Trajectory Entropy Reinforcement Learning for Predictable and Robust Control
作者: Bang You, Chenxu Wang, Huaping Liu
分类: cs.LG, cs.RO, stat.ML
发布日期: 2025-05-07
备注: 10 pages
💡 一句话要点
提出轨迹熵强化学习,提升控制策略的预测性与鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 轨迹熵 鲁棒控制 归纳偏置 变分自编码器
📋 核心要点
- 深度强化学习易受环境扰动影响,原因是其倾向于学习状态与动作间虚假关联。
- 通过最小化动作轨迹的熵,鼓励策略生成更简洁、更可预测的动作序列。
- 实验表明,该方法在运动控制任务中表现出更强的鲁棒性和更高的性能。
📝 摘要(中文)
本文提出了一种新的强化学习方法,旨在引入策略的简洁性归纳偏置,从而提高控制器的鲁棒性。深度强化学习在复杂控制任务中表现出色,但容易捕捉观察和动作之间复杂且虚假的相关性,导致在环境发生轻微扰动时失效。为了解决这个问题,我们引入轨迹熵最小化,对应于在智能体观察状态轨迹后描述动作轨迹信息所需的比特数。我们的强化学习智能体,即轨迹熵强化学习,通过最小化轨迹熵并最大化奖励进行优化。我们证明了可以通过学习变分参数化动作预测模型来有效估计轨迹熵,并使用该预测模型构建信息正则化的奖励函数。此外,我们构建了一个实用的算法,可以联合优化包括策略和预测模型在内的模型。在多个高维运动任务上的实验评估表明,与最先进的方法相比,我们学习到的策略产生更具周期性和一致性的动作轨迹,并实现了卓越的性能以及对噪声和动态变化的鲁棒性。
🔬 方法详解
问题定义:深度强化学习在复杂控制任务中取得了显著成果,但其学习到的策略往往过于复杂,容易受到环境噪声和动态变化的影响。现有的强化学习方法缺乏对策略简洁性的有效约束,导致智能体学习到对环境过度敏感的策略,泛化能力较差。因此,如何提高强化学习策略的鲁棒性和泛化能力是一个重要的研究问题。
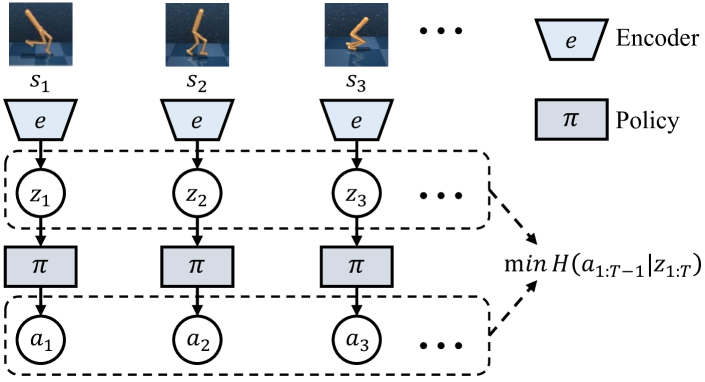
核心思路:本文的核心思路是通过引入轨迹熵的概念,鼓励智能体学习更简洁、更可预测的动作序列。轨迹熵衡量了描述整个动作轨迹所需的信息量,最小化轨迹熵可以促使智能体学习更具规律性和一致性的动作模式,从而提高策略的鲁棒性。这种方法相当于在强化学习中引入了一种简洁性归纳偏置,引导智能体学习更简单的策略。
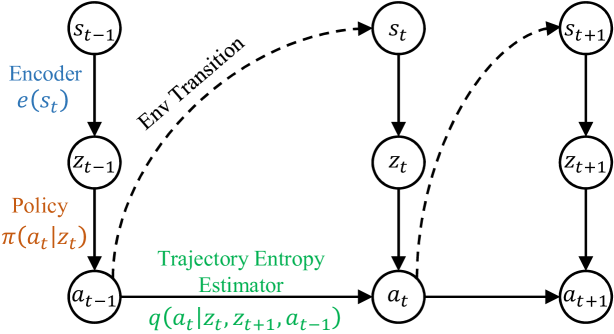
技术框架:该方法的核心技术框架包括以下几个主要模块:1) 策略网络:用于生成动作;2) 变分动作预测模型:用于估计动作轨迹的熵;3) 信息正则化奖励函数:将轨迹熵作为正则项加入到奖励函数中,引导智能体学习低熵的策略。整体流程是:智能体根据策略网络生成动作,与环境交互得到状态转移和奖励;变分动作预测模型根据状态轨迹预测动作轨迹,并计算轨迹熵;信息正则化奖励函数将原始奖励和轨迹熵结合,作为最终的奖励信号;策略网络根据最终的奖励信号进行优化。
关键创新:该方法最重要的技术创新点在于将轨迹熵的概念引入到强化学习中,并将其作为一种正则化手段来约束策略的学习。与传统的策略熵正则化方法不同,轨迹熵考虑的是整个动作轨迹的信息量,能够更有效地引导智能体学习全局一致的策略。此外,使用变分动作预测模型来估计轨迹熵也是一个重要的创新点,该方法能够有效地处理高维连续动作空间的情况。
关键设计:变分动作预测模型通常采用变分自编码器(VAE)的结构,包括一个编码器和一个解码器。编码器将状态轨迹作为输入,输出动作轨迹的潜在表示;解码器将潜在表示作为输入,重构动作轨迹。通过最小化重构误差和潜在表示的KL散度,可以训练得到一个能够有效估计轨迹熵的变分动作预测模型。信息正则化奖励函数通常采用如下形式:R' = R - λ * H(π(s)),其中R是原始奖励,H(π(s))是轨迹熵,λ是正则化系数,用于控制轨迹熵的权重。
🖼️ 关键图片

📊 实验亮点
在多个高维运动控制任务中,该方法与现有最优方法相比,在性能和鲁棒性方面均有显著提升。例如,在Humanoid任务中,该方法能够学习到更稳定的行走步态,对外部扰动的抵抗能力更强。实验结果表明,该方法能够有效地降低动作轨迹的熵,提高策略的预测性和鲁棒性。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过学习更鲁棒和可预测的控制策略,可以提高机器人在复杂和不确定环境中的适应能力,降低故障率,提升用户体验。未来,该方法有望应用于更广泛的控制任务,例如无人机编队、智能制造等。
📄 摘要(原文)
Simplicity is a critical inductive bias for designing data-driven controllers, especially when robustness is important. Despite the impressive results of deep reinforcement learning in complex control tasks, it is prone to capturing intricate and spurious correlations between observations and actions, leading to failure under slight perturbations to the environment. To tackle this problem, in this work we introduce a novel inductive bias towards simple policies in reinforcement learning. The simplicity inductive bias is introduced by minimizing the entropy of entire action trajectories, corresponding to the number of bits required to describe information in action trajectories after the agent observes state trajectories. Our reinforcement learning agent, Trajectory Entropy Reinforcement Learning, is optimized to minimize the trajectory entropy while maximizing rewards. We show that the trajectory entropy can be effectively estimated by learning a variational parameterized action prediction model, and use the prediction model to construct an information-regularized reward function. Furthermore, we construct a practical algorithm that enables the joint optimization of models, including the policy and the prediction model. Experimental evaluations on several high-dimensional locomotion tasks show that our learned policies produce more cyclical and consistent action trajectories, and achieve superior performance, and robustness to noise and dynamic changes than the state-of-the-art.