Scaling Laws and Representation Learning in Simple Hierarchical Languages: Transformers vs. Convolutional Architectures
作者: Francesco Cagnetta, Alessandro Favero, Antonio Sclocchi, Matthieu Wyart
分类: cs.LG, cond-mat.dis-nn, stat.ML
发布日期: 2025-05-11
备注: 14 pages, 8 figures
💡 一句话要点
研究揭示:卷积网络在学习分层语言结构时比Transformer具有更快的性能扩展。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 层次结构学习 神经语言模型 卷积网络 Transformer 扩展规律 表征学习 模型架构偏差 随机层次模型
📋 核心要点
- 现有神经语言模型在学习语言结构时面临挑战,尤其是在理解和捕捉语言的层次性方面。
- 论文提出基于数据相关性的表征学习理论,并扩展到考虑模型架构差异,分析模型如何学习层次结构。
- 研究表明,卷积网络由于其局部性和权重共享特性,在学习分层语言结构时比Transformer模型表现出更快的性能扩展。
📝 摘要(中文)
本文探讨了神经语言模型在训练进行下一词预测时如何获取语言结构。通过推导随机层次模型(RHM)——一种概率上下文无关文法的集合,旨在捕捉自然语言的层次结构并保持分析上的易处理性——生成的合成数据集上,神经网络性能的理论扩展规律,来解决这个问题。先前,我们开发了一种基于数据相关性的表征学习理论,解释了深度学习模型如何逐层地顺序捕获数据的层次结构。在这里,我们扩展了我们的理论框架以解释架构差异。特别是,我们预测并经验性地验证了卷积网络,其结构通过局部性和权重共享与生成过程对齐,与依赖于全局自注意力机制的Transformer模型相比,具有更快的性能扩展。这一发现阐明了神经扩展规律的底层架构偏差,并强调了表征学习如何受到模型架构与数据统计特性之间相互作用的影响。
🔬 方法详解
问题定义:论文旨在研究神经语言模型如何学习语言的层次结构,并分析不同架构(特别是卷积网络和Transformer)在学习这种结构时的性能差异。现有方法,特别是Transformer,虽然在许多NLP任务中表现出色,但在学习具有明确层次结构的语言时,其效率和扩展性可能不如专门设计的架构。
核心思路:论文的核心思路是,模型架构与数据生成过程的匹配程度会影响模型的学习效率和扩展性。卷积网络的局部性和权重共享特性使其更适合学习局部相关的层次结构,而Transformer的全局自注意力机制可能在学习这种结构时效率较低。
技术框架:论文使用随机层次模型(RHM)生成合成数据集,该模型是一种概率上下文无关文法的集合,用于模拟自然语言的层次结构。然后,在这些数据集上训练卷积网络和Transformer模型,并分析它们的性能扩展规律。理论分析基于数据相关性的表征学习理论,该理论预测了不同架构在学习层次结构时的性能。
关键创新:论文的关键创新在于,它将表征学习理论扩展到考虑模型架构的差异,并证明了卷积网络在学习分层语言结构时具有优于Transformer的性能扩展。这揭示了模型架构偏差在神经扩展规律中的作用,并强调了模型架构与数据统计特性之间相互作用的重要性。
关键设计:论文的关键设计包括:1) 使用RHM生成具有明确层次结构的合成数据集;2) 选择卷积网络和Transformer作为代表性的局部和全局架构;3) 基于数据相关性的表征学习理论,推导不同架构的性能扩展规律;4) 通过实验验证理论预测,并分析不同架构的学习行为。
