Enhancing Chemical Reaction and Retrosynthesis Prediction with Large Language Model and Dual-task Learning
作者: Xuan Lin, Qingrui Liu, Hongxin Xiang, Daojian Zeng, Xiangxiang Zeng
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-05
备注: Accepted for publication at IJCAI 2025
💡 一句话要点
ChemDual:利用大语言模型和双任务学习提升化学反应和逆合成预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 化学反应预测 逆合成预测 大型语言模型 双任务学习 药物设计 化学信息学 指令数据集
📋 核心要点
- 现有方法缺乏大规模化学合成指令数据,且忽略了反应和逆合成预测间的关联。
- ChemDual将反应和逆合成视为重组和碎片过程,构建大规模指令数据集并采用双任务学习。
- 实验表明ChemDual在反应和逆合成预测上达到SOTA,并生成具有良好蛋白质结合亲和力的化合物。
📝 摘要(中文)
化学反应和逆合成预测是药物发现中的基础任务。近年来,大型语言模型(LLMs)在许多领域展现出潜力。然而,直接将LLMs应用于这些任务面临两个主要挑战:(i)缺乏大规模的化学合成相关指令数据集;(ii)忽略了反应和逆合成预测之间紧密的关联性。为了应对这些挑战,我们提出了ChemDual,一个用于精确化学合成的新型LLM框架。具体而言,考虑到反应和逆合成数据获取的高成本,ChemDual将分子的反应和逆合成视为相关的重组和碎片过程,并构建了一个包含440万条指令的大规模数据集。此外,ChemDual引入了一个增强的LLaMA模型,配备了多尺度分词器和双任务学习策略,以联合优化重组和碎片过程,以及反应和逆合成预测任务。在Mol-Instruction和USPTO-50K数据集上的大量实验表明,ChemDual在反应和逆合成预测方面均达到了最先进的性能,优于现有的传统单任务方法和通用开源LLMs。通过分子对接分析,ChemDual生成了具有多样性和强大蛋白质结合亲和力的化合物,进一步突显了其在药物设计中的强大潜力。
🔬 方法详解
问题定义:论文旨在解决化学反应和逆合成预测任务中,现有方法依赖于小规模数据集以及忽略反应和逆合成之间关联性的问题。现有方法通常将这两个任务视为独立的单任务进行处理,未能充分利用它们之间的互补信息,导致预测精度受限。此外,缺乏大规模的化学合成相关指令数据集也限制了大型语言模型在该领域的应用潜力。
核心思路:ChemDual的核心思路是将化学反应和逆合成视为一个统一的重组和碎片过程。反应可以看作是分子片段的重组,而逆合成则是将目标分子分解为更小的片段。通过将这两个过程联系起来,并利用双任务学习策略,模型可以同时学习反应和逆合成的知识,从而提高预测的准确性和效率。
技术框架:ChemDual框架主要包含两个关键组成部分:大规模指令数据集的构建和增强的LLaMA模型。首先,论文构建了一个包含440万条指令的大规模数据集,涵盖了反应和逆合成的各种情况。其次,论文提出了一个增强的LLaMA模型,该模型配备了多尺度分词器和双任务学习策略。多尺度分词器可以更好地处理化学分子的复杂结构,而双任务学习策略则可以同时优化反应和逆合成预测任务。
关键创新:ChemDual的关键创新在于其双任务学习策略和大规模指令数据集的构建。通过将反应和逆合成视为一个统一的过程,并利用双任务学习策略,模型可以更好地学习这两个任务之间的关联性,从而提高预测的准确性。此外,大规模指令数据集的构建为大型语言模型在该领域的应用提供了数据基础。
关键设计:ChemDual采用了增强的LLaMA模型,并对其进行了以下关键设计:(1) 多尺度分词器:用于处理化学分子的复杂结构,提高模型对分子结构的理解能力。(2) 双任务学习策略:同时优化反应和逆合成预测任务,利用两个任务之间的互补信息。(3) 损失函数:采用交叉熵损失函数来衡量预测结果与真实结果之间的差异,并通过梯度下降算法来优化模型参数。具体的参数设置和网络结构细节在论文中有更详细的描述(未知)。
🖼️ 关键图片
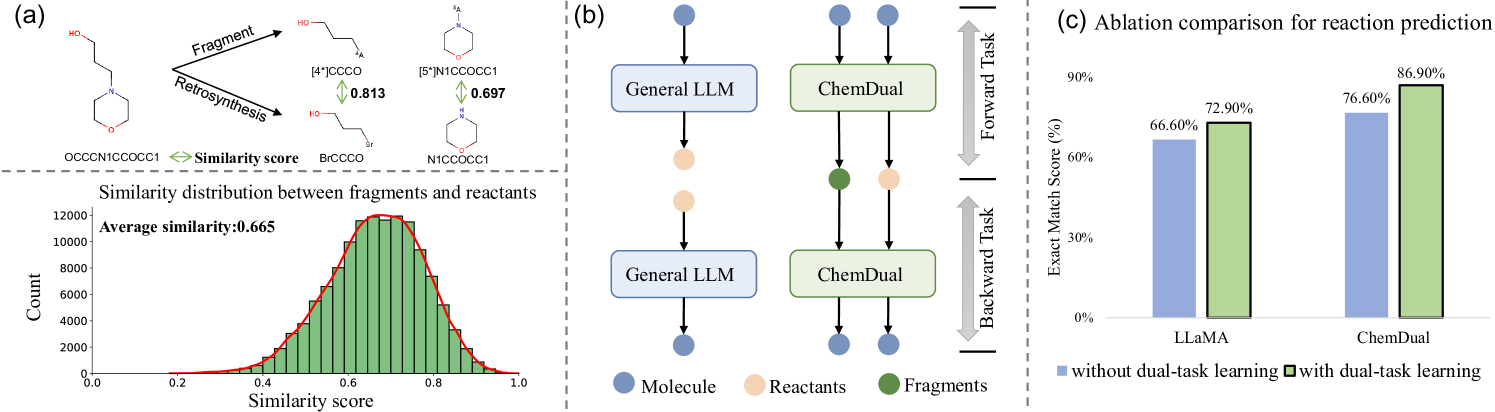
