Simple yet Effective Semi-supervised Knowledge Distillation from Vision-Language Models via Dual-Head Optimization
作者: Seongjae Kang, Dong Bok Lee, Hyungjoon Jang, Sung Ju Hwang
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-05-12 (更新: 2025-09-30)
备注: 38 pages, 17 figures, preprint
🔗 代码/项目: GITHUB
💡 一句话要点
提出双头优化(DHO),通过视觉-语言模型的知识蒸馏实现高效半监督学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 半监督学习 知识蒸馏 视觉-语言模型 双头优化 梯度冲突
📋 核心要点
- 现有知识蒸馏方法在半监督学习中,存在监督损失和蒸馏损失之间的梯度冲突问题。
- 提出双头优化(DHO)方法,为每个信号引入双预测头,从而有效解决梯度冲突。
- 实验结果表明,DHO在多个数据集上超越了现有知识蒸馏方法,并在ImageNet半监督学习上取得了新的SOTA。
📝 摘要(中文)
半监督学习(SSL)已成为利用无标签数据应对数据稀缺挑战的实用解决方案。最近,在大量图像-文本对上预训练的视觉-语言模型(VLM)表现出卓越的零/少样本性能,通常超越SSL方法,这归功于它们出色的泛化能力。这种差距促使我们思考:如何有效地将VLM强大的泛化能力应用到特定任务模型中?知识蒸馏(KD)为迁移VLM能力提供了一个自然的框架,但我们发现它受到监督损失和蒸馏损失之间梯度冲突的影响。为了解决这个挑战,我们提出了双头优化(DHO),它为每个不同的信号引入了双预测头。我们观察到DHO解决了梯度冲突,与单头KD基线相比,能够改进特征学习,并且具有计算开销最小和无需重新训练即可进行测试时超参数调整的实际优势。在15个数据集上的大量实验表明,DHO始终优于KD基线,通常优于具有较小学生模型的教师模型。DHO还在同分布ImageNet半监督学习和跨ImageNet变体的异分布泛化方面取得了新的最先进性能。我们公开发布了我们的代码和模型检查点,以促进未来的研究。
🔬 方法详解
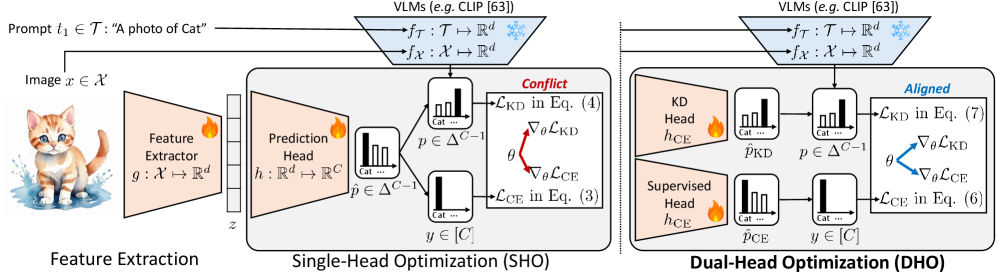
问题定义:论文旨在解决半监督学习中,如何有效利用视觉-语言模型(VLM)的强大泛化能力,并将其迁移到特定任务模型的问题。现有的知识蒸馏方法在半监督学习场景下,由于监督损失和蒸馏损失之间的梯度冲突,导致模型训练效率低下,性能提升受限。
核心思路:论文的核心思路是通过引入双头优化(DHO)机制,为每个训练信号(监督信号和蒸馏信号)分配独立的预测头。这样可以有效解耦不同损失函数产生的梯度,避免梯度冲突,从而提升特征学习的效率和效果。
技术框架:DHO方法的核心在于为学生模型配备两个预测头:一个用于处理有标签数据的监督学习,另一个用于从教师模型(VLM)进行知识蒸馏。训练过程中,有标签数据同时作用于两个头,无标签数据仅作用于蒸馏头。两个头分别计算损失,并独立更新模型参数。在推理阶段,可以选择使用监督头或蒸馏头,也可以对两个头的输出进行融合。
关键创新:DHO的关键创新在于双头结构的设计,它能够有效缓解半监督知识蒸馏中的梯度冲突问题。与传统的单头知识蒸馏方法相比,DHO能够更好地利用VLM的知识,并提升学生模型的性能。此外,DHO无需复杂的超参数调整,具有良好的通用性和易用性。
关键设计:DHO的关键设计包括:1) 双预测头的结构,通常是简单的线性层或MLP;2) 损失函数的设计,监督头使用交叉熵损失,蒸馏头可以使用KL散度损失或其他蒸馏损失函数;3) 两个头的输出融合方式,可以通过加权平均或更复杂的融合策略实现。论文中具体使用的损失函数和融合策略未知。
🖼️ 关键图片


📊 实验亮点
DHO方法在15个数据集上 consistently 优于 KD 基线,并且在 ImageNet 半监督学习和跨 ImageNet 变体的 out-of-distribution 泛化上取得了新的 SOTA 性能。实验结果表明,DHO 能够有效地将 VLM 的知识迁移到学生模型,并且在小模型上也能超越教师模型。
🎯 应用场景
该研究成果可广泛应用于图像分类、目标检测、图像分割等计算机视觉任务中,尤其是在数据标注成本高昂或难以获取大量标注数据的场景下。通过利用预训练的VLM和DHO方法,可以有效提升模型的性能和泛化能力,降低对标注数据的依赖,具有重要的实际应用价值。
📄 摘要(原文)
Semi-supervised learning (SSL) has emerged as a practical solution for addressing data scarcity challenges by leveraging unlabeled data. Recently, vision-language models (VLMs), pre-trained on massive image-text pairs, have demonstrated remarkable zero-/few-shot performance that often surpasses SSL approaches due to their exceptional generalization capabilities. This gap motivates us to question: how can we effectively harness the powerful generalization capabilities of VLMs into task-specific models? Knowledge distillation (KD) offers a natural framework for transferring VLM capabilities, but we identify that it suffers from gradient conflicts between supervised and distillation losses. To address this challenge, we propose Dual-Head Optimization (DHO), which introduces dual prediction heads for each distinct signal. We observe that DHO resolves gradient conflicts, enabling improved feature learning compared to single-head KD baselines, with practical benefits of minimal computational overhead and test-time hyperparameter tuning without retraining. Extensive experiments across 15 datasets show that DHO consistently outperforms KD baselines, often outperforming teacher models with smaller student models. DHO also achieves new state-of-the-art performance on both in-distribution ImageNet semi-supervised learning and out-of-distribution generalization across ImageNet variants. We publicly release our code and model checkpoints to facilitate future research at https://github.com/erjui/DHO.