When Bad Data Leads to Good Models
作者: Kenneth Li, Yida Chen, Fernanda Viégas, Martin Wattenberg
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-07
备注: ICML 2025
💡 一句话要点
通过预训练阶段引入不良数据,提升后训练阶段大语言模型的可控性与安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练 数据质量 毒性控制 后训练 安全对齐 推理时干预
📋 核心要点
- 现有观点认为高质量数据对LLM至关重要,但缺乏对预训练数据质量与后训练可控性之间关系的深入研究。
- 该研究探索了在预训练阶段引入一定比例的有害数据,以改善模型在后训练阶段的毒性控制能力。
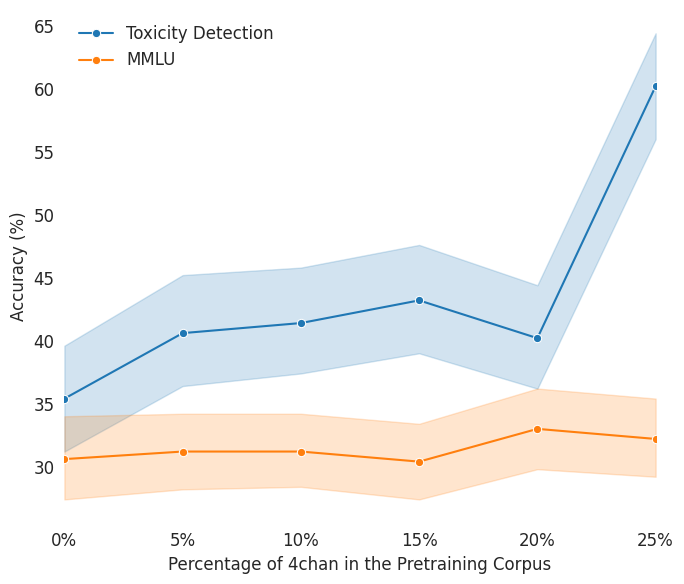
- 实验结果表明,使用包含有害数据训练的模型,在降低生成毒性和保持模型通用能力之间取得了更好的平衡。
📝 摘要(中文)
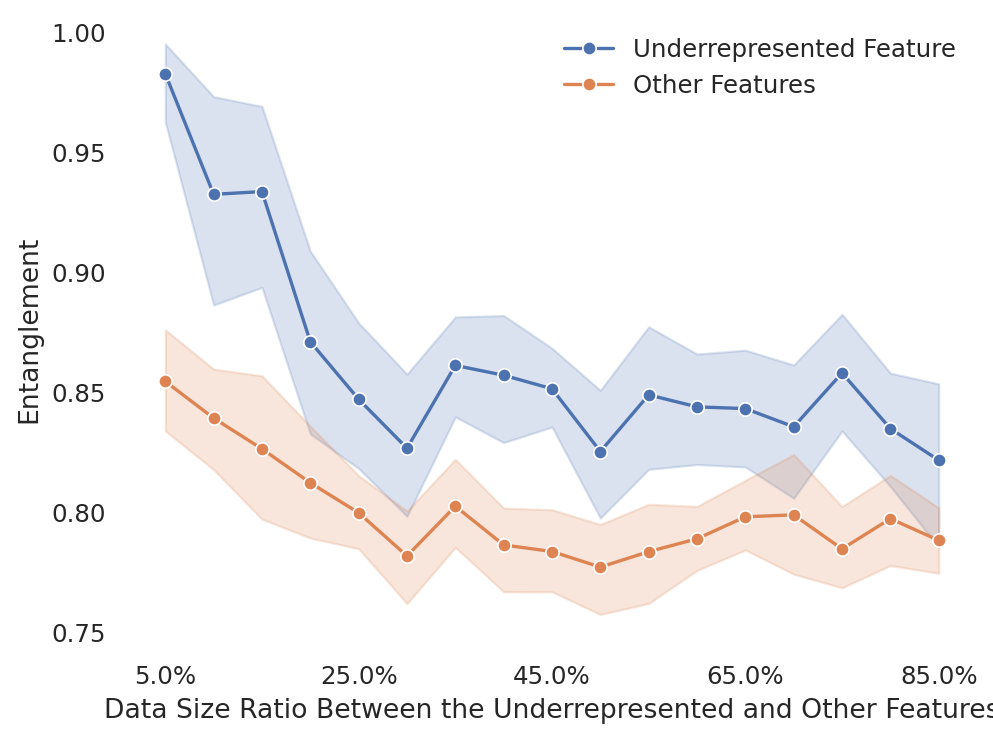
在大语言模型(LLM)预训练中,数据质量通常被认为是决定模型质量的关键因素。本文重新审视了“质量”的概念,从预训练和后训练协同设计的角度出发,探索了在预训练阶段使用更多有害数据是否能在后训练阶段实现更好的控制,最终降低模型的输出毒性。首先,通过一个玩具实验研究了数据组成如何影响表征空间中特征的几何结构。然后,通过对使用不同比例的干净和有害数据训练的 Olmo-1B 模型进行受控实验,发现随着有害数据比例的增加,毒性概念的线性表示变得不那么纠缠。此外,研究表明,虽然有害数据会增加基础模型的生成毒性,但同时也使得毒性更容易被移除。在 Toxigen 和 Real Toxicity Prompts 上的评估表明,当应用诸如推理时干预(ITI)等解毒技术时,使用有害数据训练的模型在降低生成毒性和保持通用能力之间取得了更好的平衡。研究结果表明,考虑到后训练,不良数据可能会产生良好的模型。
🔬 方法详解
问题定义:现有大语言模型预训练通常依赖于高质量的数据集,以避免模型生成有害或不当内容。然而,这种策略忽略了预训练数据组成对模型后训练阶段可控性的影响。现有方法难以在降低模型毒性的同时,保持其通用能力,存在trade-off问题。
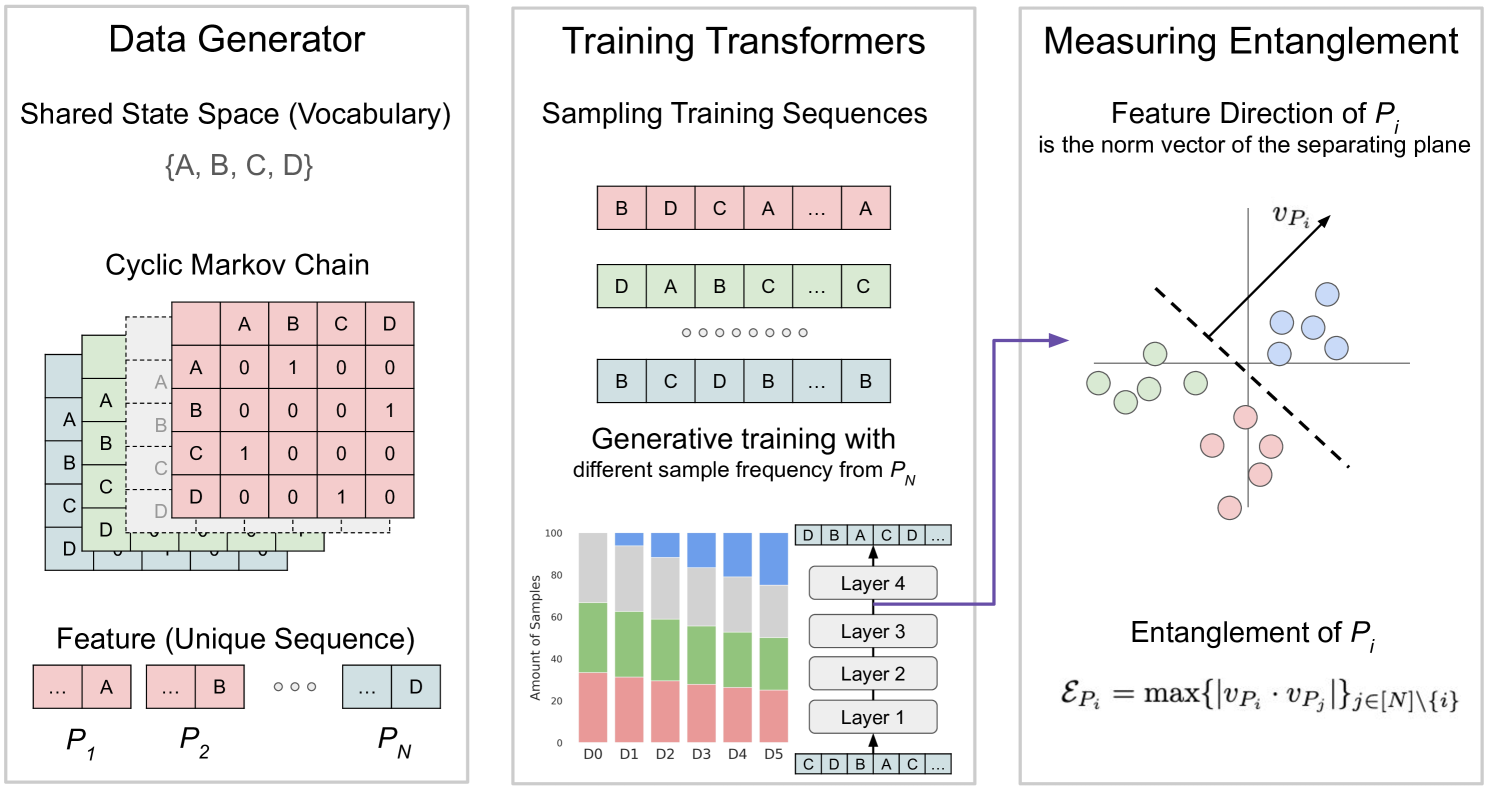
