Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
作者: Kazuki Fujii, Yukito Tajima, Sakae Mizuki, Hinari Shimada, Taihei Shiotani, Koshiro Saito, Masanari Ohi, Masaki Kawamura, Taishi Nakamura, Takumi Okamoto, Shigeki Ishida, Kakeru Hattori, Youmi Ma, Hiroya Takamura, Rio Yokota, Naoaki Okazaki
分类: cs.LG, cs.AI
发布日期: 2025-05-05 (更新: 2025-07-04)
💡 一句话要点
重写预训练数据提升LLM在数学和代码领域的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练数据 数据增强 代码生成 数学推理 LLM重写 SwallowCode SwallowMath
📋 核心要点
- 现有LLM在代码和数学推理能力上受限于预训练数据的质量,低质量数据阻碍了模型性能的进一步提升。
- 论文提出一种“转换并保留”的方法,通过重写现有数据,而非简单过滤,来提升预训练数据的质量和效用。
- 实验表明,使用重写后的SwallowCode和SwallowMath数据集进行预训练,显著提升了LLM在代码生成和数学问题解决上的性能。
📝 摘要(中文)
大型语言模型(LLM)在程序合成和数学推理方面的性能受到其预训练语料库质量的根本限制。本文介绍了两个在Llama 3.3 Community License下开源的数据集,通过系统地重写公共数据,显著提升了LLM的性能。SwallowCode(约161亿tokens)通过一种新颖的四阶段流程改进了来自The-Stack-v2的Python代码片段:语法验证、基于pylint的风格过滤,以及一个两阶段的LLM重写过程,该过程强制执行风格一致性并将代码片段转换为自包含、算法高效的示例。与依赖于排除性过滤或有限转换的先前方法不同,我们的转换并保留方法升级了低质量代码,从而最大化了数据效用。SwallowMath(约23亿tokens)通过删除样板、恢复上下文以及将解决方案重新格式化为简洁的逐步解释,增强了Finemath-4+。在固定的500亿token训练预算内,使用SwallowCode对Llama-3.1-8B进行持续预训练,与Stack-Edu相比,在HumanEval上pass@1提高了+17.0,在HumanEval+上提高了+17.7,超过了基线模型的代码生成能力。同样,替换SwallowMath在GSM8K上产生了+12.4的准确率,在MATH上产生了+7.6的准确率。消融研究证实,每个pipeline阶段都有增量贡献,其中重写带来的收益最大。所有数据集、提示和检查点均已公开,从而实现了可重复的研究并推进了用于专门领域的LLM预训练。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在程序合成和数学推理任务中,由于预训练数据质量不高而导致的性能瓶颈问题。现有方法通常采用过滤的方式去除低质量数据,但这种方式会损失大量数据,降低训练效率。
