SpecRouter: Adaptive Routing for Multi-Level Speculative Decoding in Large Language Models
作者: Hang Wu, Jianian Zhu, Yinghui Li, Haojie Wang, Biao Hou, Jidong Zhai
分类: cs.LG, cs.DC
发布日期: 2025-05-12
备注: 10 pages
💡 一句话要点
SpecRouter:面向大语言模型多级推测解码的自适应路由框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推测解码 自适应路由 模型链 KV缓存
📋 核心要点
- 现有大语言模型服务策略无法根据用户请求和系统性能动态调整模型规模,导致效率低下。
- SpecRouter通过构建自适应模型链,动态选择draft和verifier模型,优化推理路径,降低延迟。
- SpecRouter实现了多级协作验证和同步状态管理,提升了推测解码的效率和准确性。
📝 摘要(中文)
大型语言模型(LLMs)在推理质量和计算成本之间存在关键权衡:更大的模型提供卓越的性能,但会产生显著的延迟,而较小的模型速度更快,但能力较弱。现有的服务策略通常采用固定的模型规模或静态的两阶段推测解码,无法动态适应用户请求的不同复杂性或系统性能的波动。本文介绍了一种名为SpecRouter的新颖框架,它将LLM推理重新构想为一个通过多级推测解码解决的自适应路由问题。SpecRouter基于实时反馈动态构建和优化推理“路径”(模型链),从而解决了静态方法的局限性。我们的贡献有三方面:(1)一种自适应模型链调度机制,利用性能分析(执行时间)和预测相似性指标(源自token分布差异)来持续选择最佳的draft和verifier模型序列,从而最大限度地减少每个生成的token的预测延迟。(2)一种多级协作验证框架,其中所选链中的中间模型可以验证推测的token,从而减轻最终、最强大的目标模型的验证负担。(3)一个同步状态管理系统,可在链中的异构模型之间提供高效、一致的KV缓存处理,包括为多级推测中固有的异步批量处理量身定制的精确、低开销的回滚。初步实验证明了我们方法的有效性。
🔬 方法详解
问题定义:现有的大语言模型推理服务通常采用固定大小的模型或静态的两阶段推测解码。这种方法无法根据用户请求的复杂度和系统负载的变化进行动态调整,导致计算资源的浪费和推理延迟的增加。例如,对于简单的请求,使用大型模型进行推理是低效的,而对于复杂的请求,小型模型可能无法提供足够的准确性。
核心思路:SpecRouter的核心思想是将LLM推理视为一个自适应路由问题。它通过构建一个包含多个不同大小模型的链,并根据实时反馈动态选择最佳的推理路径。这种方法允许系统根据请求的复杂度和系统状态,灵活地选择合适的模型组合,从而在推理质量和计算成本之间取得平衡。
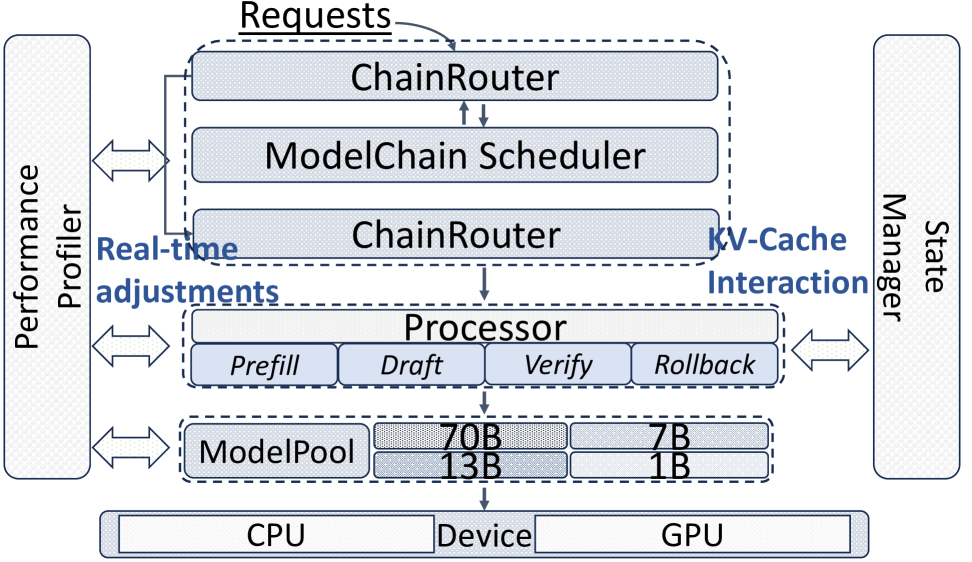
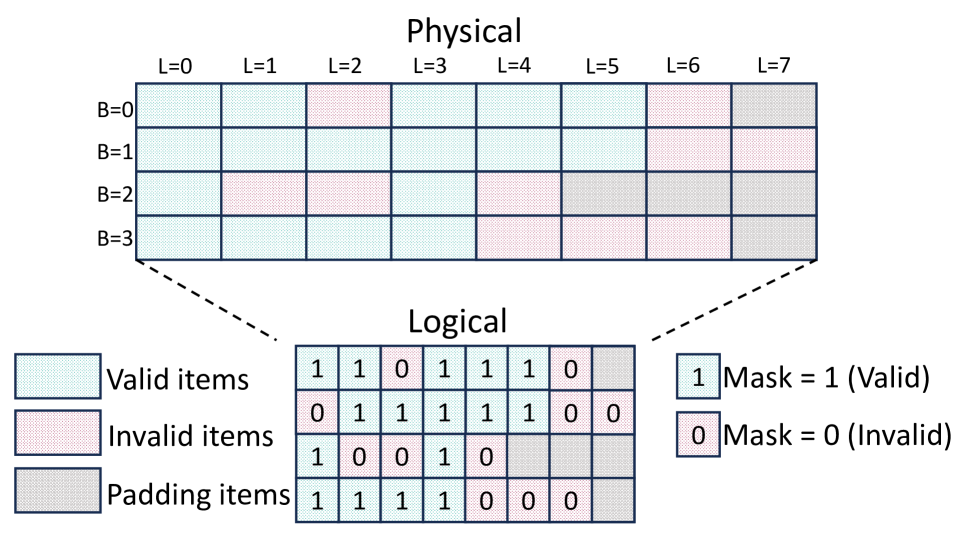
技术框架:SpecRouter包含三个主要模块:自适应模型链调度、多级协作验证和同步状态管理。自适应模型链调度模块负责根据性能分析和预测相似性指标,选择最佳的draft和verifier模型序列。多级协作验证模块允许中间模型验证推测的token,减轻最终模型的负担。同步状态管理模块负责在异构模型之间提供高效、一致的KV缓存处理,并支持精确的回滚。
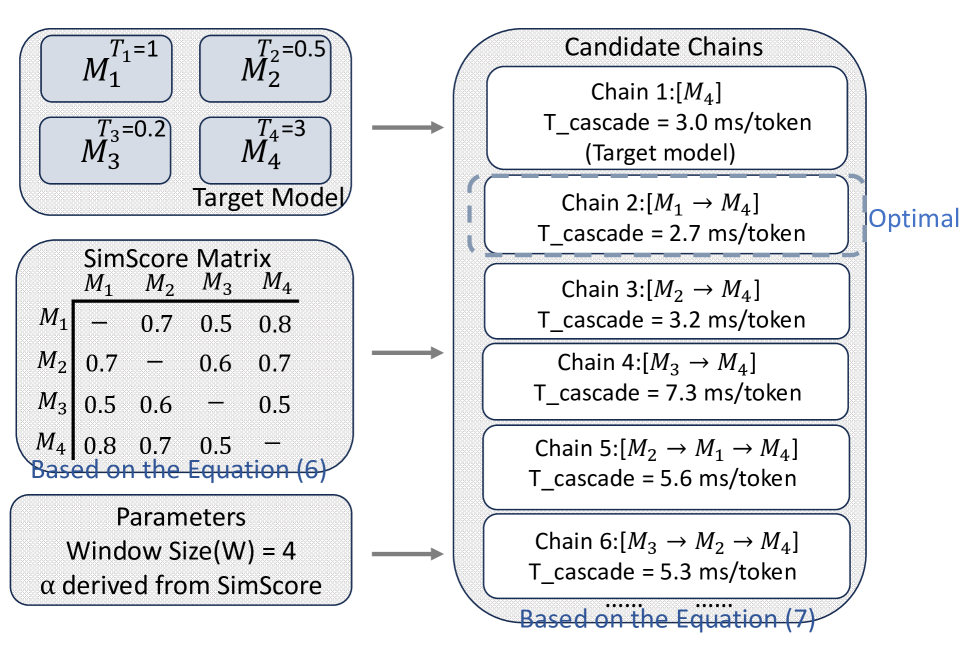
关键创新:SpecRouter的关键创新在于其自适应模型链调度机制和多级协作验证框架。传统的推测解码方法通常只使用一个draft模型和一个verifier模型,而SpecRouter允许多个模型参与验证过程,从而提高了验证的效率和准确性。此外,SpecRouter的自适应调度机制可以根据实时反馈动态调整模型链,从而更好地适应不同的请求和系统状态。
关键设计:SpecRouter使用token分布的散度作为预测相似性指标,用于评估draft模型和verifier模型之间的相似度。它还设计了一种低开销的回滚机制,用于在验证失败时快速恢复到之前的状态。此外,SpecRouter还考虑了异步批量处理,以提高推理的吞吐量。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了SpecRouter的有效性,但具体性能数据未知。摘要中提到“初步实验证明了我们方法的有效性”,表明该方法在一定程度上能够提升推理效率,但具体的加速比、延迟降低等指标需要在论文正文中查找。未来的研究可以进一步探索不同模型组合和调度策略对性能的影响。
