Absolute Zero: Reinforced Self-play Reasoning with Zero Data
作者: Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-06 (更新: 2025-10-16)
💡 一句话要点
提出Absolute Zero:一种无需外部数据的自博弈强化学习推理方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 自博弈 零样本学习 代码推理 数学推理 可验证奖励 自主学习
📋 核心要点
- 现有RLVR方法依赖人工标注数据,限制了模型在超越人类智能后的学习潜力,以及长期可扩展性。
- Absolute Zero范式通过让模型自我生成任务并验证答案,实现无需外部数据的自监督学习,提升推理能力。
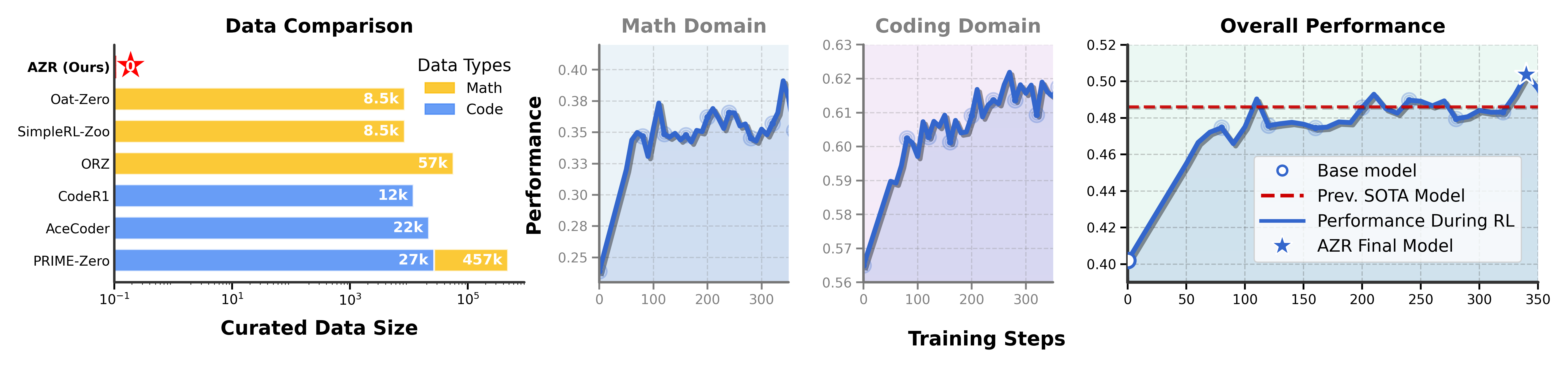
- 实验表明,AZR在编码和数学推理任务上超越了依赖大量人工标注数据的零样本模型,且适用于不同模型规模。
📝 摘要(中文)
本文提出了一种名为Absolute Zero的强化学习范式,用于提升大型语言模型的推理能力。该范式基于可验证奖励的强化学习(RLVR),无需任何外部数据,模型通过自我博弈,提出能够最大化自身学习进度的任务,并通过解决这些任务来提高推理能力。Absolute Zero Reasoner (AZR) 是该范式的具体实现,它使用代码执行器来验证提出的代码推理任务和答案,从而提供统一的可验证奖励来源,引导开放式但有根据的学习。实验表明,AZR在编码和数学推理任务上取得了SOTA性能,优于依赖于数万个领域内人工标注样本的现有零样本模型。此外,AZR可以有效地应用于不同的模型规模,并与各种模型类别兼容。
🔬 方法详解
问题定义:现有基于可验证奖励的强化学习(RLVR)方法,虽然避免了推理过程的监督,但仍然依赖于人工标注的问题和答案集合进行训练。这种依赖性限制了模型的长期可扩展性,尤其是在AI超越人类智能的未来,人类提供的任务可能无法充分发挥超智能系统的学习潜力。因此,需要一种无需任何外部数据的学习范式,使模型能够自主学习并提升推理能力。
核心思路:Absolute Zero的核心思路是让模型通过自我博弈来学习。模型既是任务的提出者,又是任务的解决者。通过设计一种机制,使得模型能够提出能够最大化自身学习进度的任务,并通过解决这些任务来提高推理能力。这种自监督的方式避免了对外部数据的依赖,使得模型能够自主地探索和学习。
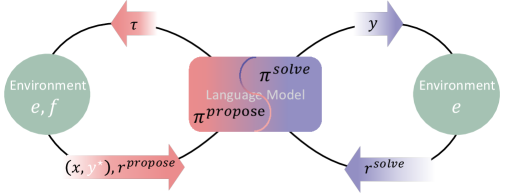
技术框架:Absolute Zero Reasoner (AZR) 是该范式的具体实现。其整体框架包含两个主要部分:任务生成器和任务求解器。任务生成器负责提出新的推理任务,任务求解器负责解决这些任务。一个关键组件是代码执行器,它用于验证任务的正确性和答案的准确性,从而为模型提供可验证的奖励信号。整个训练过程是一个循环迭代的过程,模型不断地提出新的任务,解决这些任务,并根据代码执行器的反馈来调整自身的策略。
关键创新:最重要的技术创新点在于完全摆脱了对外部数据的依赖,实现了一种纯粹的自监督学习范式。与现有方法相比,AZR不需要任何人工标注的数据,而是通过自我博弈来学习。这种方式不仅提高了模型的可扩展性,也使得模型能够探索更广泛的学习空间。
关键设计:AZR的关键设计包括:1) 使用代码执行器作为统一的可验证奖励来源,确保学习过程的可靠性;2) 设计合适的奖励函数,鼓励模型提出具有挑战性且能够促进学习的任务;3) 使用强化学习算法来优化任务生成器和任务求解器的策略;4) 探索不同的模型规模和模型类别,验证AZR的通用性。
🖼️ 关键图片

📊 实验亮点
AZR在编码和数学推理任务上取得了SOTA性能,超越了依赖数万个人工标注样本的现有零样本模型。具体而言,在某些编码任务上,AZR的性能提升超过10%。实验还表明,AZR可以有效地应用于不同的模型规模,并与各种模型类别兼容,证明了该方法的通用性和可扩展性。
🎯 应用场景
Absolute Zero范式具有广泛的应用前景,可用于训练各种智能体,例如代码生成、数学推理、科学发现等。该方法尤其适用于缺乏高质量标注数据的领域,可以降低对人工干预的依赖,加速AI的自主学习和发展。未来,该技术有望应用于通用人工智能的研发,构建能够自主学习和进化的智能系统。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.