Unraveling the Rainbow: can value-based methods schedule?
作者: Arthur Corrêa, Alexandre Jesus, Paulo Nascimento, Cristóvão Silva, Samuel Moniz
分类: cs.LG
发布日期: 2025-05-06 (更新: 2025-11-27)
🔗 代码/项目: GITHUB
💡 一句话要点
探索价值方法在调度问题中的潜力:价值学习算法在Job-Shop调度问题中表现优异
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 Job-Shop调度 柔性Job-Shop调度 价值学习 组合优化
📋 核心要点
- 组合优化领域长期偏好策略梯度算法,忽略了基于价值的深度强化学习算法在Job-Shop调度等问题上的潜力。
- 该研究探索了价值学习算法在Job-Shop调度问题中的应用,旨在证明其性能可以与策略梯度算法相媲美甚至超越。
- 实验结果表明,价值学习算法在收敛稳定性、泛化能力等方面优于策略梯度算法,尤其是在解决大规模或结构不同的实例时。
📝 摘要(中文)
本文针对Job-Shop调度问题和柔性Job-Shop调度问题,对几种深度强化学习算法进行了广泛的实证研究。深度强化学习算法大致分为两类:策略梯度和基于价值的方法。虽然基于价值的算法在雅达利学习环境等领域取得了显著成功,但组合优化领域主要倾向于策略梯度算法,往往忽略了基于价值的算法的潜力。研究结果表明,与策略梯度算法相比,基于价值的算法表现出更低的方差和更稳定的收敛曲线。此外,它们在跨规模和跨分布泛化方面表现更出色,即能有效地解决比训练中遇到的实例更大或结构上不同的实例。最后,我们的分析还表明,每类算法的相对性能可能取决于问题的结构属性,例如问题的灵活性和实例大小。总的来说,我们的发现挑战了策略梯度算法本质上优于组合优化的普遍假设。我们表明,基于价值的算法可以匹配甚至超过策略梯度算法的性能,表明它们值得组合优化社区更多关注。我们的代码已在https://github.com/AJ-Correa/Unraveling-the-Rainbow上公开。
🔬 方法详解
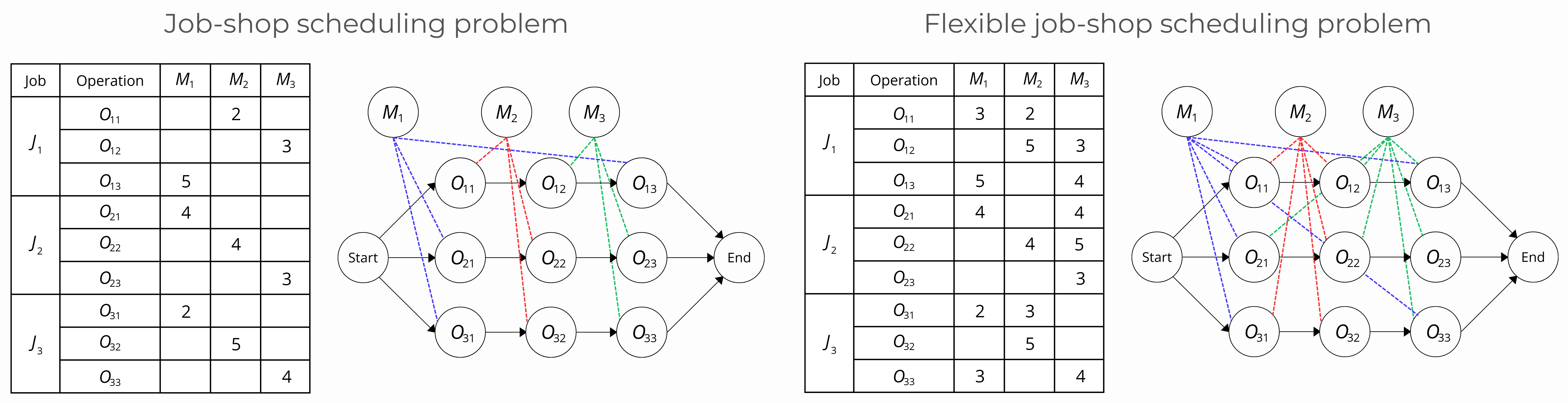
问题定义:论文旨在解决Job-Shop调度问题(JSP)和柔性Job-Shop调度问题(FJSP),这是两个具有重要工业应用价值的组合优化问题。现有方法,特别是策略梯度方法,虽然被广泛使用,但在收敛稳定性、泛化能力等方面存在不足,难以有效解决大规模或结构差异大的实例。
核心思路:论文的核心思路是探索基于价值的深度强化学习算法在解决JSP和FJSP问题上的潜力。作者认为,价值学习算法在其他领域已经取得了成功,因此有理由相信它们也能在组合优化问题中发挥作用。通过实验对比,证明价值学习算法在某些方面优于策略梯度算法。
技术框架:论文采用深度强化学习框架,将JSP和FJSP问题建模为马尔可夫决策过程(MDP)。具体流程包括:1)状态表示:将调度问题的状态编码为神经网络的输入;2)动作选择:基于价值函数选择下一步要执行的调度动作;3)奖励函数设计:根据调度结果的好坏给予奖励或惩罚;4)价值函数更新:使用深度神经网络逼近价值函数,并通过强化学习算法进行更新。
关键创新:论文的关键创新在于挑战了组合优化领域对策略梯度算法的固有偏好,并证明了基于价值的算法在JSP和FJSP问题上具有竞争力。此外,论文还深入分析了不同算法在不同问题结构下的性能差异,为算法选择提供了指导。
关键设计:论文使用了多种深度强化学习算法,包括Rainbow等基于价值的算法。具体的技术细节包括:1)神经网络结构:使用了多层感知机(MLP)或卷积神经网络(CNN)来逼近价值函数;2)奖励函数设计:根据问题的具体目标(例如,最小化完工时间)设计奖励函数;3)探索-利用策略:采用了ε-greedy或Boltzmann探索策略来平衡探索和利用;4)训练过程:使用经验回放和目标网络等技术来稳定训练过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于价值的算法(如Rainbow)在JSP和FJSP问题上表现出更低的方差和更稳定的收敛曲线,优于策略梯度算法。更重要的是,价值学习算法在跨规模和跨分布泛化方面表现更出色,能够有效解决比训练实例更大或结构不同的实例。这些结果挑战了策略梯度算法在组合优化领域的主导地位。
