌症的特征,从而提升建模的准确性。
技术框架:整体框架包括以下几个主要步骤:1) 利用Foundation Model (例如生物医学文本FM) 对基因组数据、临床数据和病理报告文本进行编码,生成相应的特征嵌入。2) 将不同模态的特征嵌入进行融合,例如通过拼接或加权平均等方式。3) 在融合后的特征嵌入上训练经典的机器学习模型,例如逻辑回归、支持向量机或随机森林等。4) 评估模型在癌症生存预测等任务上的性能。
关键创新:论文的关键创新在于提出了一种以嵌入为中心的多模态癌症建模方法。该方法利用Foundation Model的强大表征能力,将不同模态的数据映射到统一的向量空间,从而实现了多模态数据的有效融合。此外,论文还特别关注了病理报告文本信息的利用,并研究了文本摘要和幻觉对建模性能的影响。
关键设计:论文中涉及的关键设计包括:1) 选择合适的Foundation Model,例如针对生物医学文本的FM。2) 设计有效的多模态特征融合策略,例如拼接、加权平均或注意力机制等。3) 选择合适的机器学习模型,并进行参数调优。4) 针对病理报告文本,研究不同的文本摘要方法,并评估其对建模性能的影响。此外,还需要考虑如何处理FM可能产生的幻觉问题。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于Foundation Model嵌入的多模态模型优于单模态模型,证明了多模态融合的有效性。加入病理报告文本信息后,模型性能进一步提升,验证了文本信息的价值。研究还评估了文本摘要和幻觉对模型性能的影响,为实际应用提供了指导。
🎯 应用场景
该研究成果可应用于癌症诊断、预后预测和个性化治疗方案制定。通过整合基因组、临床和病理报告等多模态数据,可以更全面地了解癌症的特征,从而为临床决策提供更准确的依据。未来,该方法还可以扩展到其他疾病的建模和预测,具有广阔的应用前景。
📄 摘要(原文)
The Cancer Genome Atlas (TCGA) has enabled novel discoveries and served as a large-scale reference dataset in cancer through its harmonized genomics, clinical, and imaging data. Numerous prior studies have developed bespoke deep learning models over TCGA for tasks such as cancer survival prediction. A modern paradigm in biomedical deep learning is the development of foundation models (FMs) to derive feature embeddings agnostic to a specific modeling task. Biomedical text especially has seen growing development of FMs. While TCGA contains free-text data as pathology reports, these have been historically underutilized. Here, we investigate the ability to train classical machine learning models over multimodal, zero-shot FM embeddings of cancer data. We demonstrate the ease and additive effect of multimodal fusion, outperforming unimodal models. Further, we show the benefit of including pathology report text and rigorously evaluate the effect of model-based text summarization and hallucination. Overall, we propose an embedding-centric approach to multimodal cancer modeling.