TACOS: Temporally-aligned Audio CaptiOnS for Language-Audio Pretraining
作者: Paul Primus, Florian Schmid, Gerhard Widmer
分类: eess.AS, cs.LG, cs.SD
发布日期: 2025-05-12
备注: submitted to the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2025. Dataset (Zenodo): https://zenodo.org/records/15379789, Implementation (GitHub): https://github.com/OptimusPrimus/tacos
💡 一句话要点
TACOS:用于语言-音频预训练的时序对齐音频字幕数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言-音频预训练 时序对齐 音频字幕 对比学习 数据集构建 音频事件定位
📋 核心要点
- 现有的语言-音频预训练模型缺乏精确的时序对齐,限制了其在细粒度音频理解任务中的表现。
- TACOS数据集通过提供与音频片段精确对齐的文本描述,为语言-音频模型提供更强的时序监督信号。
- 提出的帧级对比学习方法,能够有效利用TACOS数据集,提升模型在时序文本-音频对齐方面的能力,并在AudioSet Strong基准上取得提升。
📝 摘要(中文)
将音频与文本描述相关联对于各种任务至关重要,包括预训练、零样本分类、音频检索、音频字幕和文本条件音频生成。现有的对比语言-音频预训练模型通常使用全局的、片段级别的描述进行训练,这仅提供较弱的时序监督。我们假设,类似CLAP的语言-音频模型——特别是当它们需要生成帧级别嵌入时——可以从更强的时序监督中受益。为了验证我们的假设,我们整理了一个新的数据集,其中包含来自Freesound的约12,000个音频记录,每个记录都带有与音频记录中的特定时间段相关的单句自由文本描述。我们使用大型语言模型来清理这些注释,方法是删除对非听觉事件、转录语音、拼写错误和注释者语言偏差的引用。我们进一步提出了一种帧级对比训练策略,该策略学习将文本描述与音频记录中的时间区域对齐,并证明我们的模型在AudioSet Strong基准测试中,与仅在全局字幕上训练的模型相比,具有更好的时序文本-音频对齐能力。数据集和我们的源代码分别可在Zenodo和GitHub上找到。
🔬 方法详解
问题定义:现有语言-音频预训练模型主要依赖于全局的、片段级别的描述,缺乏对音频内容时序信息的精确建模。这导致模型难以捕捉音频事件发生的具体时间点,限制了其在需要精细时序理解的任务中的应用,例如音频事件定位。
核心思路:论文的核心思路是利用与音频片段精确对齐的文本描述,为语言-音频模型提供更强的时序监督信号。通过这种方式,模型可以学习到文本描述与音频事件在时间上的对应关系,从而提升其时序对齐能力。
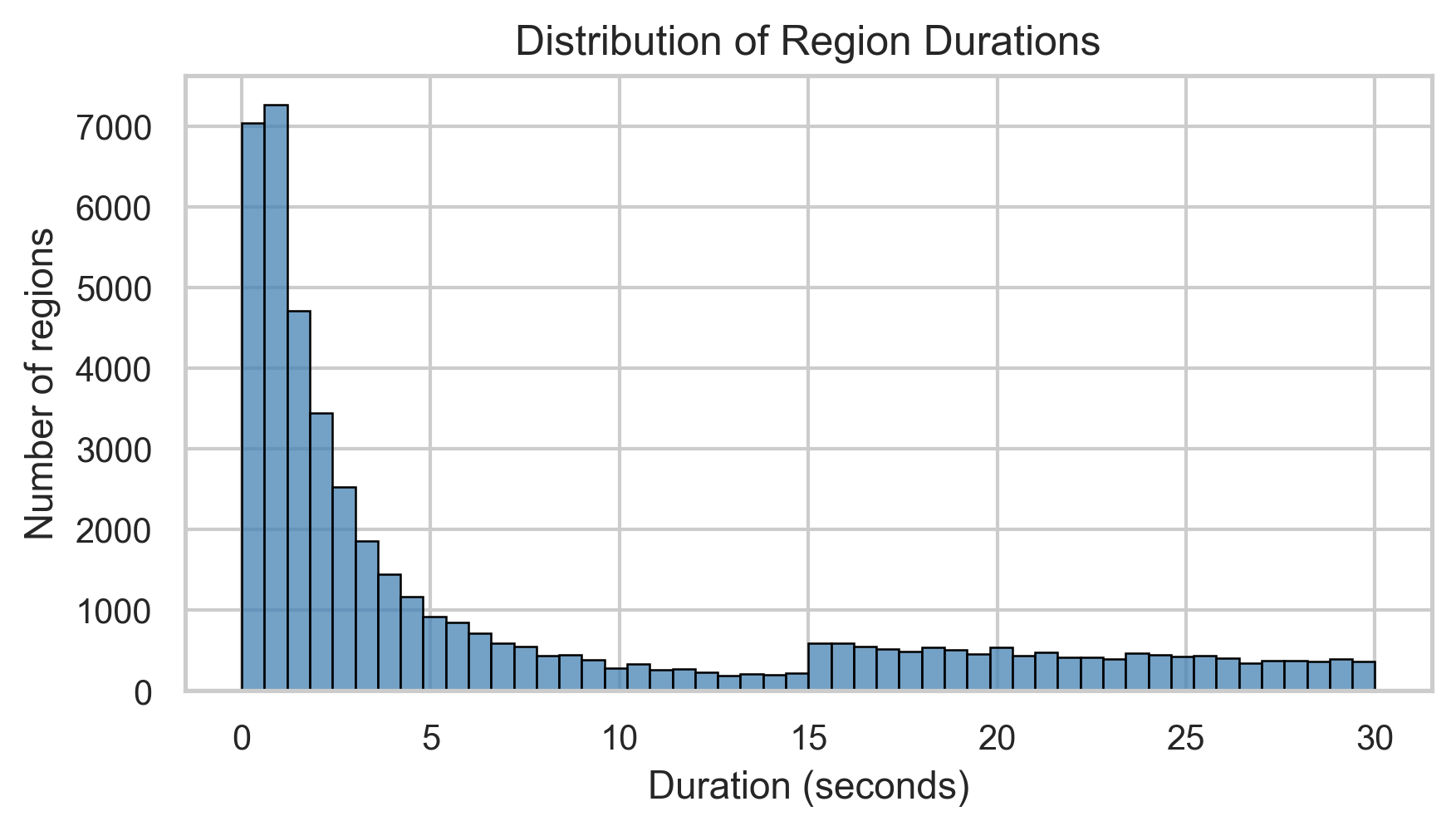
技术框架:该方法主要包含两个关键部分:一是TACOS数据集的构建,二是基于TACOS数据集的帧级对比学习训练策略。TACOS数据集包含约12,000个音频记录,每个记录都带有与特定时间段相关的文本描述。帧级对比学习策略旨在学习将文本描述与音频记录中的时间区域对齐。
关键创新:该方法的关键创新在于构建了TACOS数据集,并提出了相应的帧级对比学习训练策略。TACOS数据集提供了精确的时序对齐信息,这在之前的语言-音频预训练数据集中是缺失的。帧级对比学习策略能够有效利用这些时序信息,提升模型的时序对齐能力。