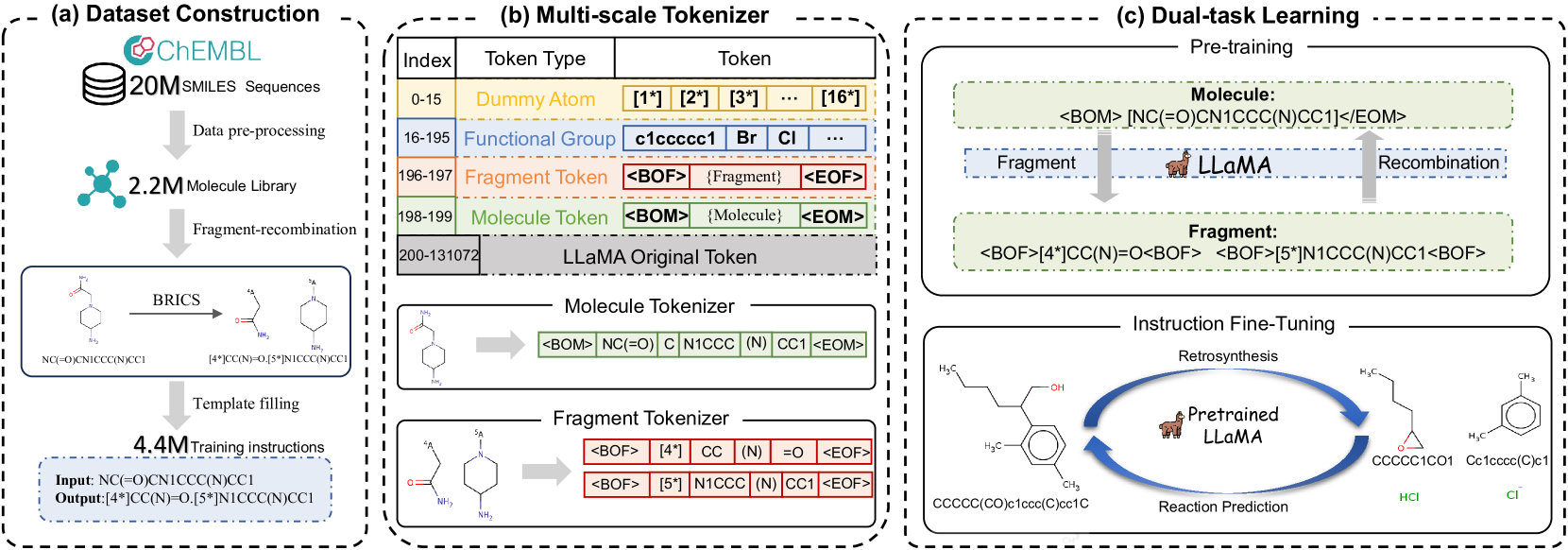

📊 实验亮点
ChemDual在Mol-Instruction和USPTO-50K数据集上取得了显著的性能提升,超越了现有的单任务方法和通用开源LLMs。具体性能数据和提升幅度在论文中有详细展示(未知)。此外,ChemDual生成的化合物具有多样性和强大的蛋白质结合亲和力,表明其在药物设计方面具有巨大的潜力。
🎯 应用场景
ChemDual在药物设计领域具有广泛的应用前景。它可以用于预测化学反应的产物,从而加速新药的合成过程。此外,ChemDual还可以用于逆合成分析,帮助化学家找到合成目标分子的最佳路径。通过分子对接分析,ChemDual还可以生成具有良好蛋白质结合亲和力的化合物,为新药的发现提供有价值的线索。该研究的成果有望加速药物研发进程,降低研发成本。
📄 摘要(原文)
Chemical reaction and retrosynthesis prediction are fundamental tasks in drug discovery. Recently, large language models (LLMs) have shown potential in many domains. However, directly applying LLMs to these tasks faces two major challenges: (i) lacking a large-scale chemical synthesis-related instruction dataset; (ii) ignoring the close correlation between reaction and retrosynthesis prediction for the existing fine-tuning strategies. To address these challenges, we propose ChemDual, a novel LLM framework for accurate chemical synthesis. Specifically, considering the high cost of data acquisition for reaction and retrosynthesis, ChemDual regards the reaction-and-retrosynthesis of molecules as a related recombination-and-fragmentation process and constructs a large-scale of 4.4 million instruction dataset. Furthermore, ChemDual introduces an enhanced LLaMA, equipped with a multi-scale tokenizer and dual-task learning strategy, to jointly optimize the process of recombination and fragmentation as well as the tasks between reaction and retrosynthesis prediction. Extensive experiments on Mol-Instruction and USPTO-50K datasets demonstrate that ChemDual achieves state-of-the-art performance in both predictions of reaction and retrosynthesis, outperforming the existing conventional single-task approaches and the general open-source LLMs. Through molecular docking analysis, ChemDual generates compounds with diverse and strong protein binding affinity, further highlighting its strong potential in drug design.