🖼️ 关键图片

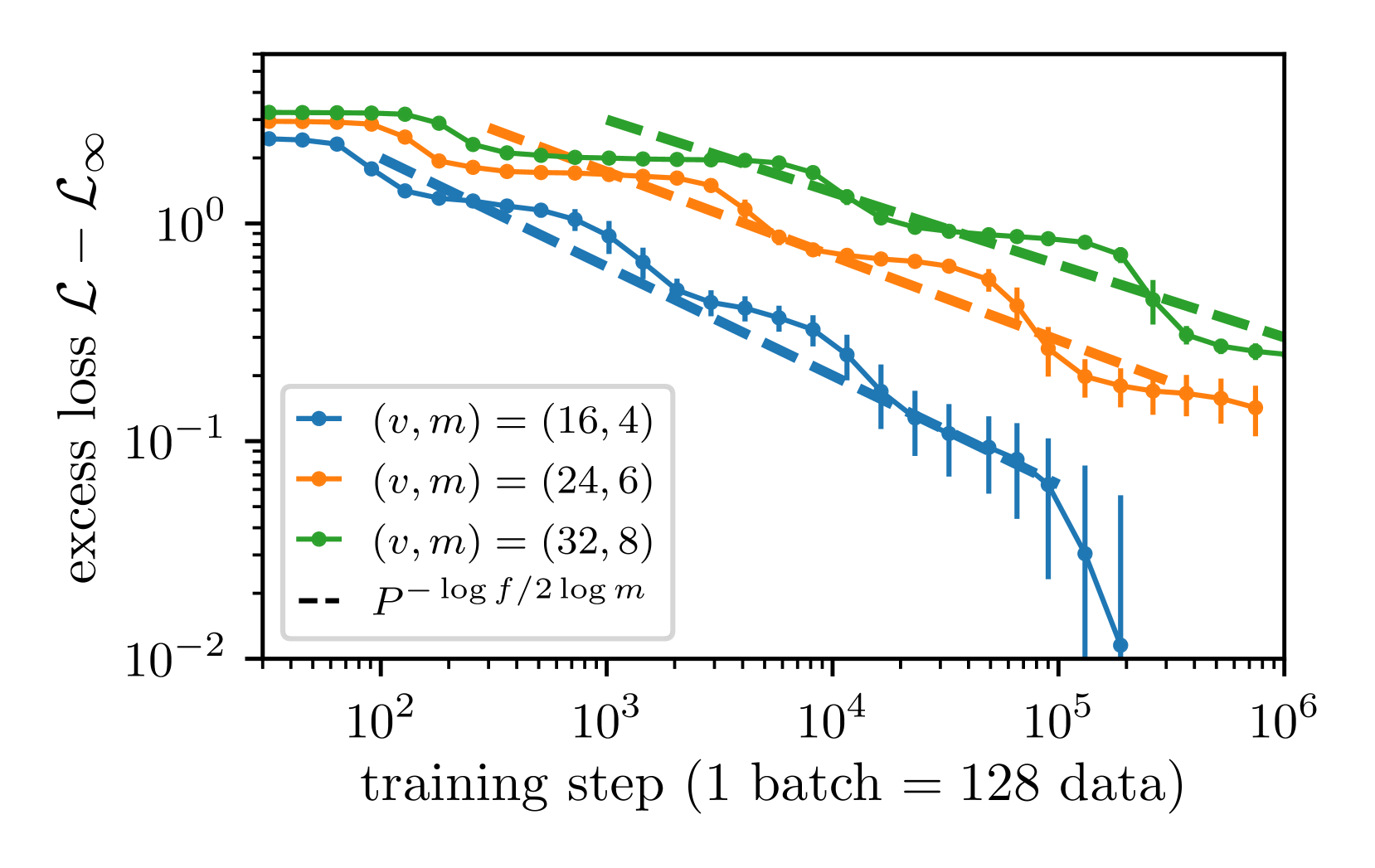
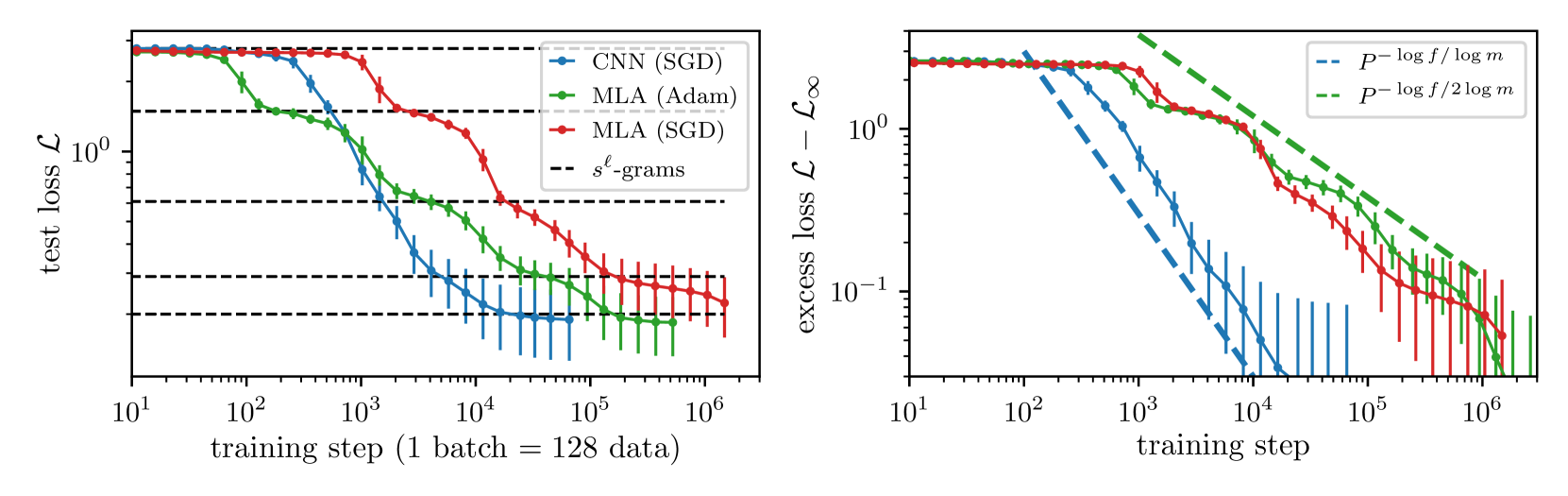
📊 实验亮点
实验结果表明,在学习由随机层次模型生成的合成数据集时,卷积网络比Transformer模型具有更快的性能扩展。具体来说,卷积网络在达到相同的性能水平时,需要的数据量明显少于Transformer。这验证了论文的理论预测,并强调了模型架构与数据统计特性匹配的重要性。
🎯 应用场景
该研究成果可应用于设计更高效的神经语言模型,尤其是在处理具有明确层次结构的语言或任务时。例如,在机器翻译、代码生成等领域,可以借鉴卷积网络的局部性优势,设计更适合学习层次结构的混合架构。此外,该研究也为理解深度学习模型的表征学习过程提供了新的视角。
📄 摘要(原文)
How do neural language models acquire a language's structure when trained for next-token prediction? We address this question by deriving theoretical scaling laws for neural network performance on synthetic datasets generated by the Random Hierarchy Model (RHM) -- an ensemble of probabilistic context-free grammars designed to capture the hierarchical structure of natural language while remaining analytically tractable. Previously, we developed a theory of representation learning based on data correlations that explains how deep learning models capture the hierarchical structure of the data sequentially, one layer at a time. Here, we extend our theoretical framework to account for architectural differences. In particular, we predict and empirically validate that convolutional networks, whose structure aligns with that of the generative process through locality and weight sharing, enjoy a faster scaling of performance compared to transformer models, which rely on global self-attention mechanisms. This finding clarifies the architectural biases underlying neural scaling laws and highlights how representation learning is shaped by the interaction between model architecture and the statistical properties of data.