🎯 应用场景
SpecRouter可应用于各种需要高性能、低延迟的大语言模型推理服务场景,例如智能客服、机器翻译、文本摘要、代码生成等。通过动态调整模型规模和推理路径,SpecRouter可以显著提高推理效率,降低计算成本,并提升用户体验。该研究成果对于推动大语言模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large Language Models (LLMs) present a critical trade-off between inference quality and computational cost: larger models offer superior capabilities but incur significant latency, while smaller models are faster but less powerful. Existing serving strategies often employ fixed model scales or static two-stage speculative decoding, failing to dynamically adapt to the varying complexities of user requests or fluctuations in system performance. This paper introduces \systemname{}, a novel framework that reimagines LLM inference as an adaptive routing problem solved through multi-level speculative decoding. \systemname{} dynamically constructs and optimizes inference "paths" (chains of models) based on real-time feedback, addressing the limitations of static approaches. Our contributions are threefold: (1) An \textbf{adaptive model chain scheduling} mechanism that leverages performance profiling (execution times) and predictive similarity metrics (derived from token distribution divergence) to continuously select the optimal sequence of draft and verifier models, minimizing predicted latency per generated token. (2) A \textbf{multi-level collaborative verification} framework where intermediate models within the selected chain can validate speculative tokens, reducing the verification burden on the final, most powerful target model. (3) A \textbf{synchronized state management} system providing efficient, consistent KV cache handling across heterogeneous models in the chain, including precise, low-overhead rollbacks tailored for asynchronous batch processing inherent in multi-level speculation. Preliminary experiments demonstrate the validity of our method.