关键设计:TACOS数据集的构建过程中,使用了大型语言模型来清理和优化文本描述,以去除噪声和偏差。帧级对比学习策略使用了对比损失函数,鼓励模型将与同一音频片段相关的文本描述和音频嵌入拉近,同时将不相关的文本描述和音频嵌入推远。具体的损失函数形式和训练细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在TACOS数据集上训练的模型在AudioSet Strong基准测试中,与仅在全局字幕上训练的模型相比,具有更好的时序文本-音频对齐能力。这验证了TACOS数据集和帧级对比学习策略的有效性,为语言-音频预训练提供了新的思路。
🎯 应用场景
该研究成果可应用于音频事件定位、音频字幕生成、基于文本的音频检索等领域。通过提升语言-音频模型的时序对齐能力,可以实现更精确的音频内容理解和更智能的音频处理应用,例如智能安防、智能家居和辅助听觉设备。
📄 摘要(原文)
Learning to associate audio with textual descriptions is valuable for a range of tasks, including pretraining, zero-shot classification, audio retrieval, audio captioning, and text-conditioned audio generation. Existing contrastive language-audio pretrained models are typically trained using global, clip-level descriptions, which provide only weak temporal supervision. We hypothesize that CLAP-like language-audio models - particularly, if they are expected to produce frame-level embeddings - can benefit from a stronger temporal supervision. To confirm our hypothesis, we curate a novel dataset of approximately 12,000 audio recordings from Freesound, each annotated with single-sentence free-text descriptions linked to a specific temporal segment in an audio recording. We use large language models to clean these annotations by removing references to non-audible events, transcribed speech, typos, and annotator language bias. We further propose a frame-wise contrastive training strategy that learns to align text descriptions with temporal regions in an audio recording and demonstrate that our model has better temporal text-audio alignment abilities compared to models trained only on global captions when evaluated on the AudioSet Strong benchmark. The dataset and our source code are available on Zenodo and GitHub, respectively.