🎯 应用场景
该研究成果可应用于制造业、物流、交通运输等领域的调度优化问题。通过使用基于价值的深度强化学习算法,可以更有效地解决复杂的调度问题,提高生产效率、降低成本,并实现资源的优化配置。未来的研究可以进一步探索价值学习算法在其他组合优化问题中的应用,并开发更高效的算法和框架。
📄 摘要(原文)
In this work, we conduct an extensive empirical study of several deep reinforcement learning algorithms on two challenging combinatorial optimization problems: the job-shop and flexible job-shop scheduling problems, both fundamental challenges with multiple industrial applications. Broadly, deep reinforcement learning algorithms fall into two categories: policy-gradient and value-based. While value-based algorithms have achieved notable success in domains such as the Arcade Learning Environment, the combinatorial optimization community has predominantly favored policy-gradient algorithms, often overlooking the potential of value-based alternatives. From our results, value-based algorithms demonstrated a lower variance and a more stable convergence profile compared to policy-gradient ones. Moreover, they achieved superior cross-size and cross-distribution generalization, that is, effectively solving instances that are substantially larger or structurally distinct from those seen during training. Finally, our analysis also suggests that the relative performance of each category of algorithms may be dependent on structural properties of the problem, such as problem flexibility and instance size. Overall, our findings challenge the prevailing assumption that policy-gradient algorithms are inherently superior for combinatorial optimization. We show instead that value-based algorithms can match or even surpass the performance of policy-gradient algorithms, suggesting that they deserve greater attention from the combinatorial optimization community. Our code is openly available at: https://github.com/AJ-Correa/Unraveling-the-Rainbow