核心思路:论文的核心思路是“转换并保留”,即不直接丢弃低质量数据,而是通过一系列的重写和优化步骤,将低质量数据转化为高质量数据,从而提升预训练数据的整体质量和效用。这种方法可以最大限度地利用现有数据,避免数据浪费。
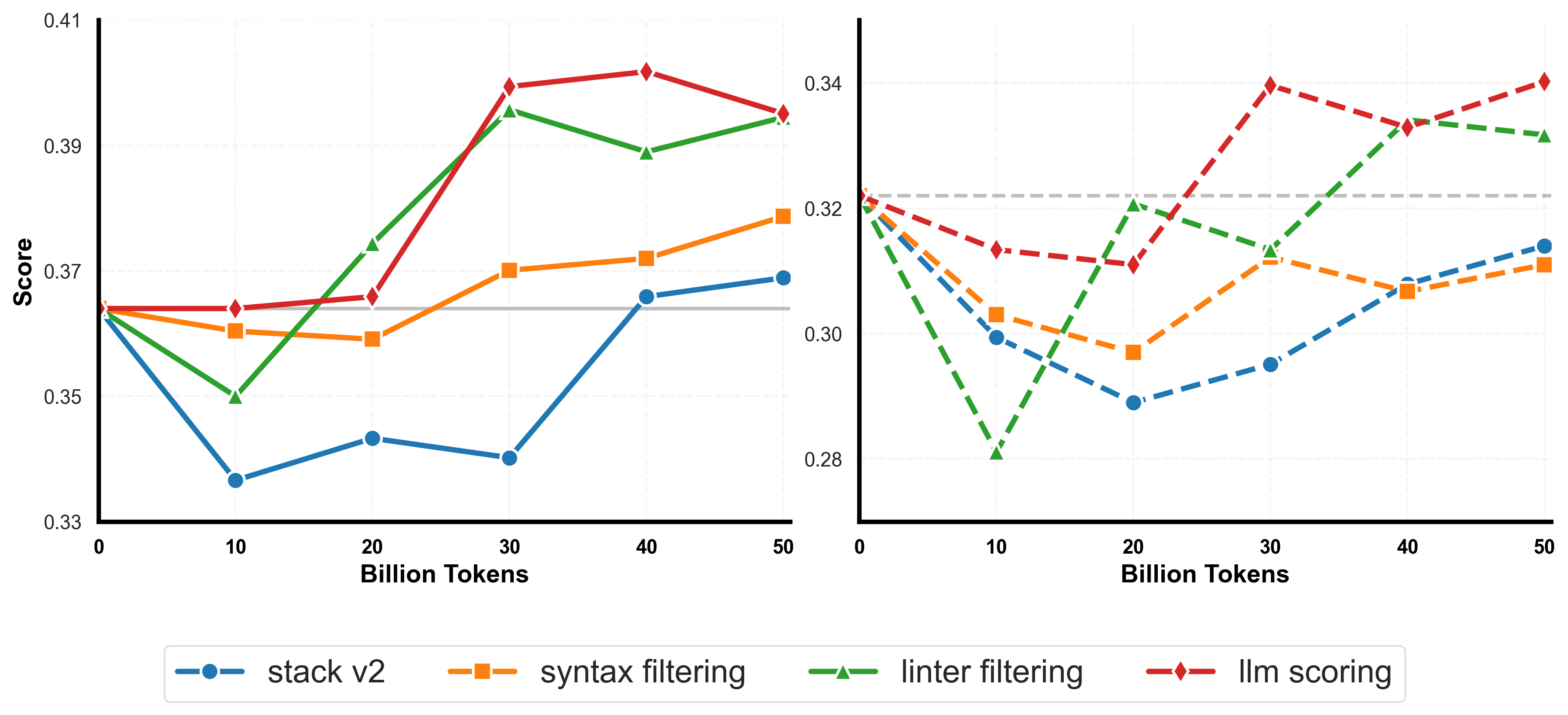
技术框架:论文提出了两个数据集的构建流程:SwallowCode和SwallowMath。SwallowCode的构建包含四个阶段:1) 语法验证,确保代码片段的语法正确性;2) 基于pylint的风格过滤,统一代码风格;3) LLM重写(第一阶段),强制风格一致性;4) LLM重写(第二阶段),将代码片段转换为自包含、算法高效的示例。SwallowMath的构建包括:删除样板代码、恢复上下文信息、将解决方案重新格式化为简洁的逐步解释。
关键创新:论文的关键创新在于“转换并保留”的数据增强策略,它与传统的过滤方法形成对比。通过LLM驱动的重写过程,低质量的代码和数学问题解决方案被转化为高质量的训练样本,从而更有效地提升了LLM的性能。此外,针对代码和数学问题,设计了不同的重写流程,体现了领域针对性。
关键设计:SwallowCode的LLM重写阶段使用了特定的prompt工程来指导LLM进行代码风格统一和代码优化。SwallowMath的重写过程则侧重于恢复问题的上下文信息,并生成清晰的逐步解决方案。具体prompt的设计细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片
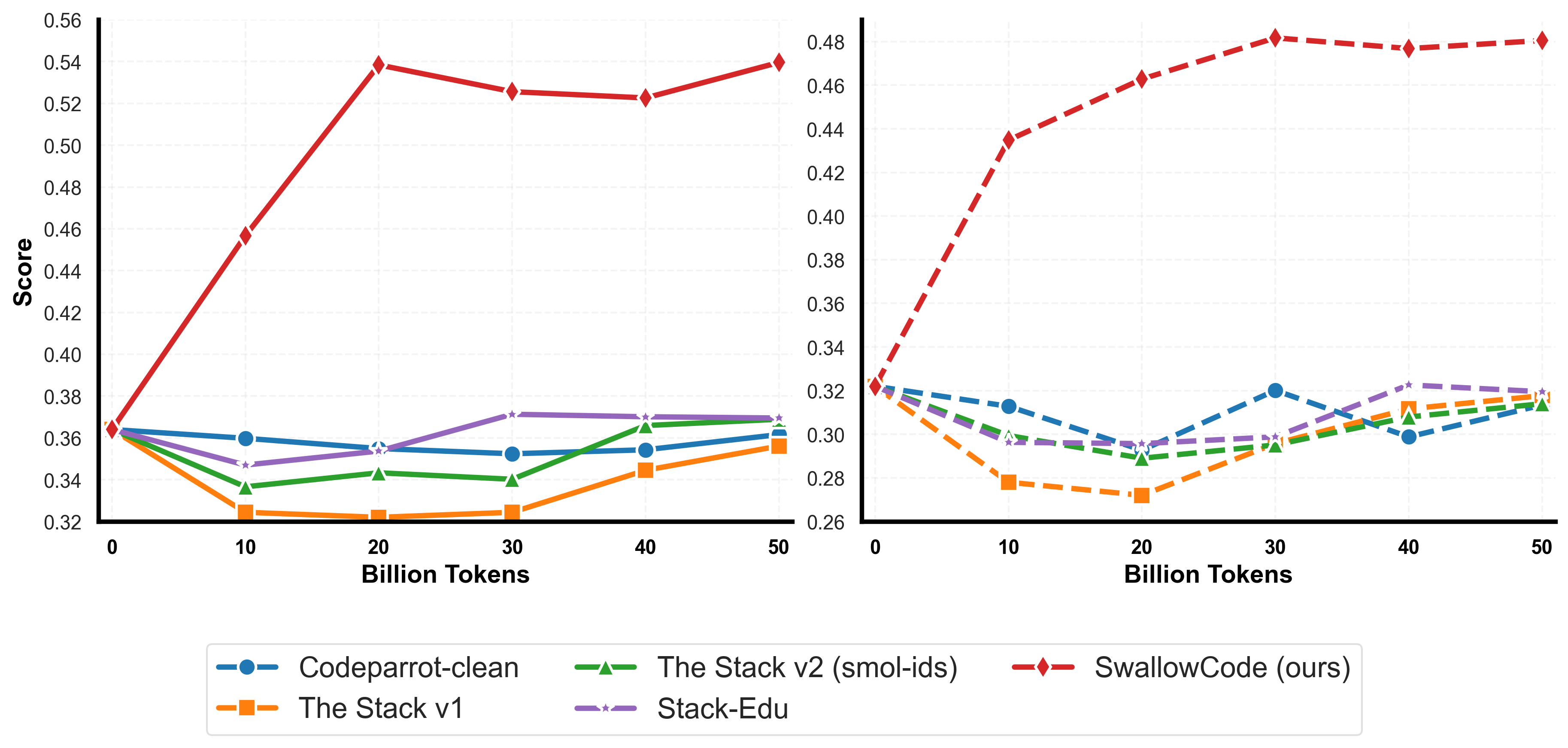

📊 实验亮点
实验结果表明,使用SwallowCode对Llama-3.1-8B进行持续预训练,在HumanEval和HumanEval+上的pass@1分别提高了+17.0和+17.7,显著超过了使用Stack-Edu的基线模型。同样,使用SwallowMath在GSM8K和MATH数据集上分别获得了+12.4和+7.6的准确率提升。这些结果充分证明了重写预训练数据对提升LLM性能的有效性。
🎯 应用场景
该研究成果可应用于提升各种LLM在特定领域的性能,例如软件开发、数学教育等。通过构建高质量的领域特定预训练数据集,可以显著提高LLM在这些领域的应用能力。此外,该研究提出的数据重写方法也可以推广到其他领域,为LLM的预训练提供更有效的数据准备方案。
📄 摘要(原文)
The performance of large language models (LLMs) in program synthesis and mathematical reasoning is fundamentally limited by the quality of their pre-training corpora. We introduce two openly licensed datasets, released under the Llama 3.3 Community License, that significantly enhance LLM performance by systematically rewriting public data. SwallowCode (approximately 16.1 billion tokens) refines Python snippets from The-Stack-v2 through a novel four-stage pipeline: syntax validation, pylint-based style filtering, and a two-stage LLM rewriting process that enforces style conformity and transforms snippets into self-contained, algorithmically efficient examples. Unlike prior methods that rely on exclusionary filtering or limited transformations, our transform-and-retain approach upgrades low-quality code, maximizing data utility. SwallowMath (approximately 2.3 billion tokens) enhances Finemath-4+ by removing boilerplate, restoring context, and reformatting solutions into concise, step-by-step explanations. Within a fixed 50 billion token training budget, continual pre-training of Llama-3.1-8B with SwallowCode boosts pass@1 by +17.0 on HumanEval and +17.7 on HumanEval+ compared to Stack-Edu, surpassing the baseline model's code generation capabilities. Similarly, substituting SwallowMath yields +12.4 accuracy on GSM8K and +7.6 on MATH. Ablation studies confirm that each pipeline stage contributes incrementally, with rewriting delivering the largest gains. All datasets, prompts, and checkpoints are publicly available, enabling reproducible research and advancing LLM pre-training for specialized domains.