核心思路:该论文的核心思路是,通过在预训练阶段引入一定比例的“不良”数据(即包含毒性内容的数据),可以改变模型表征空间中与毒性相关的特征分布,使其更容易在后训练阶段被识别和移除。这种方法旨在打破“高质量数据=高质量模型”的传统观念,探索一种新的预训练-后训练协同设计范式。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 玩具实验:使用简单的模型和数据集,研究不同数据组成对特征空间几何结构的影响。2) 受控实验:使用 Olmo-1B 模型,在不同比例的干净和有害数据上进行预训练。3) 毒性评估:使用 Toxigen 和 Real Toxicity Prompts 等数据集,评估模型的生成毒性。4) 解毒技术应用:应用推理时干预(ITI)等解毒技术,降低模型的毒性。5) 性能评估:评估模型在降低毒性的同时,保持通用能力的程度。
关键创新:该论文的关键创新在于,提出了“不良数据可能导致良好模型”的观点,挑战了传统的数据质量观念。通过实验证明,在预训练阶段引入一定比例的有害数据,可以改善模型在后训练阶段的毒性控制能力,实现更好的安全性和可用性平衡。
关键设计:论文的关键设计包括:1) 数据比例控制:在预训练阶段,精确控制干净数据和有害数据的比例,以研究其对模型表征和性能的影响。2) 毒性评估指标:使用多种毒性评估指标,全面评估模型的生成毒性。3) 解毒技术选择:选择推理时干预(ITI)等有效的解毒技术,降低模型的毒性。4) 通用能力评估:在降低毒性的同时,评估模型在其他任务上的性能,以确保其通用能力不受影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用包含有害数据训练的 Olmo-1B 模型,在 Toxigen 和 Real Toxicity Prompts 数据集上,通过应用推理时干预(ITI)等解毒技术,能够在降低生成毒性的同时,更好地保持模型的通用能力,实现了更好的性能trade-off。
🎯 应用场景
该研究成果可应用于大语言模型的安全对齐和内容审核领域。通过合理利用“不良”数据,可以提升模型的可控性和安全性,降低生成有害内容的风险。此外,该研究也为其他机器学习模型的安全性和鲁棒性研究提供了新的思路。
📄 摘要(原文)
In large language model (LLM) pretraining, data quality is believed to determine model quality. In this paper, we re-examine the notion of "quality" from the perspective of pre- and post-training co-design. Specifically, we explore the possibility that pre-training on more toxic data can lead to better control in post-training, ultimately decreasing a model's output toxicity. First, we use a toy experiment to study how data composition affects the geometry of features in the representation space. Next, through controlled experiments with Olmo-1B models trained on varying ratios of clean and toxic data, we find that the concept of toxicity enjoys a less entangled linear representation as the proportion of toxic data increases. Furthermore, we show that although toxic data increases the generational toxicity of the base model, it also makes the toxicity easier to remove. Evaluations on Toxigen and Real Toxicity Prompts demonstrate that models trained on toxic data achieve a better trade-off between reducing generational toxicity and preserving general capabilities when detoxifying techniques such as inference-time intervention (ITI) are applied. Our findings suggest that, with post-training taken into account, bad data may lead to good models.